 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSMGraphCLIP: Learning Global Location Representations from OpenStreetMap Graphs
Jun 06, 2026We present OSMGraphCLIP, a CLIP-style geospatial representation model that learns global location embeddings from freely available OpenStreetMap (OSM) data. OSMGraphCLIP represents geographic environments as heterogeneous graphs of typed OSM features, preserving the topological and semantic relationships among roads, buildings, land-use regions, and points of interest. A multi-scale graph encoder captures both fine-grained local structure and broader landscape composition, and supervises a spherical-harmonics location encoder through a contrastive alignment objective. We evaluate OSMGraphCLIP across a diverse suite of downstream geospatial regression and classification tasks spanning climate, ecology, socioeconomic indicators, public health, land cover, biodiversity, and wildfire forecasting, and show that structured OSM data alone supports strong global location representations across domains. OSMGraphCLIP matches or exceeds satellite-based baselines on the majority of benchmarks, with the most pronounced advantage on socioeconomic and public-health tasks, where OSM's explicit semantic annotation of the built environment encodes patterns of human activity that satellite pixels can only capture indirectly. On ecological and environmental tasks, the model remains closely competitive with imagery-based methods despite using no Earth observation data. Qualitative analysis confirms that the learned embeddings organize geographic space coherently, recovering biome boundaries, urban gradients, and tropical--temperate distinctions from map topology alone.
Magnifying change: Rapid burn scar mapping with multi-resolution, multi-source satellite imagery
Jan 14, 2026Delineating wildfire affected areas using satellite imagery remains challenging due to irregular and spatially heterogeneous spectral changes across the electromagnetic spectrum. While recent deep learning approaches achieve high accuracy when high-resolution multispectral data are available, their applicability in operational settings, where a quick delineation of the burn scar shortly after a wildfire incident is required, is limited by the trade-off between spatial resolution and temporal revisit frequency of current satellite systems. To address this limitation, we propose a novel deep learning model, namely BAM-MRCD, which employs multi-resolution, multi-source satellite imagery (MODIS and Sentinel-2) for the timely production of detailed burnt area maps with high spatial and temporal resolution. Our model manages to detect even small scale wildfires with high accuracy, surpassing similar change detection models as well as solid baselines. All data and code are available in the GitHub repository: https://github.com/Orion-AI-Lab/BAM-MRCD.
On the Generalization of Representation Uncertainty in Earth Observation
Mar 10, 2025Recent advances in Computer Vision have introduced the concept of pretrained representation uncertainty, enabling zero-shot uncertainty estimation. This holds significant potential for Earth Observation (EO), where trustworthiness is critical, yet the complexity of EO data poses challenges to uncertainty-aware methods. In this work, we investigate the generalization of representation uncertainty in EO, considering the domain's unique semantic characteristics. We pretrain uncertainties on large EO datasets and propose an evaluation framework to assess their zero-shot performance in multi-label classification and segmentation EO tasks. Our findings reveal that, unlike uncertainties pretrained on natural images, EO-pretraining exhibits strong generalization across unseen EO domains, geographic locations, and target granularities, while maintaining sensitivity to variations in ground sampling distance. We demonstrate the practical utility of pretrained uncertainties showcasing their alignment with task-specific uncertainties in downstream tasks, their sensitivity to real-world EO image noise, and their ability to generate spatial uncertainty estimates out-of-the-box. Initiating the discussion on representation uncertainty in EO, our study provides insights into its strengths and limitations, paving the way for future research in the field. Code and weights are available at: https://github.com/Orion-AI-Lab/EOUncertaintyGeneralization.
