 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-world Machine Learning Systems: A survey from a Data-Oriented Architecture Perspective
Feb 09, 2023
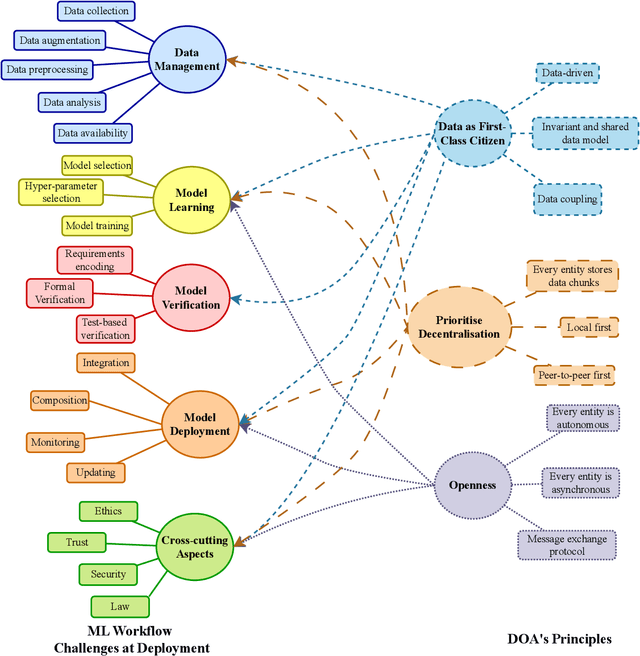


With the upsurge of interest in artificial intelligence machine learning (ML) algorithms, originally developed in academic environments, are now being deployed as parts of real-life systems that deal with large amounts of heterogeneous, dynamic, and high-dimensional data. Deployment of ML methods in real life is prone to challenges across the whole system life-cycle from data management to systems deployment, monitoring, and maintenance. Data-Oriented Architecture (DOA) is an emerging software engineering paradigm that has the potential to mitigate these challenges by proposing a set of principles to create data-driven, loosely coupled, decentralised, and open systems. However DOA as a concept is not widespread yet, and there is no common understanding of how it can be realised in practice. This review addresses that problem by contextualising the principles that underpin the DOA paradigm through the ML system challenges. We explore the extent to which current architectures of ML-based real-world systems have implemented the DOA principles. We also formulate open research challenges and directions for further development of the DOA paradigm.
Solving Schrödinger Bridges via Maximum Likelihood
Jun 17, 2021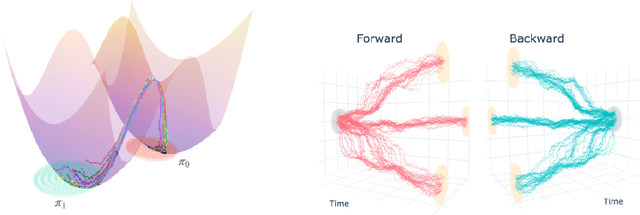

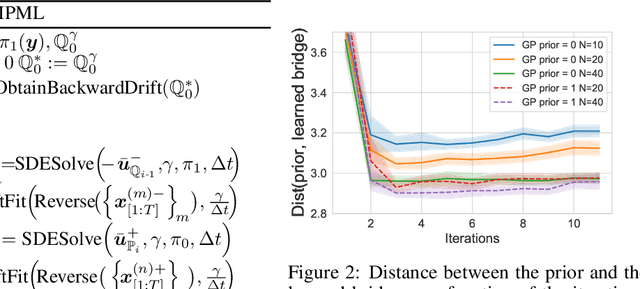
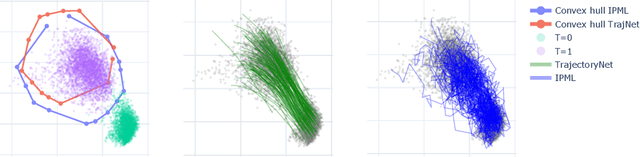
The Schr\"odinger bridge problem (SBP) finds the most likely stochastic evolution between two probability distributions given a prior stochastic evolution. As well as applications in the natural sciences, problems of this kind have important applications in machine learning such as dataset alignment and hypothesis testing. Whilst the theory behind this problem is relatively mature, scalable numerical recipes to estimate the Schr\"odinger bridge remain an active area of research. We prove an equivalence between the SBP and maximum likelihood estimation enabling direct application of successful machine learning techniques. We propose a numerical procedure to estimate SBPs using Gaussian process and demonstrate the practical usage of our approach in numerical simulations and experiments.
