 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Guided Network with Cluster-Based Operators for Spatio-Spectral Super-Resolution
May 30, 2025This paper addresses the problem of reconstructing a high-resolution hyperspectral image from a low-resolution multispectral observation. While spatial super-resolution and spectral super-resolution have been extensively studied, joint spatio-spectral super-resolution remains relatively explored. We propose an end-to-end model-driven framework that explicitly decomposes the joint spatio-spectral super-resolution problem into spatial super-resolution, spectral super-resolution and fusion tasks. Each sub-task is addressed by unfolding a variational-based approach, where the operators involved in the proximal gradient iterative scheme are replaced with tailored learnable modules. In particular, we design an upsampling operator for spatial super-resolution based on classical back-projection algorithms, adapted to handle arbitrary scaling factors. Spectral reconstruction is performed using learnable cluster-based upsampling and downsampling operators. For image fusion, we integrate low-frequency estimation and high-frequency injection modules to combine the spatial and spectral information from spatial super-resolution and spectral super-resolution outputs. Additionally, we introduce an efficient nonlocal post-processing step that leverages image self-similarity by combining a multi-head attention mechanism with residual connections. Extensive evaluations on several datasets and sampling factors demonstrate the effectiveness of our approach. The source code will be available at https://github.com/TAMI-UIB/JSSUNet
Nonlocal Retinex-Based Variational Model and its Deep Unfolding Twin for Low-Light Image Enhancement
Apr 10, 2025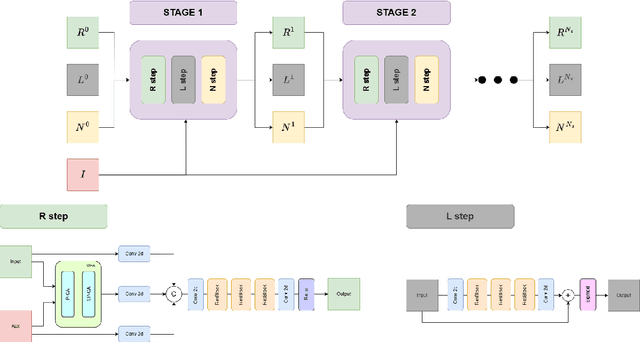



Images captured under low-light conditions present significant limitations in many applications, as poor lighting can obscure details, reduce contrast, and hide noise. Removing the illumination effects and enhancing the quality of such images is crucial for many tasks, such as image segmentation and object detection. In this paper, we propose a variational method for low-light image enhancement based on the Retinex decomposition into illumination, reflectance, and noise components. A color correction pre-processing step is applied to the low-light image, which is then used as the observed input in the decomposition. Moreover, our model integrates a novel nonlocal gradient-type fidelity term designed to preserve structural details. Additionally, we propose an automatic gamma correction module. Building on the proposed variational approach, we extend the model by introducing its deep unfolding counterpart, in which the proximal operators are replaced with learnable networks. We propose cross-attention mechanisms to capture long-range dependencies in both the nonlocal prior of the reflectance and the nonlocal gradient-based constraint. Experimental results demonstrate that both methods compare favorably with several recent and state-of-the-art techniques across different datasets. In particular, despite not relying on learning strategies, the variational model outperforms most deep learning approaches both visually and in terms of quality metrics.
Multi-Head Attention Residual Unfolded Network for Model-Based Pansharpening
Sep 04, 2024