GAIA: A Global, Multi-modal, Multi-scale Vision-Language Dataset for Remote Sensing Image Analysis
Feb 13, 2025
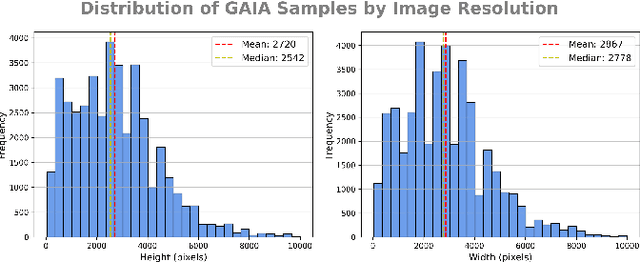

The continuous operation of Earth-orbiting satellites generates vast and ever-growing archives of Remote Sensing (RS) images. Natural language presents an intuitive interface for accessing, querying, and interpreting the data from such archives. However, existing Vision-Language Models (VLMs) are predominantly trained on web-scraped, noisy image-text data, exhibiting limited exposure to the specialized domain of RS. This deficiency results in poor performance on RS-specific tasks, as commonly used datasets often lack detailed, scientifically accurate textual descriptions and instead emphasize solely on attributes like date and location. To bridge this critical gap, we introduce GAIA, a novel dataset designed for multi-scale, multi-sensor, and multi-modal RS image analysis. GAIA comprises of 205,150 meticulously curated RS image-text pairs, representing a diverse range of RS modalities associated to different spatial resolutions. Unlike existing vision-language datasets in RS, GAIA specifically focuses on capturing a diverse range of RS applications, providing unique information about environmental changes, natural disasters, and various other dynamic phenomena. The dataset provides a spatially and temporally balanced distribution, spanning across the globe, covering the last 25 years with a balanced temporal distribution of observations. GAIA's construction involved a two-stage process: (1) targeted web-scraping of images and accompanying text from reputable RS-related sources, and (2) generation of five high-quality, scientifically grounded synthetic captions for each image using carefully crafted prompts that leverage the advanced vision-language capabilities of GPT-4o. Our extensive experiments, including fine-tuning of CLIP and BLIP2 models, demonstrate that GAIA significantly improves performance on RS image classification, cross-modal retrieval and image captioning tasks.
FireCastNet: Earth-as-a-Graph for Seasonal Fire Prediction
Feb 03, 2025



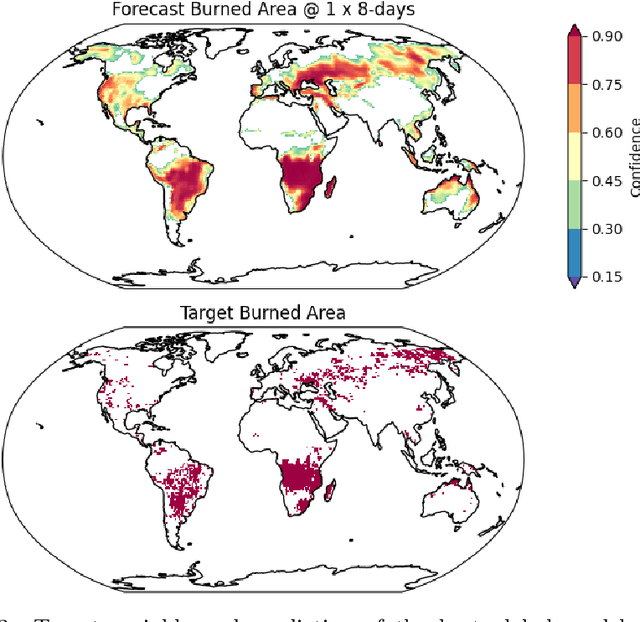
With climate change expected to exacerbate fire weather conditions, the accurate and timely anticipation of wildfires becomes increasingly crucial for disaster mitigation. In this study, we utilize SeasFire, a comprehensive global wildfire dataset with climate, vegetation, oceanic indices, and human-related variables, to enable seasonal wildfire forecasting with machine learning. For the predictive analysis, we present FireCastNet, a novel architecture which combines a 3D convolutional encoder with GraphCast, originally developed for global short-term weather forecasting using graph neural networks. FireCastNet is trained to capture the context leading to wildfires, at different spatial and temporal scales. Our investigation focuses on assessing the effectiveness of our model in predicting the presence of burned areas at varying forecasting time horizons globally, extending up to six months into the future, and on how different spatial or/and temporal context affects the performance. Our findings demonstrate the potential of deep learning models in seasonal fire forecasting; longer input time-series leads to more robust predictions, while integrating spatial information to capture wildfire spatio-temporal dynamics boosts performance. Finally, our results hint that in order to enhance performance at longer forecasting horizons, a larger receptive field spatially needs to be considered.
