 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster MoE LLM Inference for Extremely Large Models
May 06, 2025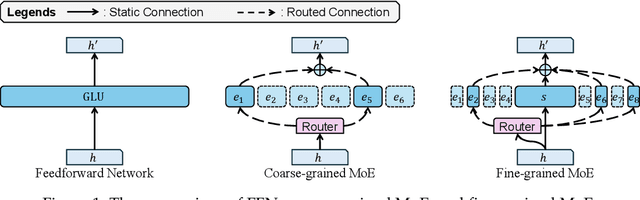

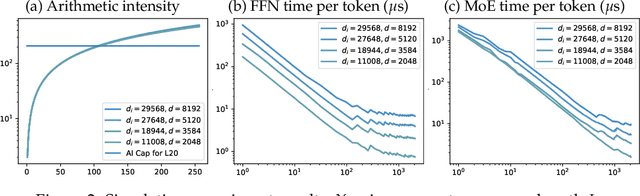
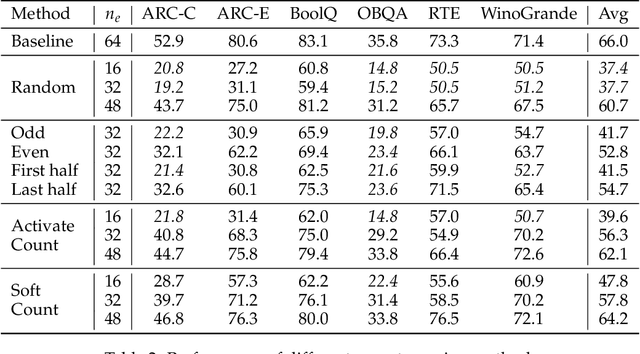
Sparse Mixture of Experts (MoE) large language models (LLMs) are gradually becoming the mainstream approach for ultra-large-scale models. Existing optimization efforts for MoE models have focused primarily on coarse-grained MoE architectures. With the emergence of DeepSeek Models, fine-grained MoE models are gaining popularity, yet research on them remains limited. Therefore, we want to discuss the efficiency dynamic under different service loads. Additionally, fine-grained models allow deployers to reduce the number of routed experts, both activated counts and total counts, raising the question of how this reduction affects the trade-off between MoE efficiency and performance. Our findings indicate that while deploying MoE models presents greater challenges, it also offers significant optimization opportunities. Reducing the number of activated experts can lead to substantial efficiency improvements in certain scenarios, with only minor performance degradation. Reducing the total number of experts provides limited efficiency gains but results in severe performance degradation. Our method can increase throughput by at least 10\% without any performance degradation. Overall, we conclude that MoE inference optimization remains an area with substantial potential for exploration and improvement.
Joint Automatic Speech Recognition And Structure Learning For Better Speech Understanding
Jan 13, 2025



Spoken language understanding (SLU) is a structure prediction task in the field of speech. Recently, many works on SLU that treat it as a sequence-to-sequence task have achieved great success. However, This method is not suitable for simultaneous speech recognition and understanding. In this paper, we propose a joint speech recognition and structure learning framework (JSRSL), an end-to-end SLU model based on span, which can accurately transcribe speech and extract structured content simultaneously. We conduct experiments on name entity recognition and intent classification using the Chinese dataset AISHELL-NER and the English dataset SLURP. The results show that our proposed method not only outperforms the traditional sequence-to-sequence method in both transcription and extraction capabilities but also achieves state-of-the-art performance on the two datasets.