 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster MoE LLM Inference for Extremely Large Models
May 06, 2025

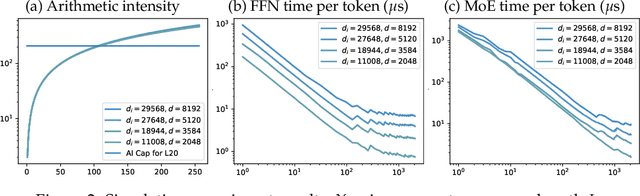
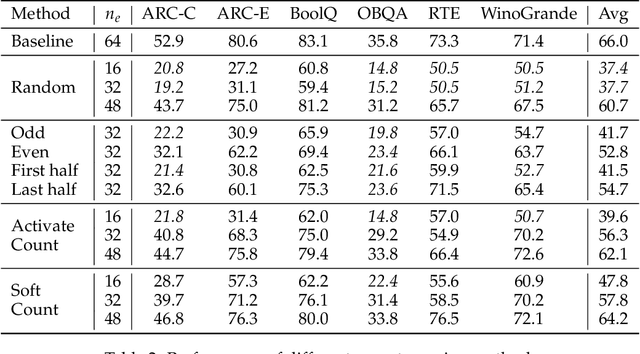
Sparse Mixture of Experts (MoE) large language models (LLMs) are gradually becoming the mainstream approach for ultra-large-scale models. Existing optimization efforts for MoE models have focused primarily on coarse-grained MoE architectures. With the emergence of DeepSeek Models, fine-grained MoE models are gaining popularity, yet research on them remains limited. Therefore, we want to discuss the efficiency dynamic under different service loads. Additionally, fine-grained models allow deployers to reduce the number of routed experts, both activated counts and total counts, raising the question of how this reduction affects the trade-off between MoE efficiency and performance. Our findings indicate that while deploying MoE models presents greater challenges, it also offers significant optimization opportunities. Reducing the number of activated experts can lead to substantial efficiency improvements in certain scenarios, with only minor performance degradation. Reducing the total number of experts provides limited efficiency gains but results in severe performance degradation. Our method can increase throughput by at least 10\% without any performance degradation. Overall, we conclude that MoE inference optimization remains an area with substantial potential for exploration and improvement.
Reference Trustable Decoding: A Training-Free Augmentation Paradigm for Large Language Models
Sep 30, 2024

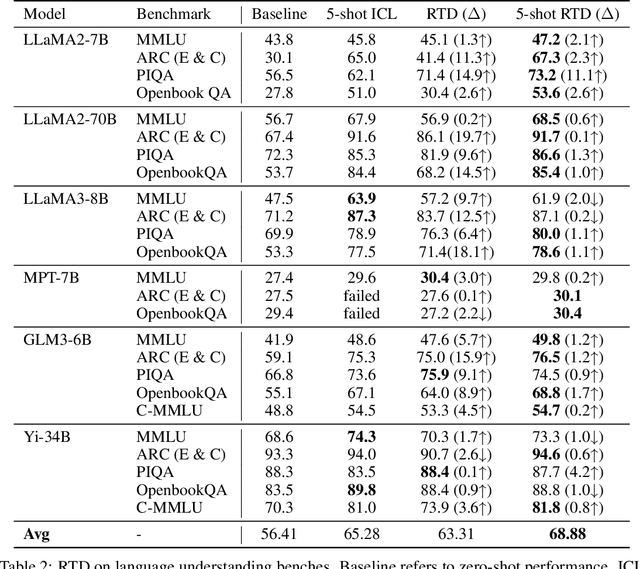
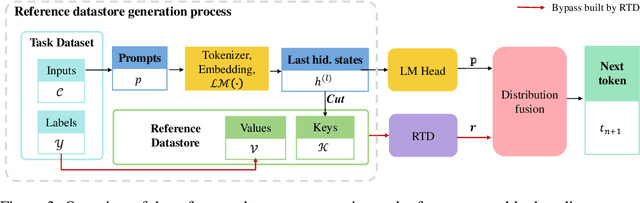
Large language models (LLMs) have rapidly advanced and demonstrated impressive capabilities. In-Context Learning (ICL) and Parameter-Efficient Fine-Tuning (PEFT) are currently two mainstream methods for augmenting LLMs to downstream tasks. ICL typically constructs a few-shot learning scenario, either manually or by setting up a Retrieval-Augmented Generation (RAG) system, helping models quickly grasp domain knowledge or question-answering patterns without changing model parameters. However, this approach involves trade-offs, such as slower inference speed and increased space occupancy. PEFT assists the model in adapting to tasks through minimal parameter modifications, but the training process still demands high hardware requirements, even with a small number of parameters involved. To address these challenges, we propose Reference Trustable Decoding (RTD), a paradigm that allows models to quickly adapt to new tasks without fine-tuning, maintaining low inference costs. RTD constructs a reference datastore from the provided training examples and optimizes the LLM's final vocabulary distribution by flexibly selecting suitable references based on the input, resulting in more trustable responses and enabling the model to adapt to downstream tasks at a low cost. Experimental evaluations on various LLMs using different benchmarks demonstrate that RTD establishes a new paradigm for augmenting models to downstream tasks. Furthermore, our method exhibits strong orthogonality with traditional methods, allowing for concurrent usage.
Keep the Cost Down: A Review on Methods to Optimize LLM' s KV-Cache Consumption
Jul 28, 2024
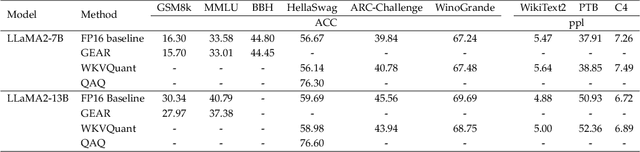


Large Language Models (LLMs), epitomized by ChatGPT' s release in late 2022, have revolutionized various industries with their advanced language comprehension. However, their efficiency is challenged by the Transformer architecture' s struggle with handling long texts. KV-Cache has emerged as a pivotal solution to this issue, converting the time complexity of token generation from quadratic to linear, albeit with increased GPU memory overhead proportional to conversation length. With the development of the LLM community and academia, various KV-Cache compression methods have been proposed. In this review, we dissect the various properties of KV-Cache and elaborate on various methods currently used to optimize the KV-Cache space usage of LLMs. These methods span the pre-training phase, deployment phase, and inference phase, and we summarize the commonalities and differences among these methods. Additionally, we list some metrics for evaluating the long-text capabilities of large language models, from both efficiency and capability perspectives. Our review thus sheds light on the evolving landscape of LLM optimization, offering insights into future advancements in this dynamic field.