 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Bottleneck Layers and Skip Connections on the Generalization of Linear Denoising Autoencoders
May 30, 2025


Modern deep neural networks exhibit strong generalization even in highly overparameterized regimes. Significant progress has been made to understand this phenomenon in the context of supervised learning, but for unsupervised tasks such as denoising, several open questions remain. While some recent works have successfully characterized the test error of the linear denoising problem, they are limited to linear models (one-layer network). In this work, we focus on two-layer linear denoising autoencoders trained under gradient flow, incorporating two key ingredients of modern deep learning architectures: A low-dimensional bottleneck layer that effectively enforces a rank constraint on the learned solution, as well as the possibility of a skip connection that bypasses the bottleneck. We derive closed-form expressions for all critical points of this model under product regularization, and in particular describe its global minimizer under the minimum-norm principle. From there, we derive the test risk formula in the overparameterized regime, both for models with and without skip connections. Our analysis reveals two interesting phenomena: Firstly, the bottleneck layer introduces an additional complexity measure akin to the classical bias-variance trade-off -- increasing the bottleneck width reduces bias but introduces variance, and vice versa. Secondly, skip connection can mitigate the variance in denoising autoencoders -- especially when the model is mildly overparameterized. We further analyze the impact of skip connections in denoising autoencoder using random matrix theory and support our claims with numerical evidence.
Infinite Width Limits of Self Supervised Neural Networks
Nov 17, 2024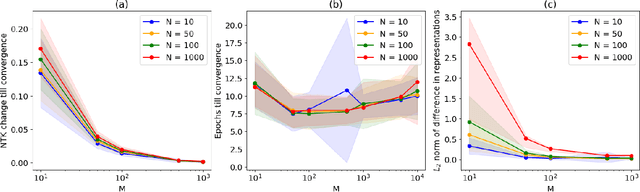
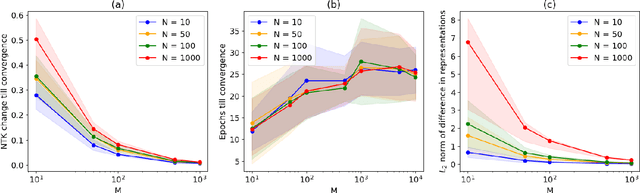
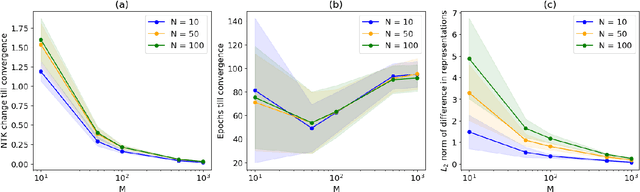
The NTK is a widely used tool in the theoretical analysis of deep learning, allowing us to look at supervised deep neural networks through the lenses of kernel regression. Recently, several works have investigated kernel models for self-supervised learning, hypothesizing that these also shed light on the behaviour of wide neural networks by virtue of the NTK. However, it remains an open question to what extent this connection is mathematically sound -- it is a commonly encountered misbelief that the kernel behaviour of wide neural networks emerges irrespective of the loss function it is trained on. In this paper, we bridge the gap between the NTK and self-supervised learning, focusing on two-layer neural networks trained under the Barlow Twins loss. We prove that the NTK of Barlow Twins indeed becomes constant as the width of the network approaches infinity. Our analysis technique is different from previous works on the NTK and may be of independent interest. Overall, our work provides a first rigorous justification for the use of classic kernel theory to understand self-supervised learning of wide neural networks. Building on this result, we derive generalization error bounds for kernelized Barlow Twins and connect them to neural networks of finite width.
