 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming the One-Epoch Phenomenon in Online Recommendation System by Two-stage Contrastive ID Pre-training
Aug 26, 2025ID-based embeddings are widely used in web-scale online recommendation systems. However, their susceptibility to overfitting, particularly due to the long-tail nature of data distributions, often limits training to a single epoch, a phenomenon known as the "one-epoch problem." This challenge has driven research efforts to optimize performance within the first epoch by enhancing convergence speed or feature sparsity. In this study, we introduce a novel two-stage training strategy that incorporates a pre-training phase using a minimal model with contrastive loss, enabling broader data coverage for the embedding system. Our offline experiments demonstrate that multi-epoch training during the pre-training phase does not lead to overfitting, and the resulting embeddings improve online generalization when fine-tuned for more complex downstream recommendation tasks. We deployed the proposed system in live traffic at Pinterest, achieving significant site-wide engagement gains.
* Published at RecSys'24, see https://dl.acm.org/doi/10.1145/3640457.3688053
TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest
May 31, 2023Sequential models that encode user activity for next action prediction have become a popular design choice for building web-scale personalized recommendation systems. Traditional methods of sequential recommendation either utilize end-to-end learning on realtime user actions, or learn user representations separately in an offline batch-generated manner. This paper (1) presents Pinterest's ranking architecture for Homefeed, our personalized recommendation product and the largest engagement surface; (2) proposes TransAct, a sequential model that extracts users' short-term preferences from their realtime activities; (3) describes our hybrid approach to ranking, which combines end-to-end sequential modeling via TransAct with batch-generated user embeddings. The hybrid approach allows us to combine the advantages of responsiveness from learning directly on realtime user activity with the cost-effectiveness of batch user representations learned over a longer time period. We describe the results of ablation studies, the challenges we faced during productionization, and the outcome of an online A/B experiment, which validates the effectiveness of our hybrid ranking model. We further demonstrate the effectiveness of TransAct on other surfaces such as contextual recommendations and search. Our model has been deployed to production in Homefeed, Related Pins, Notifications, and Search at Pinterest.
Community detection using fast low-cardinality semidefinite programming
Dec 04, 2020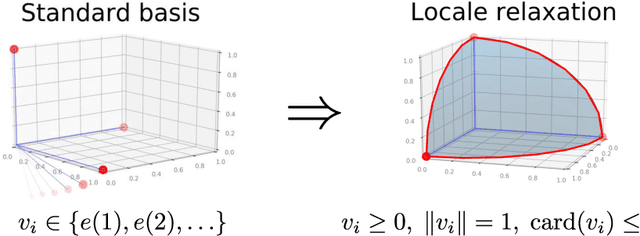
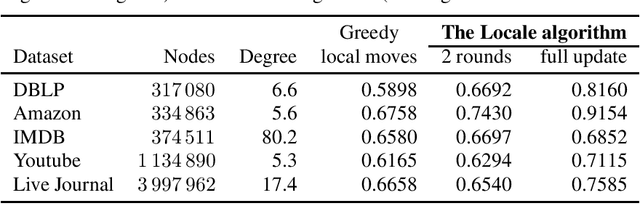


Modularity maximization has been a fundamental tool for understanding the community structure of a network, but the underlying optimization problem is nonconvex and NP-hard to solve. State-of-the-art algorithms like the Louvain or Leiden methods focus on different heuristics to help escape local optima, but they still depend on a greedy step that moves node assignment locally and is prone to getting trapped. In this paper, we propose a new class of low-cardinality algorithm that generalizes the local update to maximize a semidefinite relaxation derived from max-k-cut. This proposed algorithm is scalable, empirically achieves the global semidefinite optimality for small cases, and outperforms the state-of-the-art algorithms in real-world datasets with little additional time cost. From the algorithmic perspective, it also opens a new avenue for scaling-up semidefinite programming when the solutions are sparse instead of low-rank.