Seasonal Fire Prediction using Spatio-Temporal Deep Neural Networks
Apr 09, 2024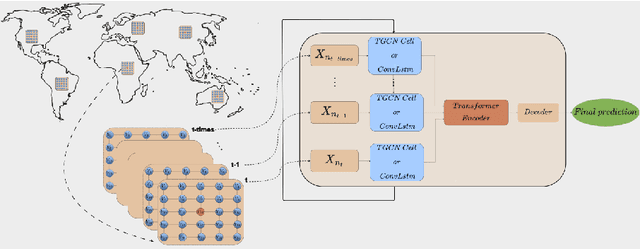


With climate change expected to exacerbate fire weather conditions, the accurate anticipation of wildfires on a global scale becomes increasingly crucial for disaster mitigation. In this study, we utilize SeasFire, a comprehensive global wildfire dataset with climate, vegetation, oceanic indices, and human-related variables, to enable seasonal wildfire forecasting with machine learning. For the predictive analysis, we train deep learning models with different architectures that capture the spatio-temporal context leading to wildfires. Our investigation focuses on assessing the effectiveness of these models in predicting the presence of burned areas at varying forecasting time horizons globally, extending up to six months into the future, and on how different spatial or/and temporal context affects the performance of the models. Our findings demonstrate the great potential of deep learning models in seasonal fire forecasting; longer input time-series leads to more robust predictions across varying forecasting horizons, while integrating spatial information to capture wildfire spatio-temporal dynamics boosts performance. Finally, our results hint that in order to enhance performance at longer forecasting horizons, a larger receptive field spatially needs to be considered.
Mind the Modality Gap: Towards a Remote Sensing Vision-Language Model via Cross-modal Alignment
Feb 15, 2024Deep Learning (DL) is undergoing a paradigm shift with the emergence of foundation models, aptly named by their crucial, yet incomplete nature. In this work, we focus on Contrastive Language-Image Pre-training (CLIP), an open-vocabulary foundation model, which achieves high accuracy across many image classification tasks and is often competitive with a fully supervised baseline without being explicitly trained. Nevertheless, there are still domains where zero-shot CLIP performance is far from optimal, such as Remote Sensing (RS) and medical imagery. These domains do not only exhibit fundamentally different distributions compared to natural images, but also commonly rely on complementary modalities, beyond RGB, to derive meaningful insights. To this end, we propose a methodology for the purpose of aligning distinct RS imagery modalities with the visual and textual modalities of CLIP. Our two-stage procedure, comprises of robust fine-tuning CLIP in order to deal with the distribution shift, accompanied by the cross-modal alignment of a RS modality encoder, in an effort to extend the zero-shot capabilities of CLIP. We ultimately demonstrate our method on the tasks of RS imagery classification and cross-modal retrieval. We empirically show that both robust fine-tuning and cross-modal alignment translate to significant performance gains, across several RS benchmark datasets. Notably, these enhancements are achieved without the reliance on textual descriptions, without introducing any task-specific parameters, without training from scratch and without catastrophic forgetting.
Kuro Siwo: 12.1 billion $m^2$ under the water. A global multi-temporal satellite dataset for rapid flood mapping
Nov 18, 2023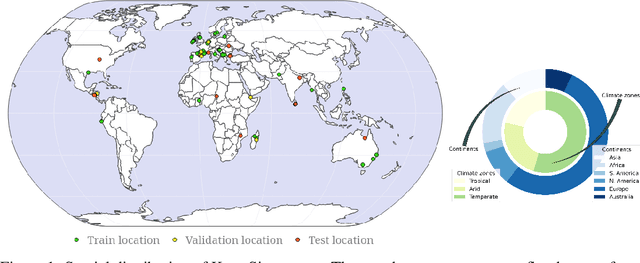
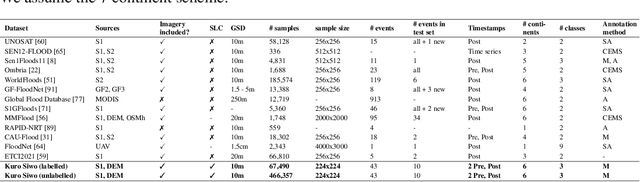
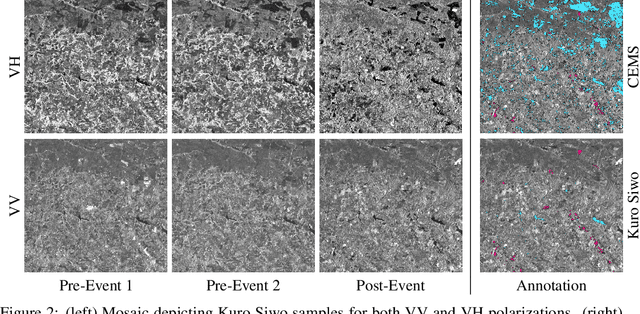
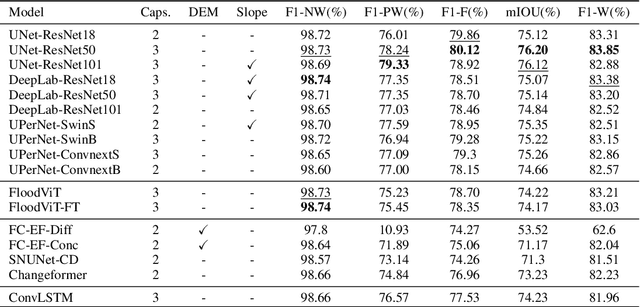
Global floods, exacerbated by climate change, pose severe threats to human life, infrastructure, and the environment. This urgency is highlighted by recent catastrophic events in Pakistan and New Zealand, underlining the critical need for precise flood mapping for guiding restoration efforts, understanding vulnerabilities, and preparing for future events. While Synthetic Aperture Radar (SAR) offers day-and-night, all-weather imaging capabilities, harnessing it for deep learning is hindered by the absence of a large annotated dataset. To bridge this gap, we introduce Kuro Siwo, a meticulously curated multi-temporal dataset, spanning 32 flood events globally. Our dataset maps more than 63 billion m2 of land, with 12.1 billion of them being either a flooded area or a permanent