 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference Trustable Decoding: A Training-Free Augmentation Paradigm for Large Language Models
Paper and Code
Sep 30, 2024

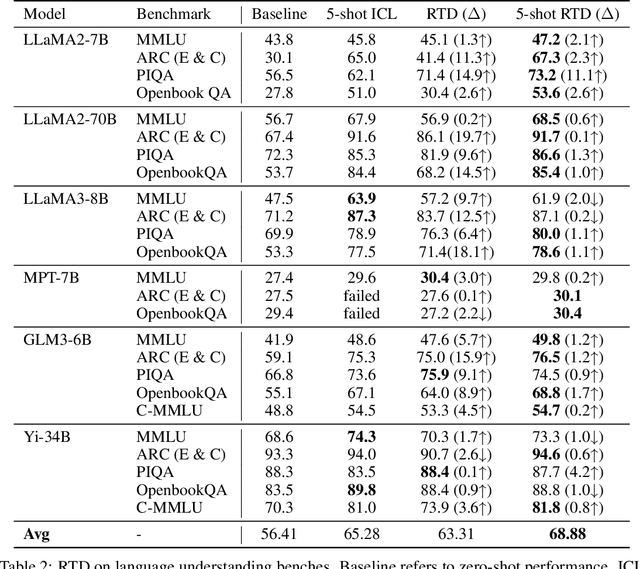
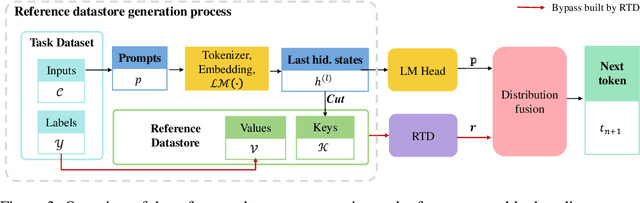
Large language models (LLMs) have rapidly advanced and demonstrated impressive capabilities. In-Context Learning (ICL) and Parameter-Efficient Fine-Tuning (PEFT) are currently two mainstream methods for augmenting LLMs to downstream tasks. ICL typically constructs a few-shot learning scenario, either manually or by setting up a Retrieval-Augmented Generation (RAG) system, helping models quickly grasp domain knowledge or question-answering patterns without changing model parameters. However, this approach involves trade-offs, such as slower inference speed and increased space occupancy. PEFT assists the model in adapting to tasks through minimal parameter modifications, but the training process still demands high hardware requirements, even with a small number of parameters involved. To address these challenges, we propose Reference Trustable Decoding (RTD), a paradigm that allows models to quickly adapt to new tasks without fine-tuning, maintaining low inference costs. RTD constructs a reference datastore from the provided training examples and optimizes the LLM's final vocabulary distribution by flexibly selecting suitable references based on the input, resulting in more trustable responses and enabling the model to adapt to downstream tasks at a low cost. Experimental evaluations on various LLMs using different benchmarks demonstrate that RTD establishes a new paradigm for augmenting models to downstream tasks. Furthermore, our method exhibits strong orthogonality with traditional methods, allowing for concurrent usage.