Recurrent Value Functions
May 23, 2019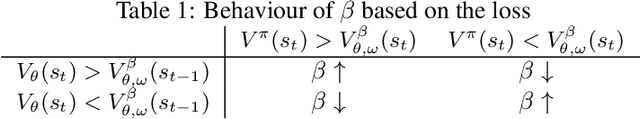
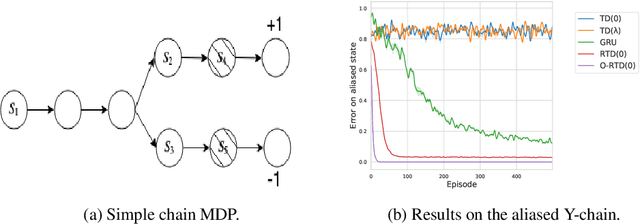
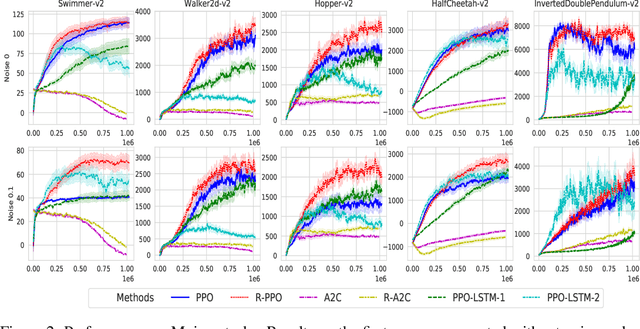
Despite recent successes in Reinforcement Learning, value-based methods often suffer from high variance hindering performance. In this paper, we illustrate this in a continuous control setting where state of the art methods perform poorly whenever sensor noise is introduced. To overcome this issue, we introduce Recurrent Value Functions (RVFs) as an alternative to estimate the value function of a state. We propose to estimate the value function of the current state using the value function of past states visited along the trajectory. Due to the nature of their formulation, RVFs have a natural way of learning an emphasis function that selectively emphasizes important states. First, we establish RVF's asymptotic convergence properties in tabular settings. We then demonstrate their robustness on a partially observable domain and continuous control tasks. Finally, we provide a qualitative interpretation of the learned emphasis function.
Temporal Regularization in Markov Decision Process
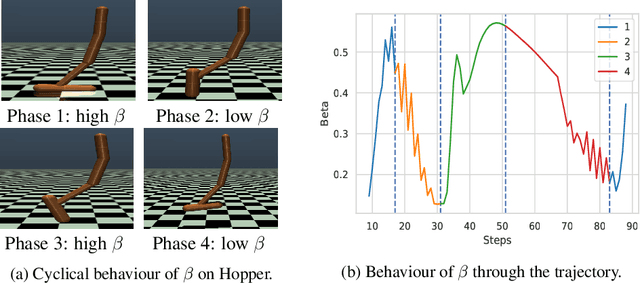
Nov 01, 2018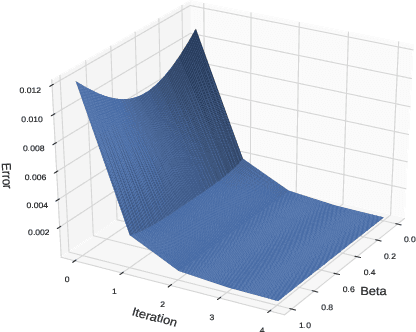
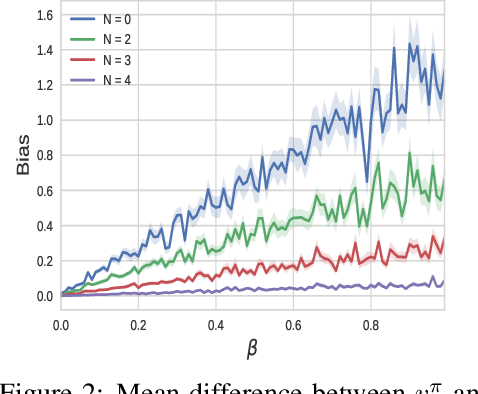
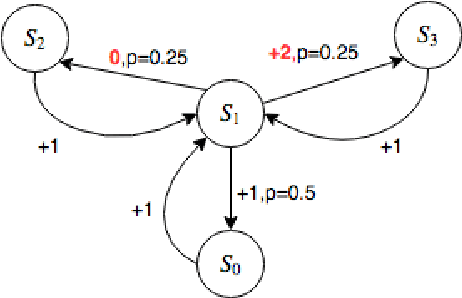
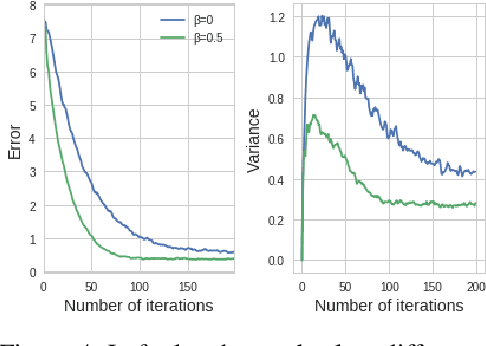
Several applications of Reinforcement Learning suffer from instability due to high variance. This is especially prevalent in high dimensional domains. Regularization is a commonly used technique in machine learning to reduce variance, at the cost of introducing some bias. Most existing regularization techniques focus on spatial (perceptual) regularization. Yet in reinforcement learning, due to the nature of the Bellman equation, there is an opportunity to also exploit temporal regularization based