 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Agnostic Learning for Unbiased Authentication
Oct 11, 2020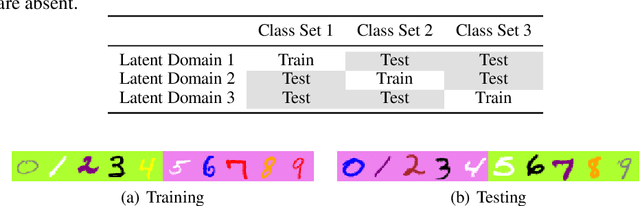
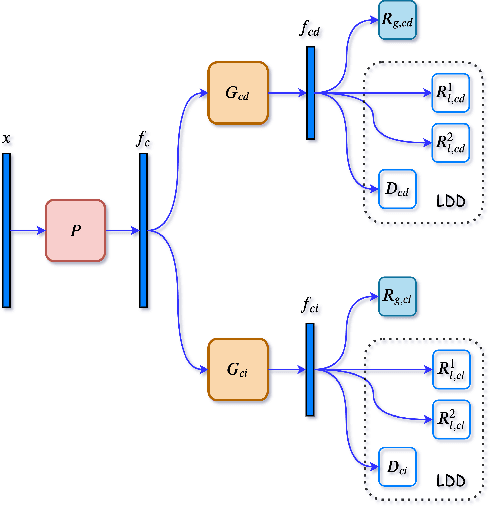
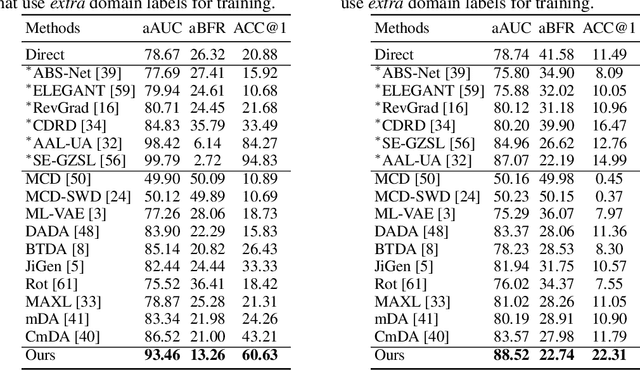

Authentication is the task of confirming the matching relationship between a data instance and a given identity. Typical examples of authentication problems include face recognition and person re-identification. Data-driven authentication could be affected by undesired biases, i.e., the models are often trained in one domain (e.g., for people wearing spring outfits) while applied in other domains (e.g., they change the clothes to summer outfits). Previous works have made efforts to eliminate domain-difference. They typically assume domain annotations are provided, and all the domains share classes. However, for authentication, there could be a large number of domains shared by different identities/classes, and it is impossible to annotate these domains exhaustively. It could make domain-difference challenging to model and eliminate. In this paper, we propose a domain-agnostic method that eliminates domain-difference without domain labels. We alternately perform latent domain discovery and domain-difference elimination until our model no longer detects domain-difference. In our approach, the latent domains are discovered by learning the heterogeneous predictive relationships between inputs and outputs. Then domain-difference is eliminated in both class-dependent and class-independent components. Comprehensive empirical evaluation results are provided to demonstrate the effectiveness and superiority of our proposed method.
Adversarial Infidelity Learning for Model Interpretation
Jun 27, 2020



Model interpretation is essential in data mining and knowledge discovery. It can help understand the intrinsic model working mechanism and check if the model has undesired characteristics. A popular way of performing model interpretation is Instance-wise Feature Selection (IFS), which provides an importance score of each feature representing the data samples to explain how the model generates the specific output. In this paper, we propose a Model-agnostic Effective Efficient Direct (MEED) IFS framework for model interpretation, mitigating concerns about sanity, combinatorial shortcuts, model identifiability, and information transmission. Also, we focus on the following setting: using selected features to directly predict the output of the given model, which serves as a primary evaluation metric for model-interpretation methods. Apart from the features, we involve the output of the given model as an additional input to learn an explainer based on more accurate information. To learn the explainer, besides fidelity, we propose an Adversarial Infidelity Learning (AIL) mechanism to boost the explanation learning by screening relatively unimportant features. Through theoretical and experimental analysis, we show that our AIL mechanism can help learn the desired conditional distribution between selected features and targets. Moreover, we extend our framework by integrating efficient interpretation methods as proper priors to provide a warm start. Comprehensive empirical evaluation results are provided by quantitative metrics and human evaluation to demonstrate the effectiveness and superiority of our proposed method. Our code is publicly available online at https://github.com/langlrsw/MEED.
Additive Adversarial Learning for Unbiased Authentication
May 28, 2019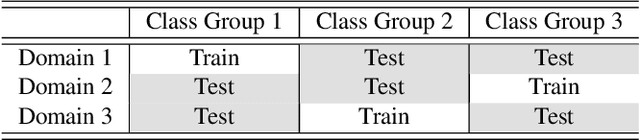
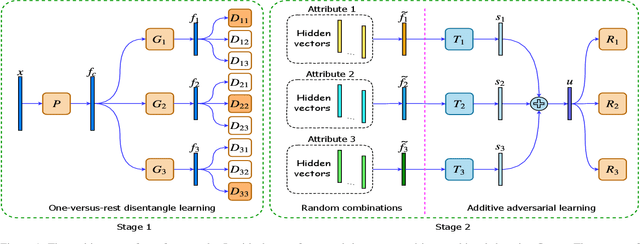

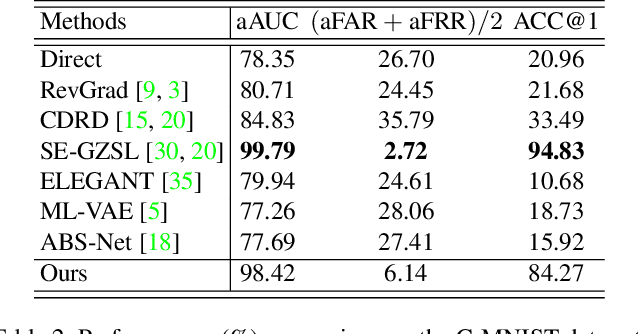
Authentication is a task aiming to confirm the truth between data instances and personal identities. Typical authentication applications include face recognition, person re-identification, authentication based on mobile devices and so on. The recently-emerging data-driven authentication process may encounter undesired biases, i.e., the models are often trained in one domain (e.g., for people wearing spring outfits) while required to apply in other domains (e.g., they change the clothes to summer outfits). To address this issue, we propose a novel two-stage method that disentangles the class/identity from domain-differences, and we consider multiple types of domain-difference. In the first stage, we learn disentangled representations by a one-versus-rest disentangle learning (OVRDL) mechanism. In the second stage, we improve the disentanglement by an additive adversarial learning (AAL) mechanism. Moreover, we discuss the necessity to avoid a learning dilemma due to disentangling causally related types of domain-difference. Comprehensive evaluation results demonstrate the effectiveness and superiority of the proposed method.