 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact and adaptive multiplane images for view synthesis
Feb 19, 2021
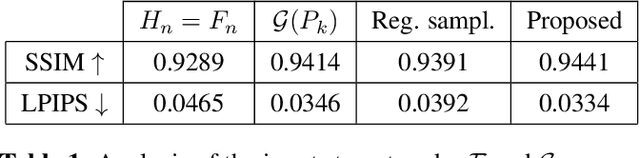
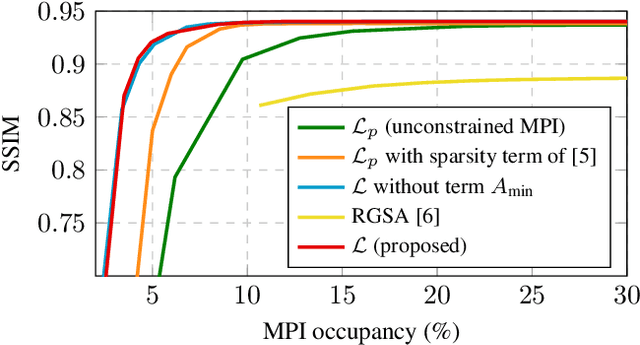

Recently, learning methods have been designed to create Multiplane Images (MPIs) for view synthesis. While MPIs are extremely powerful and facilitate high quality renderings, a great amount of memory is required, making them impractical for many applications. In this paper, we propose a learning method that optimizes the available memory to render compact and adaptive MPIs. Our MPIs avoid redundant information and take into account the scene geometry to determine the depth sampling.
Emulation as an Accurate Alternative to Interpolation in Sampling Radiative Transfer Codes
Dec 07, 2020
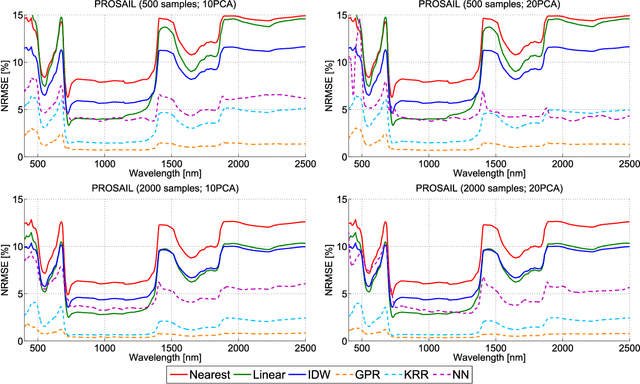

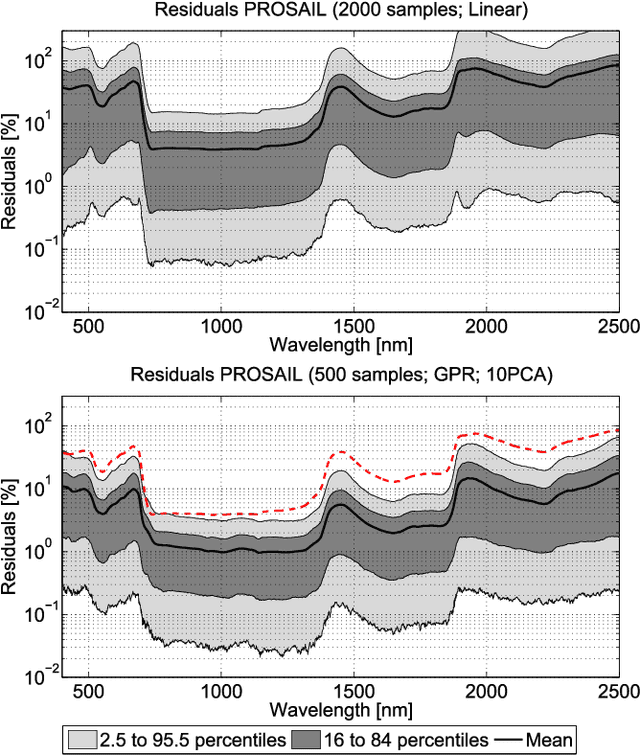
Computationally expensive Radiative Transfer Models (RTMs) are widely used} to realistically reproduce the light interaction with the Earth surface and atmosphere. Because these models take long processing time, the common practice is to first generate a sparse look-up table (LUT) and then make use of interpolation methods to sample the multi-dimensional LUT input variable space. However, the question arise whether common interpolation methods perform most accurate. As an alternative to interpolation, this work proposes to use emulation, i.e., approximating the RTM output by means of statistical learning. Two experiments were conducted to assess the accuracy in delivering spectral outputs using interpolation and emulation: (1) at canopy level, using PROSAIL; and (2) at top-of-atmosphere level, using MODTRAN. Various interpolation (nearest-neighbour, inverse distance weighting, piece-wice linear) and emulation (Gaussian process regression (GPR), kernel ridge regression, neural networks) methods were evaluated against a dense reference LUT. In all experiments, the emulation methods clearly produced more accurate output spectra than classical interpolation methods. GPR emulation performed up to ten times more accurately than the best performing interpolation method, and this with a speed that is competitive with the faster interpolation methods. It is concluded that emulation can function as a fast and more accurate alternative to commonly used interpolation methods for reconstructing RTM spectral data.
Learning Occlusion-Aware View Synthesis for Light Fields
May 27, 2019



In this work, we present a novel learning-based approach to synthesize new views of a light field image. In particular, given the four corner views of a light field, the presented method estimates any in-between view. We use three sequential convolutional neural networks for feature extraction, scene geometry estimation and view selection. Compared to state-of-the-art approaches, in order to handle occlusions we propose to estimate a different disparity map per view. Jointly with the view selection network, this strategy shows to be the most important to have proper reconstructions near object boundaries. Ablation studies and comparison against the state of the art on Lytro light fields show the superior performance of the proposed method. Furthermore, the method is adapted and tested on light fields with wide baselines acquired with a camera array and, in spite of having to deal with large occluded areas, the proposed approach yields very promising results.
Meaningful Matches in Stereovision
Dec 06, 2011



This paper introduces a statistical method to decide whether two blocks in a pair of of images match reliably. The method ensures that the selected block matches are unlikely to have occurred "just by chance." The new approach is based on the definition of a simple but faithful statistical "background model" for image blocks learned from the image itself. A theorem guarantees that under this model not more than a fixed number of wrong matches occurs (on average) for the whole image. This fixed number (the number of false alarms) is the only method parameter. Furthermore, the number of false alarms associated with each match measures its reliability. This "a contrario" block-matching method, however, cannot rule out false matches due to the presence of periodic objects in the images. But it is successfully complemented by a parameterless "self-similarity threshold." Experimental evidence shows that the proposed method also detects occlusions and incoherent motions due to vehicles and pedestrians in non simultaneous stereo.