water body. Kuro Siwo stands out for its unparalleled annotation quality to facilitate rapid flood mapping in a supervised setting. We also augment learning by including a large unlabeled set of SAR samples, aimed at self-supervised pretraining. We provide an extensive benchmark and strong baselines for a diverse set of flood events from Europe, America, Africa and Australia. Our benchmark demonstrates the quality of Kuro Siwo annotations, training models that can achieve $\approx$ 85% and $\approx$ 87% in F1-score for flooded areas and general water detection respectively. This work calls on the deep learning community to develop solution-driven algorithms for rapid flood mapping, with the potential to aid civil protection and humanitarian agencies amid climate change challenges. Our code and data will be made available at https://github.com/Orion-AI-Lab/KuroSiwo
FLOGA: A machine learning ready dataset, a benchmark and a novel deep learning model for burnt area mapping with Sentinel-2
Nov 06, 2023



Over the last decade there has been an increasing frequency and intensity of wildfires across the globe, posing significant threats to human and animal lives, ecosystems, and socio-economic stability. Therefore urgent action is required to mitigate their devastating impact and safeguard Earth's natural resources. Robust Machine Learning methods combined with the abundance of high-resolution satellite imagery can provide accurate and timely mappings of the affected area in order to assess the scale of the event, identify the impacted assets and prioritize and allocate resources effectively for the proper restoration of the damaged region. In this work, we create and introduce a machine-learning ready dataset we name FLOGA (Forest wiLdfire Observations for the Greek Area). This dataset is unique as it comprises of satellite imagery acquired before and after a wildfire event, it contains information from Sentinel-2 and MODIS modalities with variable spatial and spectral resolution, and contains a large number of events where the corresponding burnt area ground truth has been annotated by domain experts. FLOGA covers the wider region of Greece, which is characterized by a Mediterranean landscape and climatic conditions. We use FLOGA to provide a thorough comparison of multiple Machine Learning and Deep Learning algorithms for the automatic extraction of burnt areas, approached as a change detection task. We also compare the results to those obtained using standard specialized spectral indices for burnt area mapping. Finally, we propose a novel Deep Learning model, namely BAM-CD. Our benchmark results demonstrate the efficacy of the proposed technique in the automatic extraction of burnt areas, outperforming all other methods in terms of accuracy and robustness. Our dataset and code are publicly available at: https://github.com/Orion-AI-Lab/FLOGA.
TeleViT: Teleconnection-driven Transformers Improve Subseasonal to Seasonal Wildfire Forecasting
Jun 19, 2023



Wildfires are increasingly exacerbated as a result of climate change, necessitating advanced proactive measures for effective mitigation. It is important to forecast wildfires weeks and months in advance to plan forest fuel management, resource procurement and allocation. To achieve such accurate long-term forecasts at a global scale, it is crucial to employ models that account for the Earth system's inherent spatio-temporal interactions, such as memory effects and teleconnections. We propose a teleconnection-driven vision transformer (TeleViT), capable of treating the Earth as one interconnected system, integrating fine-grained local-scale inputs with global-scale inputs, such as climate indices and coarse-grained global variables. Through comprehensive experimentation, we demonstrate the superiority of TeleViT in accurately predicting global burned area patterns for various forecasting windows, up to four months in advance. The gain is especially pronounced in larger forecasting windows, demonstrating the improved ability of deep learning models that exploit teleconnections to capture Earth system dynamics. Code available at https://github.com/Orion-Ai-Lab/TeleViT.