 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIT Model: A Hierarchical Interaction-Enhanced Two-Tower Model for Pre-Ranking Systems
May 26, 2025Online display advertising platforms rely on pre-ranking systems to efficiently filter and prioritize candidate ads from large corpora, balancing relevance to users with strict computational constraints. The prevailing two-tower architecture, though highly efficient due to its decoupled design and pre-caching, suffers from cross-domain interaction and coarse similarity metrics, undermining its capacity to model complex user-ad relationships. In this study, we propose the Hierarchical Interaction-Enhanced Two-Tower (HIT) model, a new architecture that augments the two-tower paradigm with two key components: $\textit{generators}$ that pre-generate holistic vectors incorporating coarse-grained user-ad interactions through a dual-generator framework with a cosine-similarity-based generation loss as the training objective, and $\textit{multi-head representers}$ that project embeddings into multiple latent subspaces to capture fine-grained, multi-faceted user interests and multi-dimensional ad attributes. This design enhances modeling effectiveness without compromising inference efficiency. Extensive experiments on public datasets and large-scale online A/B testing on Tencent's advertising platform demonstrate that HIT significantly outperforms several baselines in relevance metrics, yielding a $1.66\%$ increase in Gross Merchandise Volume and a $1.55\%$ improvement in Return on Investment, alongside similar serving latency to the vanilla two-tower models. The HIT model has been successfully deployed in Tencent's online display advertising system, serving billions of impressions daily. The code is available at https://anonymous.4open.science/r/HIT_model-5C23.
Cross-domain Cross-architecture Black-box Attacks on Fine-tuned Models with Transferred Evolutionary Strategies
Aug 28, 2022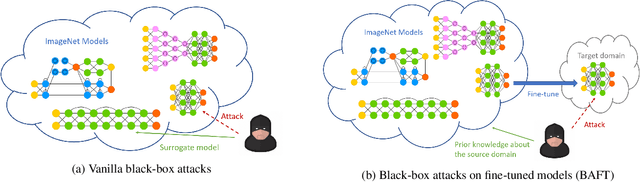
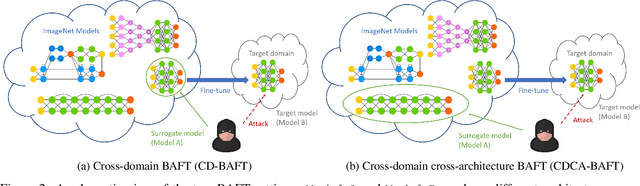

Fine-tuning can be vulnerable to adversarial attacks. Existing works about black-box attacks on fine-tuned models (BAFT) are limited by strong assumptions. To fill the gap, we propose two novel BAFT settings, cross-domain and cross-domain cross-architecture BAFT, which only assume that (1) the target model for attacking is a fine-tuned model, and (2) the source domain data is known and accessible. To successfully attack fine-tuned models under both settings, we propose to first train an adversarial generator against the source model, which adopts an encoder-decoder architecture and maps a clean input to an adversarial example. Then we search in the low-dimensional latent space produced by the encoder of the adversarial generator. The search is conducted under the guidance of the surrogate gradient obtained from the source model. Experimental results on different domains and different network architectures demonstrate that the proposed attack method can effectively and efficiently attack the fine-tuned models.