Data Augmentations Go Beyond Encoding Invariances: A Theoretical Study on Self-Supervised Learning
Nov 04, 2024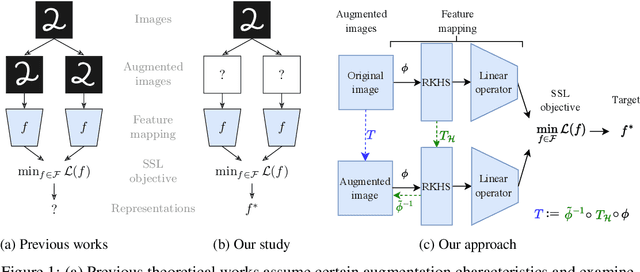
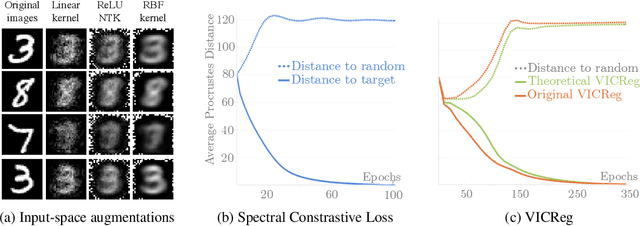
Understanding the role of data augmentations is critical for applying Self-Supervised Learning (SSL) methods in new domains. Data augmentations are commonly understood as encoding invariances into the learned representations. This interpretation suggests that SSL would require diverse augmentations that resemble the original data. However, in practice, augmentations do not need to be similar to the original data nor be diverse, and can be neither at the same time. We provide a theoretical insight into this phenomenon. We show that for different SSL losses, any non-redundant representation can be learned with a single suitable augmentation. We provide an algorithm to reconstruct such augmentations and give insights into augmentation choices in SSL.
Decision Trees for Interpretable Clusters in Mixture Models and Deep Representations
Nov 03, 2024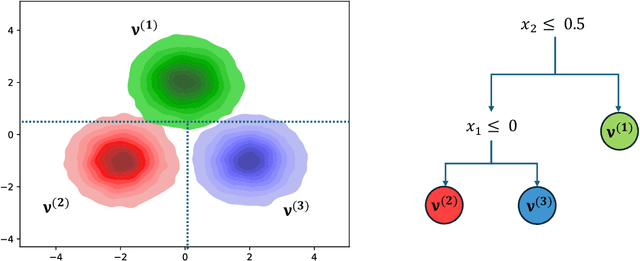
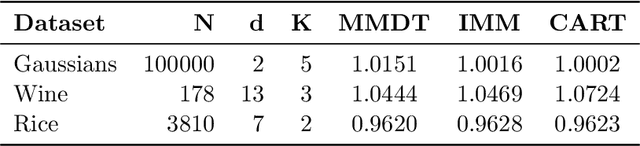
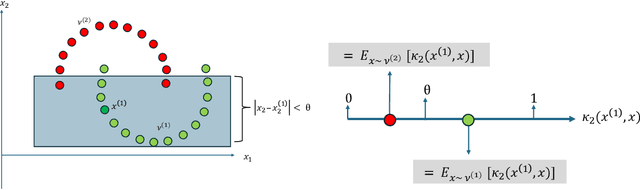
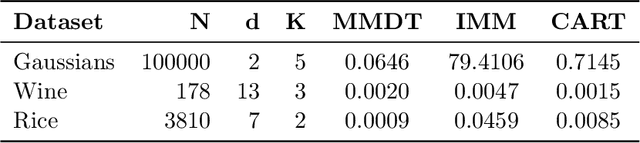
Decision Trees are one of the backbones of explainable machine learning, and often serve as interpretable alternatives to black-box models. Traditionally utilized in the supervised setting, there has recently also been a surge of interest in decision trees for unsupervised learning. While several works with worst-case guarantees on the clustering cost have appeared, these results are distribution-agnostic, and do not give insight into when decision trees can actually recover the underlying distribution of the data (up to some small error). In this paper, we therefore introduce the notion of an explainability-to-noise ratio for mixture models, formalizing the intuition that well-clustered data can indeed be explained well using a decision tree. We propose an algorithm that takes as input a mixture model and constructs a suitable tree in data-independent time. Assuming sub-Gaussianity of the mixture components, we prove upper and lower bounds on the error rate of the resulting decision tree. In addition, we demonstrate how concept activation vectors can be used to extend explainable clustering to neural networks. We empirically demonstrate the efficacy of our approach on standard tabular and image datasets.
