 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite Width Limits of Self Supervised Neural Networks
Paper and Code
Nov 17, 2024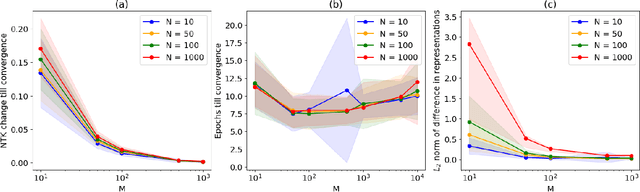
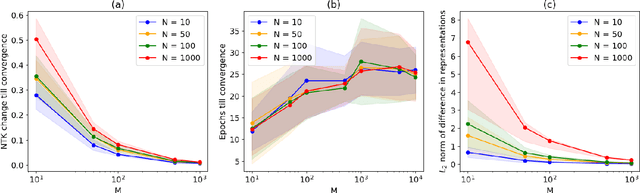
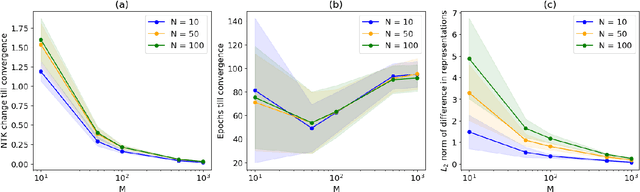
The NTK is a widely used tool in the theoretical analysis of deep learning, allowing us to look at supervised deep neural networks through the lenses of kernel regression. Recently, several works have investigated kernel models for self-supervised learning, hypothesizing that these also shed light on the behaviour of wide neural networks by virtue of the NTK. However, it remains an open question to what extent this connection is mathematically sound -- it is a commonly encountered misbelief that the kernel behaviour of wide neural networks emerges irrespective of the loss function it is trained on. In this paper, we bridge the gap between the NTK and self-supervised learning, focusing on two-layer neural networks trained under the Barlow Twins loss. We prove that the NTK of Barlow Twins indeed becomes constant as the width of the network approaches infinity. Our analysis technique is different from previous works on the NTK and may be of independent interest. Overall, our work provides a first rigorous justification for the use of classic kernel theory to understand self-supervised learning of wide neural networks. Building on this result, we derive generalization error bounds for kernelized Barlow Twins and connect them to neural networks of finite width.