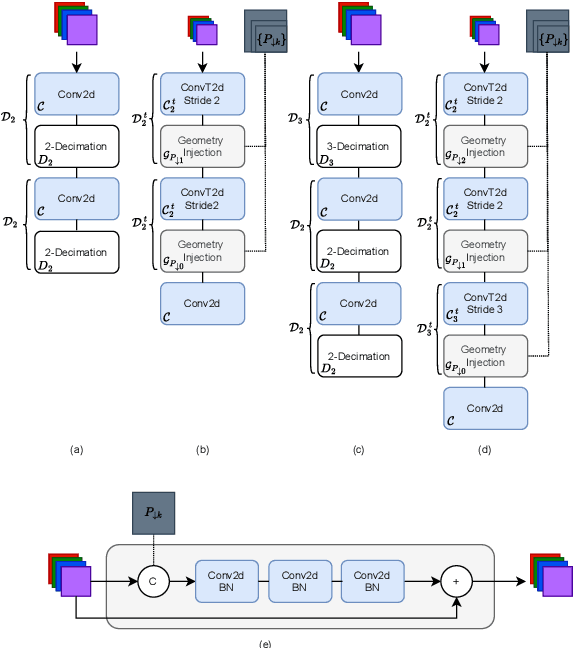

The objective of pansharpening and hypersharpening is to accurately combine a high-resolution panchromatic (PAN) image with a low-resolution multispectral (MS) or hyperspectral (HS) image, respectively. Unfolding fusion methods integrate the powerful representation capabilities of deep learning with the robustness of model-based approaches. These techniques involve unrolling the steps of the optimization scheme derived from the minimization of an energy into a deep learning framework, resulting in efficient and highly interpretable architectures. In this paper, we propose a model-based deep unfolded method for satellite image fusion. Our approach is based on a variational formulation that incorporates the classic observation model for MS/HS data, a high-frequency injection constraint based on the PAN image, and an arbitrary convex prior. For the unfolding stage, we introduce upsampling and downsampling layers that use geometric information encoded in the PAN image through residual networks. The backbone of our method is a multi-head attention residual network (MARNet), which replaces the proximity operator in the optimization scheme and combines multiple head attentions with residual learning to exploit image self-similarities via nonlocal operators defined in terms of patches. Additionally, we incorporate a post-processing module based on the MARNet architecture to further enhance the quality of the fused images. Experimental results on PRISMA, Quickbird, and WorldView2 datasets demonstrate the superior performance of our method and its ability to generalize across different sensor configurations and varying spatial and spectral resolutions. The source code will be available at https://github.com/TAMI-UIB/MARNet.
Compact and adaptive multiplane images for view synthesis
Feb 19, 2021
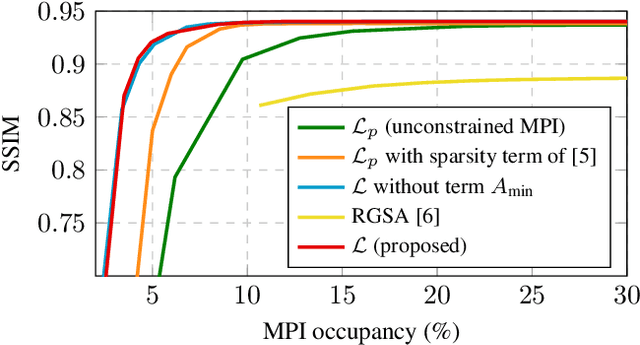

Recently, learning methods have been designed to create Multiplane Images (MPIs) for view synthesis. While MPIs are extremely powerful and facilitate high quality renderings, a great amount of memory is required, making them impractical for many applications. In this paper, we propose a learning method that optimizes the available memory to render compact and adaptive MPIs. Our MPIs avoid redundant information and take into account the scene geometry to determine the depth sampling.
Learning Occlusion-Aware View Synthesis for Light Fields
May 27, 2019



In this work, we present a novel learning-based approach to synthesize new views of a light field image. In particular, given the four corner views of a light field, the presented method estimates any in-between view. We use three sequential convolutional neural networks for feature extraction, scene geometry estimation and view selection. Compared to state-of-the-art approaches, in order to handle occlusions we propose to estimate a different disparity map per view. Jointly with the view selection network, this strategy shows to be the most important to have proper reconstructions near object boundaries. Ablation studies and comparison against the state of the art on Lytro light fields show the superior performance of the proposed method. Furthermore, the method is adapted and tested on light fields with wide baselines acquired with a camera array and, in spite of having to deal with large occluded areas, the proposed approach yields very promising results.