Uncertainty-Aware Learning Against Label Noise on Imbalanced Datasets
Jul 12, 2022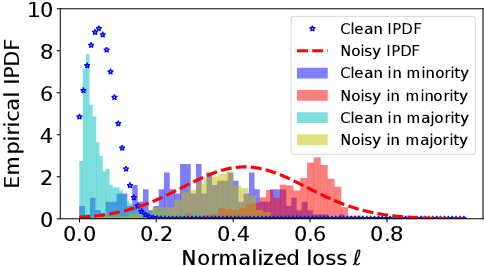
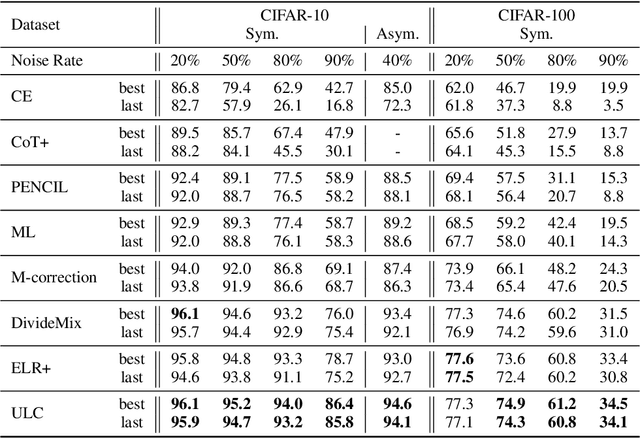
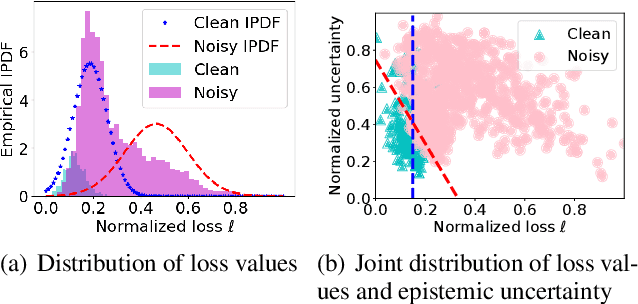
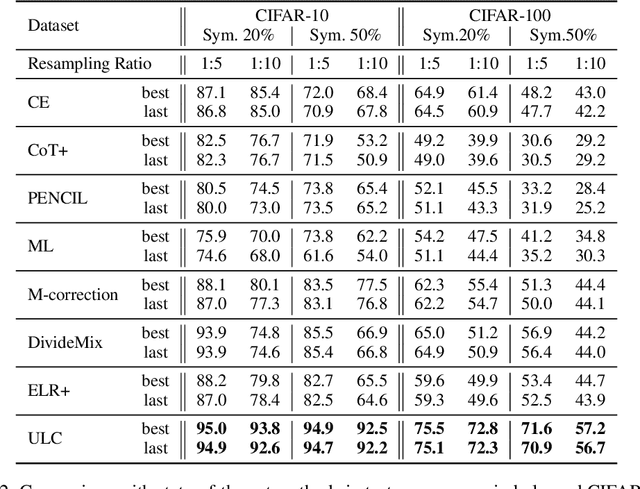
Learning against label noise is a vital topic to guarantee a reliable performance for deep neural networks. Recent research usually refers to dynamic noise modeling with model output probabilities and loss values, and then separates clean and noisy samples. These methods have gained notable success. However, unlike cherry-picked data, existing approaches often cannot perform well when facing imbalanced datasets, a common scenario in the real world. We thoroughly investigate this phenomenon and point out two major issues that hinder the performance, i.e., \emph{inter-class loss distribution discrepancy} and \emph{misleading predictions due to uncertainty}. The first issue is that existing methods often perform class-agnostic noise modeling. However, loss distributions show a significant discrepancy among classes under class imbalance, and class-agnostic noise modeling can easily get confused with noisy samples and samples in minority classes. The second issue refers to that models may output misleading predictions due to epistemic uncertainty and aleatoric uncertainty, thus existing methods that rely solely on the output probabilities may fail to distinguish confident samples. Inspired by our observations, we propose an Uncertainty-aware Label Correction framework~(ULC) to handle label noise on imbalanced datasets. First, we perform epistemic uncertainty-aware class-specific noise modeling to identify trustworthy clean samples and refine/discard highly confident true/corrupted labels. Then, we introduce aleatoric uncertainty in the subsequent learning process to prevent noise accumulation in the label noise modeling process. We conduct experiments on several synthetic and real-world datasets. The results demonstrate the effectiveness of the proposed method, especially on imbalanced datasets.