Efficient semidefinite-programming-based inference for binary and multi-class MRFs
Dec 04, 2020



Probabilistic inference in pairwise Markov Random Fields (MRFs), i.e. computing the partition function or computing a MAP estimate of the variables, is a foundational problem in probabilistic graphical models. Semidefinite programming relaxations have long been a theoretically powerful tool for analyzing properties of probabilistic inference, but have not been practical owing to the high computational cost of typical solvers for solving the resulting SDPs. In this paper, we propose an efficient method for computing the partition function or MAP estimate in a pairwise MRF by instead exploiting a recently proposed coordinate-descent-based fast semidefinite solver. We also extend semidefinite relaxations from the typical binary MRF to the full multi-class setting, and develop a compact semidefinite relaxation that can again be solved efficiently using the solver. We show that the method substantially outperforms (both in terms of solution quality and speed) the existing state of the art in approximate inference, on benchmark problems drawn from previous work. We also show that our approach can scale to large MRF domains such as fully-connected pairwise CRF models used in computer vision.
SATNet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver
May 29, 2019


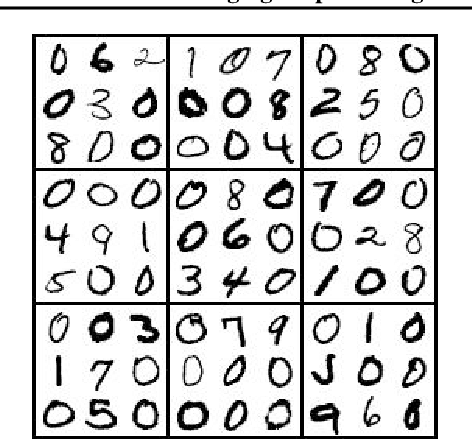
Integrating logical reasoning within deep learning architectures has been a major goal of modern AI systems. In this paper, we propose a new direction toward this goal by introducing a differentiable (smoothed) maximum satisfiability (MAXSAT) solver that can be integrated into the loop of larger deep learning systems. Our (approximate) solver is based upon a fast coordinate descent approach to solving the semidefinite program (SDP) associated with the MAXSAT problem. We show how to analytically differentiate through the solution to this SDP and efficiently solve the associated backward pass. We demonstrate that by integrating this solver into end-to-end learning systems, we can learn the logical structure of challenging problems in a minimally supervised fashion. In particular, we show that we can learn the parity function using single-bit supervision (a traditionally hard task for deep networks) and learn how to play 9x9 Sudoku solely from examples. We also solve a "visual Sudok" problem that maps images of Sudoku puzzles to their associated logical solutions by combining our MAXSAT solver with a traditional convolutional architecture. Our approach thus shows promise in integrating logical structures within deep learning.
Low-rank semidefinite programming for the MAX2SAT problem
Dec 15, 2018


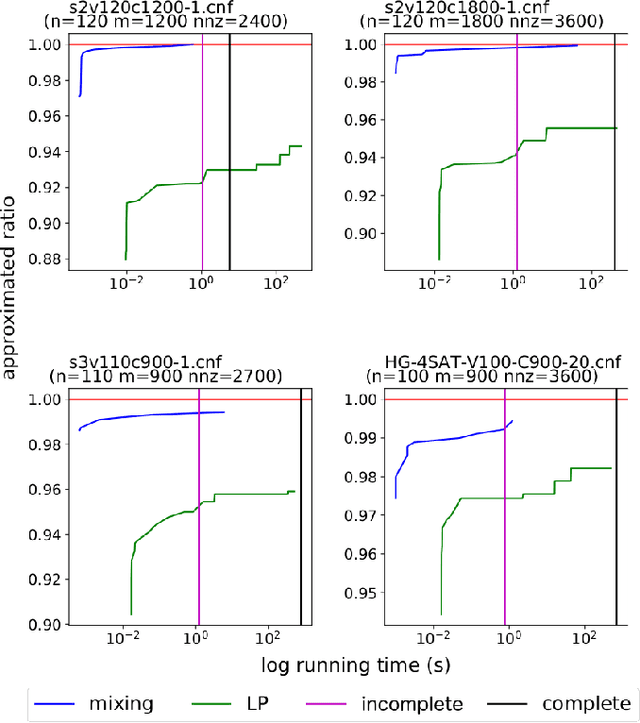
This paper proposes a new algorithm for solving MAX2SAT problems based on combining search methods with semidefinite programming approaches. Semidefinite programming techniques are well-known as a theoretical tool for approximating maximum satisfiability problems, but their application has traditionally been very limited by their speed and randomized nature. Our approach overcomes this difficult by using a recent approach to low-rank semidefinite programming, specialized to work in an incremental fashion suitable for use in an exact search algorithm. The method can be used both within complete or incomplete solver, and we demonstrate on a variety of problems from recent competitions. Our experiments show that the approach is faster (sometimes by orders of magnitude) than existing state-of-the-art complete and incomplete solvers, representing a substantial advance in search methods specialized for MAX2SAT problems.
