 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFANDA: A Novel Approach to Perform Follow-up Query Analysis
Paper and Code



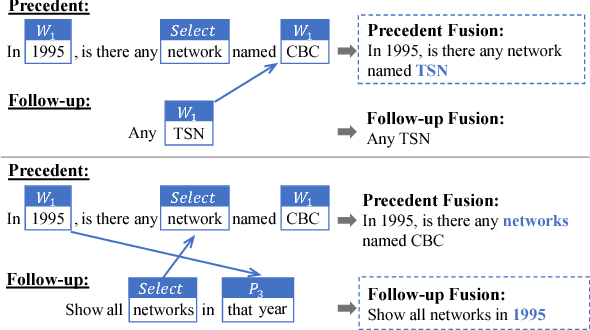
Recent work on Natural Language Interfaces to Databases (NLIDB) has attracted considerable attention. NLIDB allow users to search databases using natural language instead of SQL-like query languages. While saving the users from having to learn query languages, multi-turn interaction with NLIDB usually involves multiple queries where contextual information is vital to understand the users' query intents. In this paper, we address a typical contextual understanding problem, termed as follow-up query analysis. In spite of its ubiquity, follow-up query analysis has not been well studied due to two primary obstacles: the multifarious nature of follow-up query scenarios and the lack of high-quality datasets. Our work summarizes typical follow-up query scenarios and provides a new FollowUp dataset with $1000$ query triples on 120 tables. Moreover, we propose a novel approach FANDA, which takes into account the structures of queries and employs a ranking model with weakly supervised max-margin learning. The experimental results on FollowUp demonstrate the superiority of FANDA over multiple baselines across multiple metrics.