on smoothness in value estimates over trajectories. This paper explores a class of methods for temporal regularization. We formally characterize the bias induced by this technique using Markov chain concepts. We illustrate the various characteristics of temporal regularization via a sequence of simple discrete and continuous MDPs, and show that the technique provides improvement even in high-dimensional Atari games.
Adversarial Balancing for Causal Inference
Oct 17, 2018
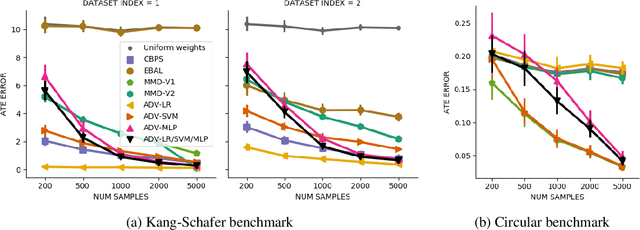
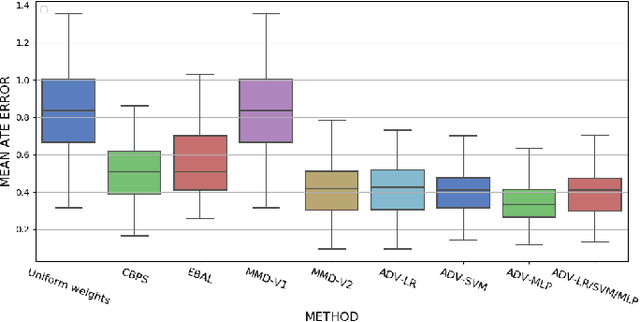
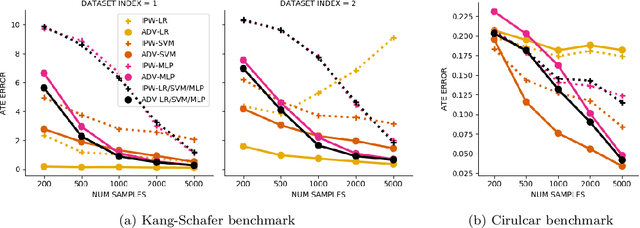
Biases in observational data pose a major challenge to estimation methods for the effect of treatments. An important technique that accounts for these biases is reweighting samples to minimize the discrepancy between treatment groups. Inverse probability weighting, a popular weighting technique, models the conditional treatment probability given covariates. However, it is overly sensitive to model misspecification and suffers from large estimation variance. Recent methods attempt to alleviate these limitations by finding weights that minimize a selected discrepancy measure between the reweighted populations. We present a new reweighting approach that uses classification error as a measure of similarity between datasets. Our proposed framework uses bi-level optimization to alternately train a discriminator to minimize classification error, and a balancing weights generator to maximize this error. This approach borrows principles from generative adversarial networks (GANs) that aim to exploit the power of classifiers for discrepancy measure estimation. We tested our approach on several benchmarks. The results of our experiments demonstrate the effectiveness and robustness of this approach in estimating causal effects under different data generating settings.