Explaining Kernel Clustering via Decision Trees
Feb 15, 2024Despite the growing popularity of explainable and interpretable machine learning, there is still surprisingly limited work on inherently interpretable clustering methods. Recently, there has been a surge of interest in explaining the classic k-means algorithm, leading to efficient algorithms that approximate k-means clusters using axis-aligned decision trees. However, interpretable variants of k-means have limited applicability in practice, where more flexible clustering methods are often needed to obtain useful partitions of the data. In this work, we investigate interpretable kernel clustering, and propose algorithms that construct decision trees to approximate the partitions induced by kernel k-means, a nonlinear extension of k-means. We further build on previous work on explainable k-means and demonstrate how a suitable choice of features allows preserving interpretability without sacrificing approximation guarantees on the interpretable model.
Non-Parametric Representation Learning with Kernels
Sep 05, 2023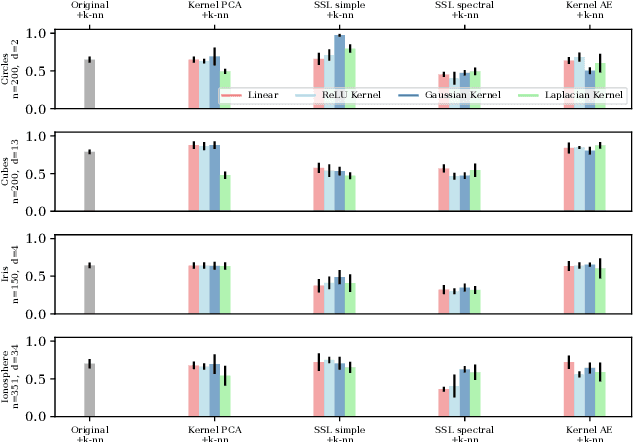
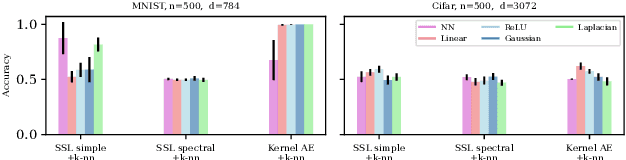
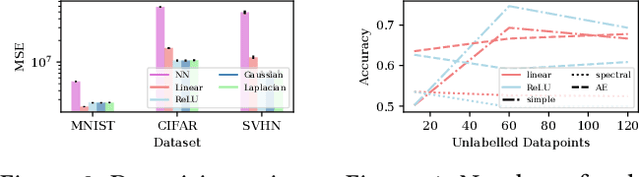
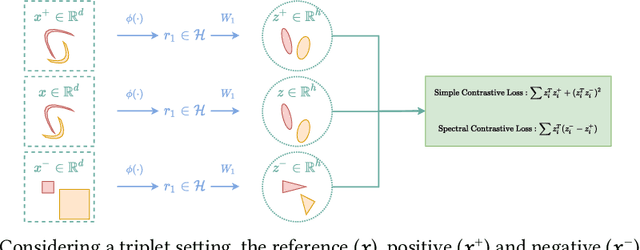
Unsupervised and self-supervised representation learning has become popular in recent years for learning useful features from unlabelled data. Representation learning has been mostly developed in the neural network literature, and other models for representation learning are surprisingly unexplored. In this work, we introduce and analyze several kernel-based representation learning approaches: Firstly, we define two kernel Self-Supervised Learning (SSL) models using contrastive loss functions and secondly, a Kernel Autoencoder (AE) model based on the idea of embedding and reconstructing data. We argue that the classical representer theorems for supervised kernel machines are not always applicable for (self-supervised) representation learning, and present new representer theorems, which show that the representations learned by our kernel models can be expressed in terms of kernel matrices. We further derive generalisation error bounds for representation learning with kernel SSL and AE, and empirically evaluate the performance of these methods in both small data regimes as well as in comparison with neural network based models.