 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Variability Effects On LLM Code Generation
Jun 11, 2025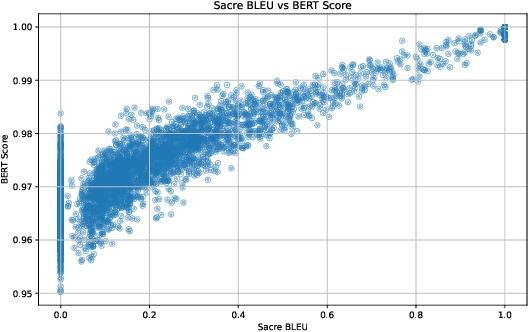



Code generation is one of the most active areas of application of Large Language Models (LLMs). While LLMs lower barriers to writing code and accelerate development process, the overall quality of generated programs depends on the quality of given prompts. Specifically, functionality and quality of generated code can be sensitive to user's background and familiarity with software development. It is therefore important to quantify LLM's sensitivity to variations in the input. To this end we propose a synthetic evaluation pipeline for code generation with LLMs, as well as a systematic persona-based evaluation approach to expose qualitative differences of LLM responses dependent on prospective user background. Both proposed methods are completely independent from specific programming tasks and LLMs, and thus are widely applicable. We provide experimental evidence illustrating utility of our methods and share our code for the benefit of the community.
LLM Performance for Code Generation on Noisy Tasks
May 29, 2025

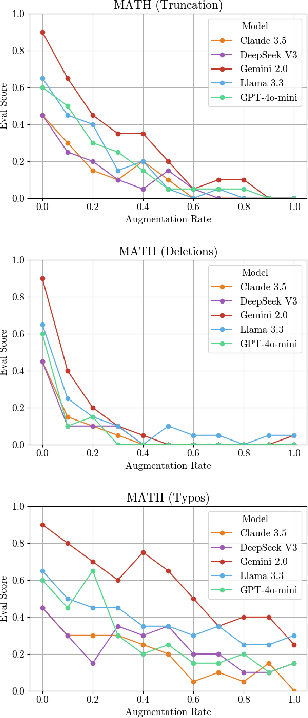

This paper investigates the ability of large language models (LLMs) to recognise and solve tasks which have been obfuscated beyond recognition. Focusing on competitive programming and benchmark tasks (LeetCode and MATH), we compare performance across multiple models and obfuscation methods, such as noise and redaction. We demonstrate that all evaluated LLMs can solve tasks obfuscated to a level where the text would be unintelligible to human readers, and does not contain key pieces of instruction or context. We introduce the concept of eager pattern matching to describe this behaviour, which is not observed in tasks published after the models' knowledge cutoff date, indicating strong memorisation or overfitting to training data, rather than legitimate reasoning about the presented problem. We report empirical evidence of distinct performance decay patterns between contaminated and unseen datasets. We discuss the implications for benchmarking and evaluations of model behaviour, arguing for caution when designing experiments using standard datasets. We also propose measuring the decay of performance under obfuscation as a possible strategy for detecting dataset contamination and highlighting potential safety risks and interpretability issues for automated software systems.
The Systems Engineering Approach in Times of Large Language Models
Nov 13, 2024