Learning Robust Features using Deep Learning for Automatic Seizure Detection
Jul 31, 2016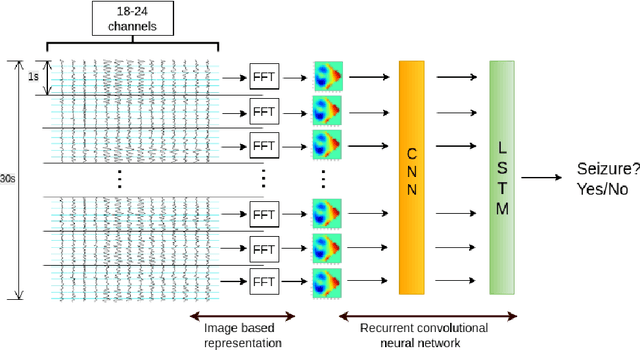
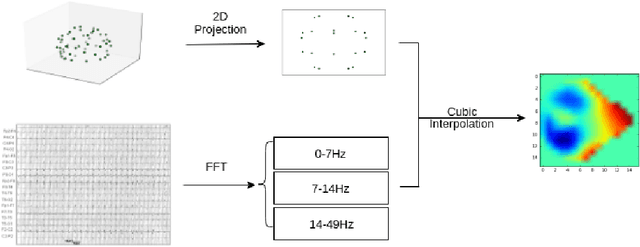
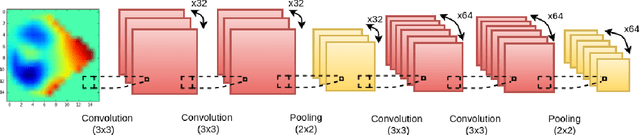
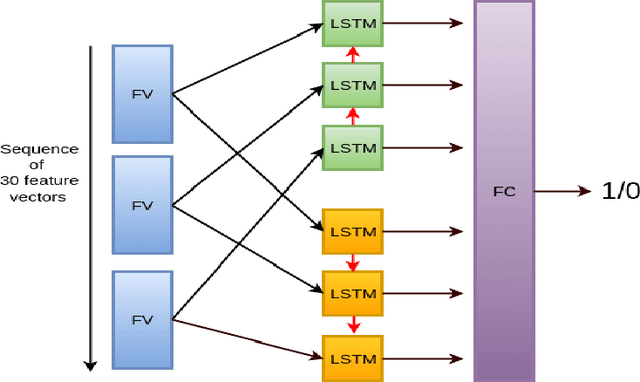
We present and evaluate the capacity of a deep neural network to learn robust features from EEG to automatically detect seizures. This is a challenging problem because seizure manifestations on EEG are extremely variable both inter- and intra-patient. By simultaneously capturing spectral, temporal and spatial information our recurrent convolutional neural network learns a general spatially invariant representation of a seizure. The proposed approach exceeds significantly previous results obtained on cross-patient classifiers both in terms of sensitivity and false positive rate. Furthermore, our model proves to be robust to missing channel and variable electrode montage.