The Mixing method: low-rank coordinate descent for semidefinite programming with diagonal constraints
Jul 04, 2018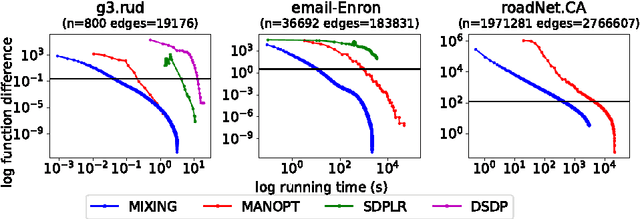
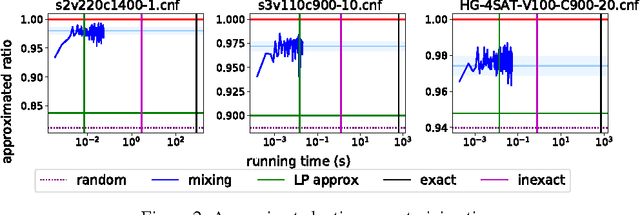
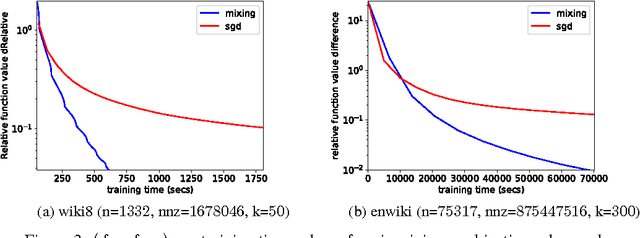
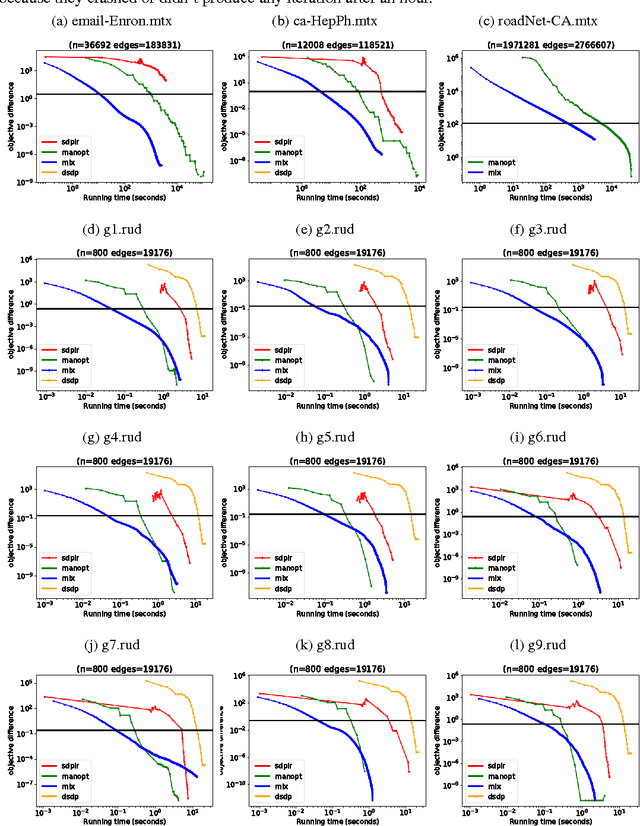
In this paper, we propose a low-rank coordinate descent approach to structured semidefinite programming with diagonal constraints. The approach, which we call the Mixing method, is extremely simple to implement, has no free parameters, and typically attains an order of magnitude or better improvement in optimization performance over the current state of the art. We show that the method is strictly decreasing, converges to a critical point, and further that for sufficient rank all non-optimal critical points are unstable. Moreover, we prove that with a step size, the Mixing method converges to the global optimum of the semidefinite program almost surely in a locally linear rate under random initialization. This is the first low-rank semidefinite programming method that has been shown to achieve a global optimum on the spherical manifold without assumption. We apply our algorithm to two related domains: solving the maximum cut semidefinite relaxation, and solving a maximum satisfiability relaxation (we also briefly consider additional applications such as learning word embeddings). In all settings, we demonstrate substantial improvement over the existing state of the art along various dimensions, and in total, this work expands the scope and scale of problems that can be solved using semidefinite programming methods.