Using Large Language Models (LLMs) to address critical societal problems requires adopting this novel technology into socio-technical systems. However, the complexity of such systems and the nature of LLMs challenge such a vision. It is unlikely that the solution to such challenges will come from the Artificial Intelligence (AI) community itself. Instead, the Systems Engineering approach is better equipped to facilitate the adoption of LLMs by prioritising the problems and their context before any other aspects. This paper introduces the challenges LLMs generate and surveys systems research efforts for engineering AI-based systems. We reveal how the systems engineering principles have supported addressing similar issues to the ones LLMs pose and discuss our findings to provide future directions for adopting LLMs.
Self-sustaining Software Systems (S4): Towards Improved Interpretability and Adaptation
Jan 21, 2024
Software systems impact society at different levels as they pervasively solve real-world problems. Modern software systems are often so sophisticated that their complexity exceeds the limits of human comprehension. These systems must respond to changing goals, dynamic data, unexpected failures, and security threats, among other variable factors in real-world environments. Systems' complexity challenges their interpretability and requires autonomous responses to dynamic changes. Two main research areas explore autonomous systems' responses: evolutionary computing and autonomic computing. Evolutionary computing focuses on software improvement based on iterative modifications to the source code. Autonomic computing focuses on optimising systems' performance by changing their structure, behaviour, or environment variables. Approaches from both areas rely on feedback loops that accumulate knowledge from the system interactions to inform autonomous decision-making. However, this knowledge is often limited, constraining the systems' interpretability and adaptability. This paper proposes a new concept for interpretable and adaptable software systems: self-sustaining software systems (S4). S4 builds knowledge loops between all available knowledge sources that define modern software systems to improve their interpretability and adaptability. This paper introduces and discusses the S4 concept.
Real-world Machine Learning Systems: A survey from a Data-Oriented Architecture Perspective
Feb 09, 2023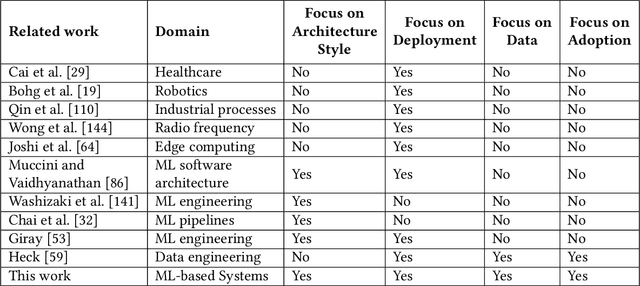
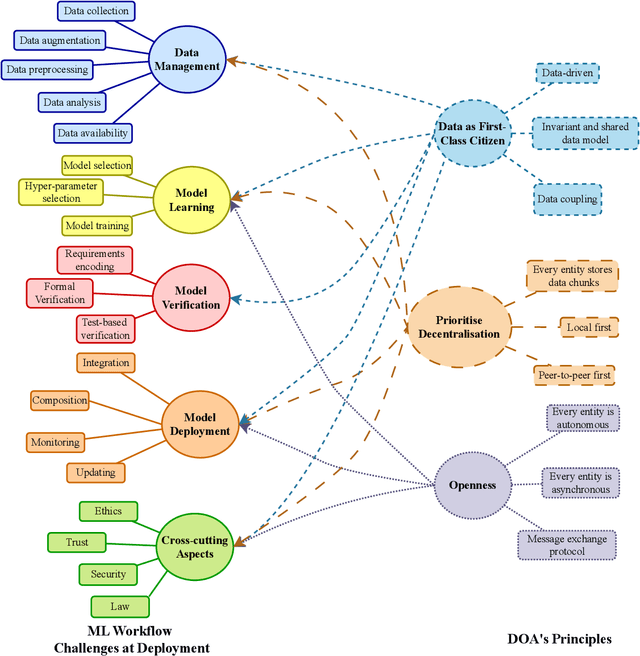


With the upsurge of interest in artificial intelligence machine learning (ML) algorithms, originally developed in academic environments, are now being deployed as parts of real-life systems that deal with large amounts of heterogeneous, dynamic, and high-dimensional data. Deployment of ML methods in real life is prone to challenges across the whole system life-cycle from data management to systems deployment, monitoring, and maintenance. Data-Oriented Architecture (DOA) is an emerging software engineering paradigm that has the potential to mitigate these challenges by proposing a set of principles to create data-driven, loosely coupled, decentralised, and open systems. However DOA as a concept is not widespread yet, and there is no common understanding of how it can be realised in practice. This review addresses that problem by contextualising the principles that underpin the DOA paradigm through the ML system challenges. We explore the extent to which current architectures of ML-based real-world systems have implemented the DOA principles. We also formulate open research challenges and directions for further development of the DOA paradigm.
An Empirical Evaluation of Flow Based Programming in the Machine Learning Deployment Context
Apr 27, 2022


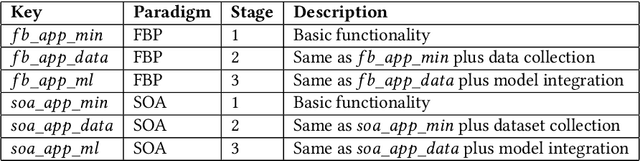
As use of data driven technologies spreads, software engineers are more often faced with the task of solving a business problem using data-driven methods such as machine learning (ML) algorithms. Deployment of ML within large software systems brings new challenges that are not addressed by standard engineering practices and as a result businesses observe high rate of ML deployment project failures. Data Oriented Architecture (DOA) is an emerging approach that can support data scientists and software developers when addressing such challenges. However, there is a lack of clarity about how DOA systems should be implemented in practice. This paper proposes to consider Flow-Based Programming (FBP) as a paradigm for creating DOA applications. We empirically evaluate FBP in the context of ML deployment on four applications that represent typical data science projects. We use Service Oriented Architecture (SOA) as a baseline for comparison. Evaluation is done with respect to different application domains, ML deployment stages, and code quality metrics. Results reveal that FBP is a suitable paradigm for data collection and data science tasks, and is able to simplify data collection and discovery when compared with SOA. We discuss the advantages of FBP as well as the gaps that need to be addressed to increase FBP adoption as a standard design paradigm for DOA.
Exploring the potential of flow-based programming for machine learning deployment in comparison with service-oriented architectures
Aug 09, 2021



