 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Vision Foundation Models with Drop-in Depthwise Convolution
May 21, 2026Pretrained vision foundation models deliver strong performance across tasks with limited fine-tuning. However, their Vision Transformer (ViT) backbones impose high inference costs, limiting deployment on resource-constrained devices. In this work, we accelerate large-scale pretrained ViTs while preserving their feature extraction capabilities by exploiting the intrinsic convolution-like behavior of some attention heads. Specifically, we introduce an efficient depthwise convolution-based layer that serves as a drop-in replacement for these heads. Additionally, we propose simple strategies to identify which heads can be replaced and introduce a fine-tuning procedure that recovers downstream task performance. Across both image classification and segmentation tasks, our method achieves 17-20\% percent inference speedup with minimal performance degradation. We validate the approach through detailed derivations, extensive experiments, and efficiency benchmarks. The reference implementation is publicly available.
Low-Latency Embedded Driver Monitoring System with a Multi-Task Neural Network
May 04, 2026Road traffic accidents remain a significant global concern, with the majority attributed to human factors such as driver distraction and fatigue. This study proposes a camera-based approach to derive useful indicators to assess driver attentiveness and alertness. The proposed pipeline jointly satisfies the stringent real-time requirements imposed by the critical application and minimizes the computational requirements to allow for deployment on a tight computational budget. To this end, we develop a lightweight multi-task neural network that predicts multiple indicators for the face region in a single forward pass. The developed model is integrated into a complete execution workflow to produce a real-time estimate of attentiveness, fatigue, and engagement in distracting activities.
Uncovering the Background-Induced bias in RGB based 6-DoF Object Pose Estimation
Apr 17, 2023



In recent years, there has been a growing trend of using data-driven methods in industrial settings. These kinds of methods often process video images or parts, therefore the integrity of such images is crucial. Sometimes datasets, e.g. consisting of images, can be sophisticated for various reasons. It becomes critical to understand how the manipulation of video and images can impact the effectiveness of a machine learning method. Our case study aims precisely to analyze the Linemod dataset, considered the state of the art in 6D pose estimation context. That dataset presents images accompanied by ArUco markers; it is evident that such markers will not be available in real-world contexts. We analyze how the presence of the markers affects the pose estimation accuracy, and how this bias may be mitigated through data augmentation and other methods. Our work aims to show how the presence of these markers goes to modify, in the testing phase, the effectiveness of the deep learning method used. In particular, we will demonstrate, through the tool of saliency maps, how the focus of the neural network is captured in part by these ArUco markers. Finally, a new dataset, obtained by applying geometric tools to Linemod, will be proposed in order to demonstrate our hypothesis and uncovering the bias. Our results demonstrate the potential for bias in 6DOF pose estimation networks, and suggest methods for reducing this bias when training with markers.
CERBERUS: Simple and Effective All-In-One Automotive Perception Model with Multi Task Learning
Oct 03, 2022

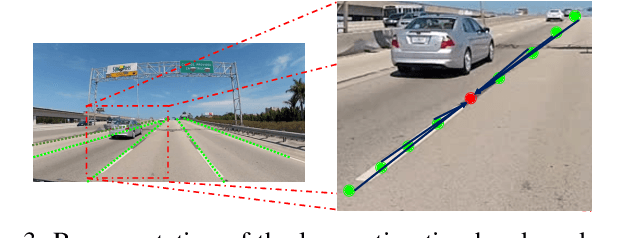

Perceiving the surrounding environment is essential for enabling autonomous or assisted driving functionalities. Common tasks in this domain include detecting road users, as well as determining lane boundaries and classifying driving conditions. Over the last few years, a large variety of powerful Deep Learning models have been proposed to address individual tasks of camera-based automotive perception with astonishing performances. However, the limited capabilities of in-vehicle embedded computing platforms cannot cope with the computational effort required to run a heavy model for each individual task. In this work, we present CERBERUS (CEnteR Based End-to-end peRception Using a Single model), a lightweight model that leverages a multitask-learning approach to enable the execution of multiple perception tasks at the cost of a single inference. The code will be made publicly available at https://github.com/cscribano/CERBERUS
DCT-Former: Efficient Self-Attention with Discrete Cosine Transform
Mar 03, 2022
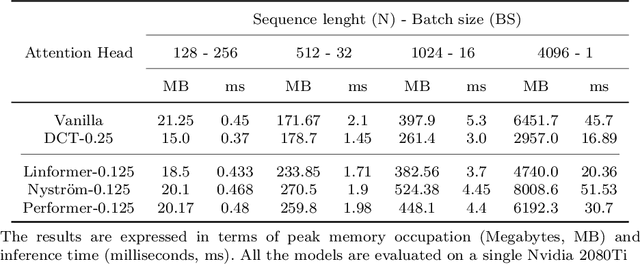
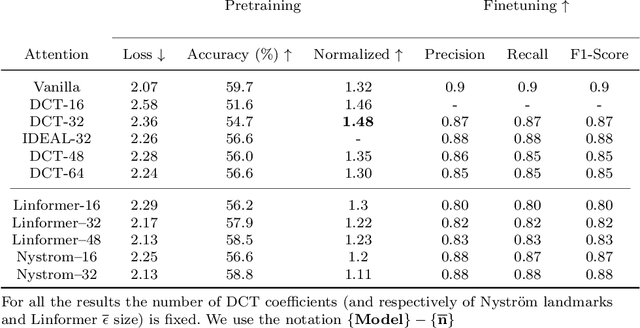
Since their introduction the Trasformer architectures emerged as the dominating architectures for both natural language processing and, more recently, computer vision applications. An intrinsic limitation of this family of "fully-attentive" architectures arises from the computation of the dot-product attention, which grows both in memory consumption and number of operations as $O(n^2)$ where $n$ stands for the input sequence length, thus limiting the applications that require modeling very long sequences. Several approaches have been proposed so far in the literature to mitigate this issue, with varying degrees of success. Our idea takes inspiration from the world of lossy data compression (such as the JPEG algorithm) to derive an approximation of the attention module by leveraging the properties of the Discrete Cosine Transform. An extensive section of experiments shows that our method takes up less memory for the same performance, while also drastically reducing inference time. This makes it particularly suitable in real-time contexts on embedded platforms. Moreover, we assume that the results of our research might serve as a starting point for a broader family of deep neural models with reduced memory footprint. The implementation will be made publicly available at https://github.com/cscribano/DCT-Former-Public
All You Can Embed: Natural Language based Vehicle Retrieval with Spatio-Temporal Transformers
Jun 18, 2021
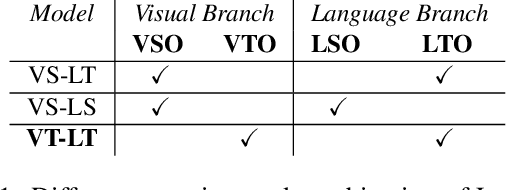
Combining Natural Language with Vision represents a unique and interesting challenge in the domain of Artificial Intelligence. The AI City Challenge Track 5 for Natural Language-Based Vehicle Retrieval focuses on the problem of combining visual and textual information, applied to a smart-city use case. In this paper, we present All You Can Embed (AYCE), a modular solution to correlate single-vehicle tracking sequences with natural language. The main building blocks of the proposed architecture are (i) BERT to provide an embedding of the textual descriptions, (ii) a convolutional backbone along with a Transformer model to embed the visual information. For the training of the retrieval model, a variation of the Triplet Margin Loss is proposed to learn a distance measure between the visual and language embeddings. The code is publicly available at https://github.com/cscribano/AYCE_2021.