Contrastive Multi-view Hyperbolic Hierarchical Clustering
May 05, 2022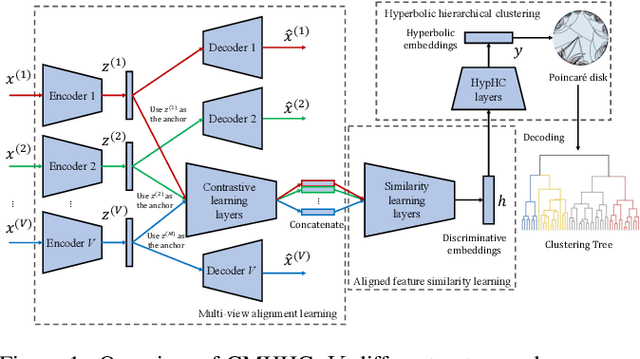
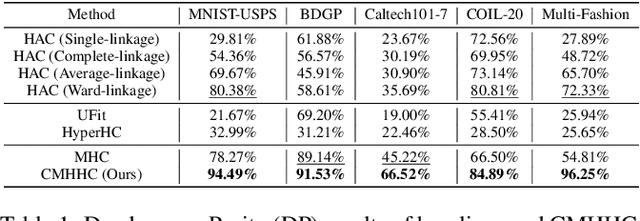
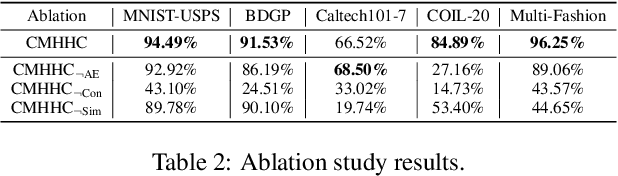
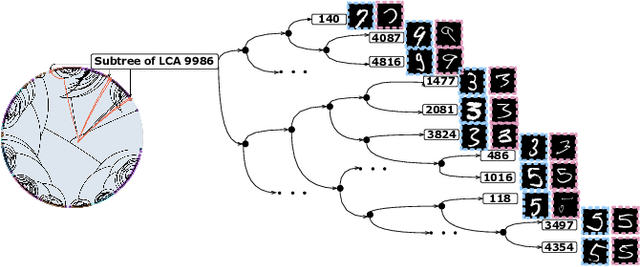
Hierarchical clustering recursively partitions data at an increasingly finer granularity. In real-world applications, multi-view data have become increasingly important. This raises a less investigated problem, i.e., multi-view hierarchical clustering, to better understand the hierarchical structure of multi-view data. To this end, we propose a novel neural network-based model, namely Contrastive Multi-view Hyperbolic Hierarchical Clustering (CMHHC). It consists of three components, i.e., multi-view alignment learning, aligned feature similarity learning, and continuous hyperbolic hierarchical clustering. First, we align sample-level representations across multiple views in a contrastive way to capture the view-invariance information. Next, we utilize both the manifold and Euclidean similarities to improve the metric property. Then, we embed the representations into a hyperbolic space and optimize the hyperbolic embeddings via a continuous relaxation of hierarchical clustering loss. Finally, a binary clustering tree is decoded from optimized hyperbolic embeddings. Experimental results on five real-world datasets demonstrate the effectiveness of the proposed method and its components.
AFINet: Attentive Feature Integration Networks for Image Classification
May 10, 2021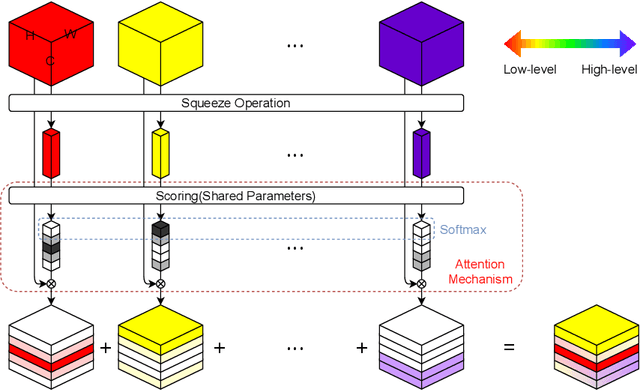
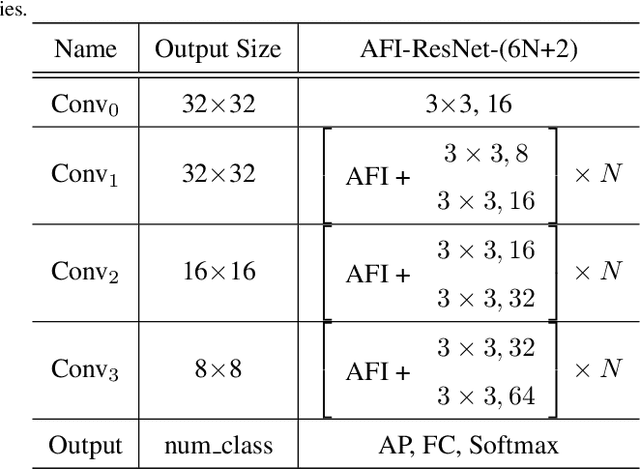

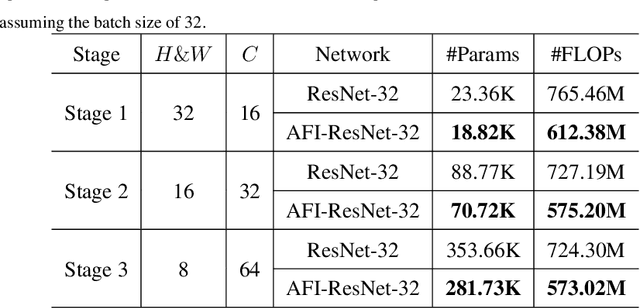
Convolutional Neural Networks (CNNs) have achieved tremendous success in a number of learning tasks including image classification. Recent advanced models in CNNs, such as ResNets, mainly focus on the skip connection to avoid gradient vanishing. DenseNet designs suggest creating additional bypasses to transfer features as an alternative strategy in network design. In this paper, we design Attentive Feature Integration (AFI) modules, which are widely applicable to most recent network architectures, leading to new architectures named AFI-Nets. AFI-Nets explicitly model the correlations among different levels of features and selectively transfer features with a little overhead.AFI-ResNet-152 obtains a 1.24% relative improvement on the ImageNet dataset while decreases the FLOPs by about 10% and the number of parameters by about 9.2% compared to ResNet-152.