Despite huge successes reported by the field of machine learning, such as speech assistants or self-driving cars, businesses still observe very high failure rate when it comes to deployment of ML in production. We argue that part of the reason is infrastructure that was not designed for activities around data collection and analysis. We propose to consider flow-based programming with data streams as an alternative to commonly used service-oriented architectures for building software applications. To compare flow-based programming with the widespread service-oriented approach, we develop a data processing application, and formulate two subsequent ML-related tasks that constitute a complete cycle of ML deployment while allowing us to assess characteristics of each programming paradigm in the ML context. Employing both code metrics and empirical observations, we show that when it comes to ML deployment each paradigm has certain advantages and drawbacks. Our main conclusion is that while FBP shows great potential for providing infrastructural benefits for deployment of machine learning, it requires a lot of boilerplate code to define and manipulate the dataflow graph. We believe that with better developer tools in place this problem can be alleviated, establishing FBP as a strong alternative to currently prevalent SOA-driven software design approach. Additionally, we provide an insight into the trend of prioritising model development over data quality management.
WasteNet: Waste Classification at the Edge for Smart Bins
Jun 10, 2020

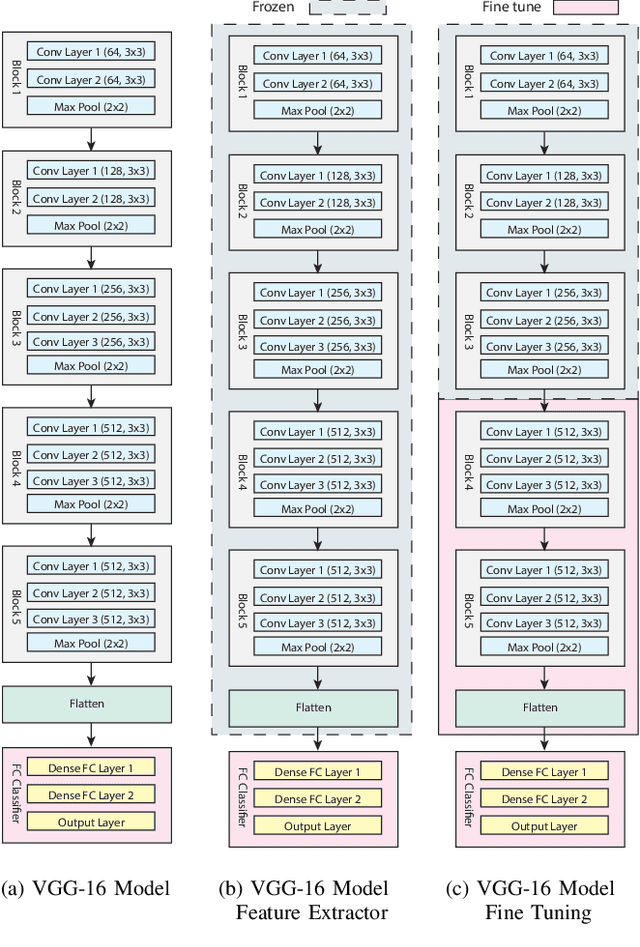
Smart Bins have become popular in smart cities and campuses around the world. These bins have a compaction mechanism that increases the bins' capacity as well as automated real-time collection notifications. In this paper, we propose WasteNet, a waste classification model based on convolutional neural networks that can be deployed on a low power device at the edge of the network, such as a Jetson Nano. The problem of segregating waste is a big challenge for many countries around the world. Automated waste classification at the edge allows for fast intelligent decisions in smart bins without needing access to the cloud. Waste is classified into six categories: paper, cardboard, glass, metal, plastic and other. Our model achieves a 97\% prediction accuracy on the test dataset. This level of classification accuracy will help to alleviate some common smart bin problems, such as recycling contamination, where different types of waste become mixed with recycling waste causing the bin to be contaminated. It also makes the bins more user friendly as citizens do not have to worry about disposing their rubbish in the correct bin as the smart bin will be able to make the decision for them.