 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Failure Modes in Vision-Language Models using RL
Apr 06, 2026Vision-language Models (VLMs), despite achieving strong performance on multimodal benchmarks, often misinterpret straightforward visual concepts that humans identify effortlessly, such as counting, spatial reasoning, and viewpoint understanding. Previous studies manually identified these weaknesses and found that they often stem from deficits in specific skills. However, such manual efforts are costly, unscalable, and subject to human bias, which often overlooks subtle details in favor of salient objects, resulting in an incomplete understanding of a model's vulnerabilities. To address these limitations, we propose a Reinforcement Learning (RL)-based framework to automatically discover the failure modes or blind spots of any candidate VLM on a given data distribution without human intervention. Our framework trains a questioner agent that adaptively generates queries based on the candidate VLM's responses to elicit incorrect answers. Our approach increases question complexity by focusing on fine-grained visual details and distinct skill compositions as training progresses, consequently identifying 36 novel failure modes in which VLMs struggle. We demonstrate the broad applicability of our framework by showcasing its generalizability across various model combinations.
Prediction and Control in Continual Reinforcement Learning
Dec 18, 2023Temporal difference (TD) learning is often used to update the estimate of the value function which is used by RL agents to extract useful policies. In this paper, we focus on value function estimation in continual reinforcement learning. We propose to decompose the value function into two components which update at different timescales: a permanent value function, which holds general knowledge that persists over time, and a transient value function, which allows quick adaptation to new situations. We establish theoretical results showing that our approach is well suited for continual learning and draw connections to the complementary learning systems (CLS) theory from neuroscience. Empirically, this approach improves performance significantly on both prediction and control problems.
Preferential Temporal Difference Learning
Jun 11, 2021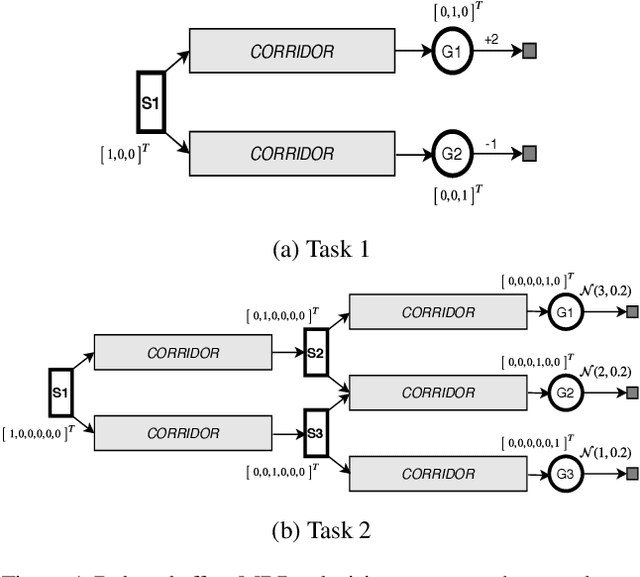