MultiFace: A Generic Training Mechanism for Boosting Face Recognition Performance
Jan 31, 2021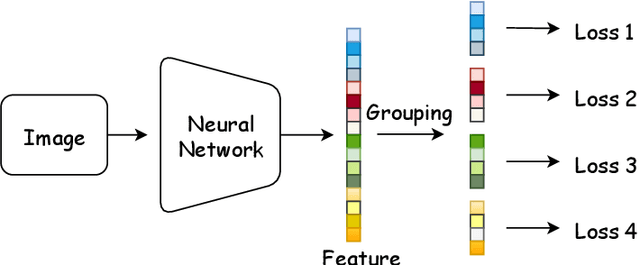
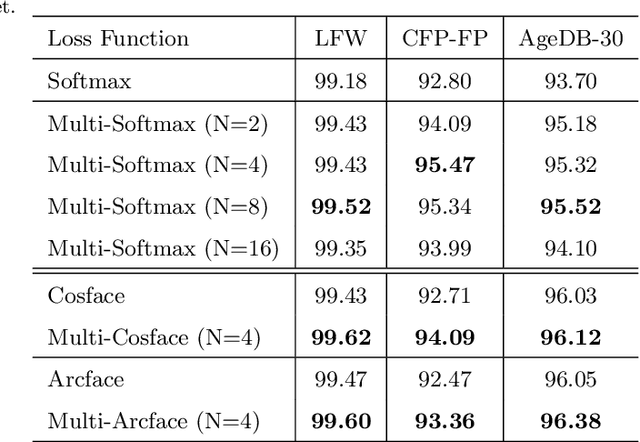
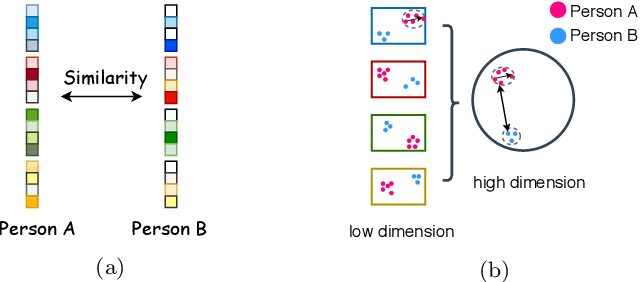
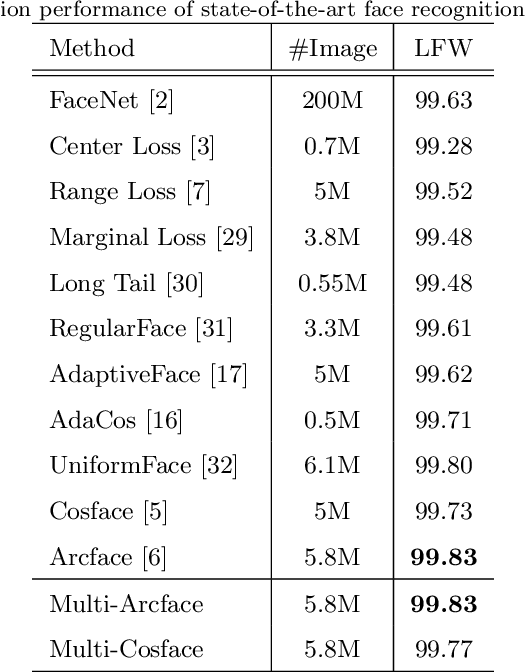
Deep Convolutional Neural Networks (DCNNs) and their variants have been widely used in large scale face recognition(FR) recently. Existing methods have achieved good performance on many FR benchmarks. However, most of them suffer from two major problems. First, these methods converge quite slowly since they optimize the loss functions in a high-dimensional and sparse Gaussian Sphere. Second, the high dimensionality of features, despite the powerful descriptive ability, brings difficulty to the optimization, which may lead to a sub-optimal local optimum. To address these problems, we propose a simple yet efficient training mechanism called MultiFace, where we approximate the original high-dimensional features by the ensemble of low-dimensional features. The proposed mechanism is also generic and can be easily applied to many advanced FR models. Moreover, it brings the benefits of good interpretability to FR models via the clustering effect. In detail, the ensemble of these low-dimensional features can capture complementary yet discriminative information, which can increase the intra-class compactness and inter-class separability. Experimental results show that the proposed mechanism can accelerate 2-3 times with the softmax loss and 1.2-1.5 times with Arcface or Cosface, while achieving state-of-the-art performances in several benchmark datasets. Especially, the significant improvements on large-scale datasets(e.g., IJB and MageFace) demonstrate the flexibility of our new training mechanism.