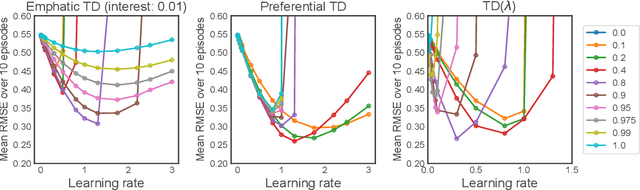
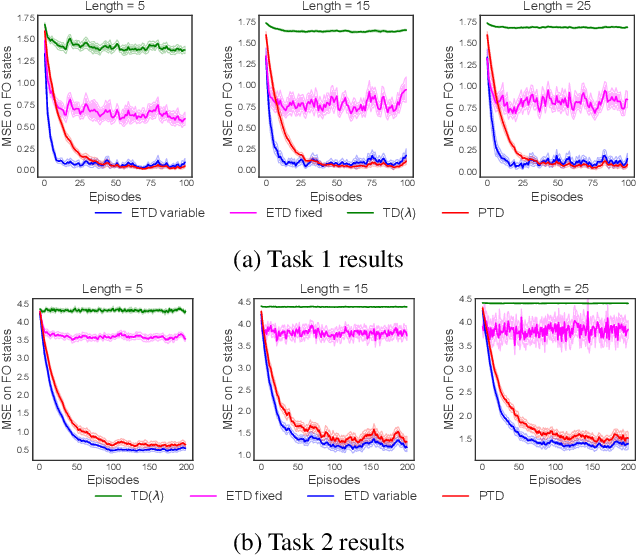
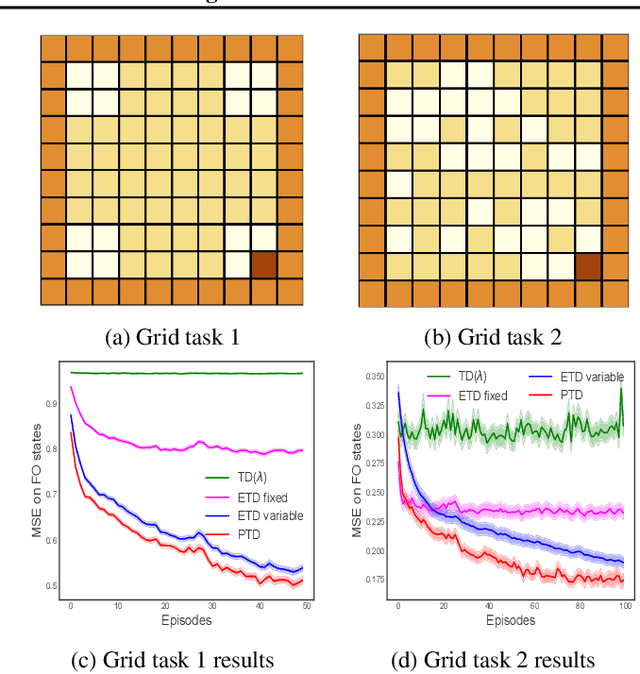
Temporal-Difference (TD) learning is a general and very useful tool for estimating the value function of a given policy, which in turn is required to find good policies. Generally speaking, TD learning updates states whenever they are visited. When the agent lands in a state, its value can be used to compute the TD-error, which is then propagated to other states. However, it may be interesting, when computing updates, to take into account other information than whether a state is visited or not. For example, some states might be more important than others (such as states which are frequently seen in a successful trajectory). Or, some states might have unreliable value estimates (for example, due to partial observability or lack of data), making their values less desirable as targets. We propose an approach to re-weighting states used in TD updates, both when they are the input and when they provide the target for the update. We prove that our approach converges with linear function approximation and illustrate its desirable empirical behaviour compared to other TD-style methods.
Recurrent Value Functions
May 23, 2019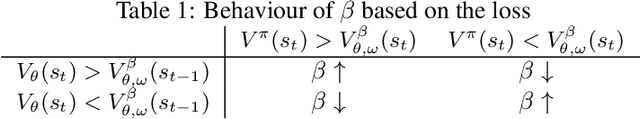
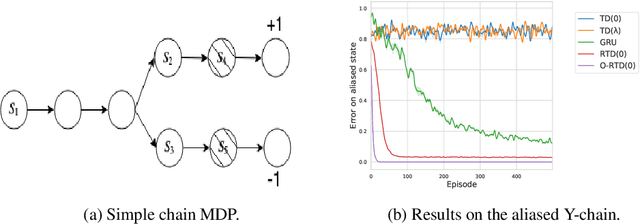
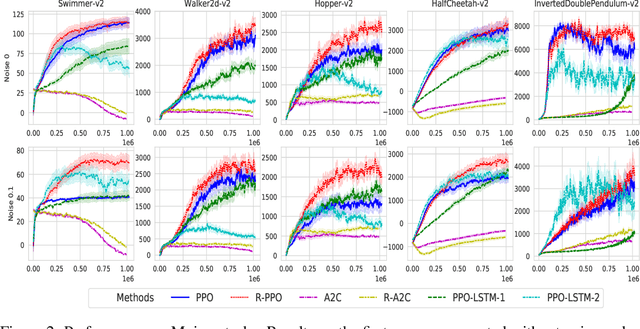
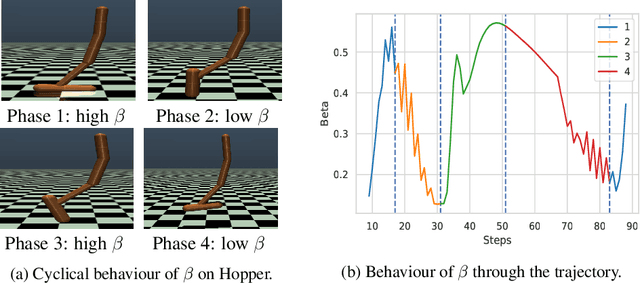
Despite recent successes in Reinforcement Learning, value-based methods often suffer from high variance hindering performance. In this paper, we illustrate this in a continuous control setting where state of the art methods perform poorly whenever sensor noise is introduced. To overcome this issue, we introduce Recurrent Value Functions (RVFs) as an alternative to estimate the value function of a state. We propose to estimate the value function of the current state using the value function of past states visited along the trajectory. Due to the nature of their formulation, RVFs have a natural way of learning an emphasis function that selectively emphasizes important states. First, we establish RVF's asymptotic convergence properties in tabular settings. We then demonstrate their robustness on a partially observable domain and continuous control tasks. Finally, we provide a qualitative interpretation of the learned emphasis function.