Reliable Evaluations for Natural Language Inference based on a Unified Cross-dataset Benchmark
Oct 15, 2020
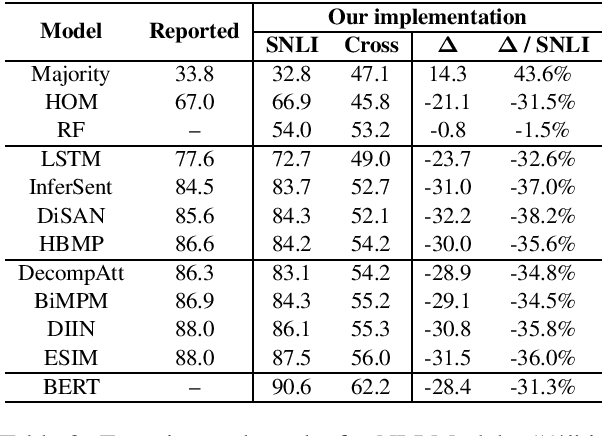
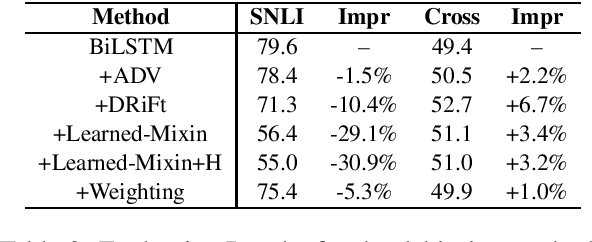
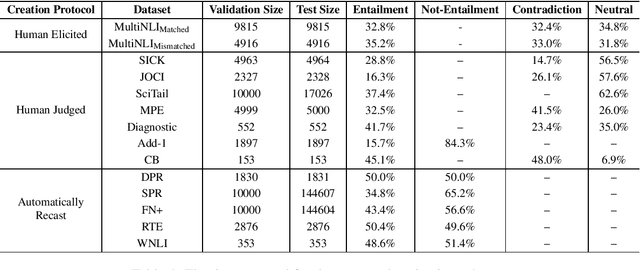
Recent studies show that crowd-sourced Natural Language Inference (NLI) datasets may suffer from significant biases like annotation artifacts. Models utilizing these superficial clues gain mirage advantages on the in-domain testing set, which makes the evaluation results over-estimated. The lack of trustworthy evaluation settings and benchmarks stalls the progress of NLI research. In this paper, we propose to assess a model's trustworthy generalization performance with cross-datasets evaluation. We present a new unified cross-datasets benchmark with 14 NLI datasets, and re-evaluate 9 widely-used neural network-based NLI models as well as 5 recently proposed debiasing methods for annotation artifacts. Our proposed evaluation scheme and experimental baselines could provide a basis to inspire future reliable NLI research.
Domain Agnostic Learning for Unbiased Authentication
Oct 11, 2020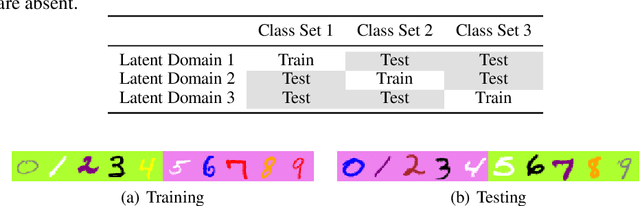
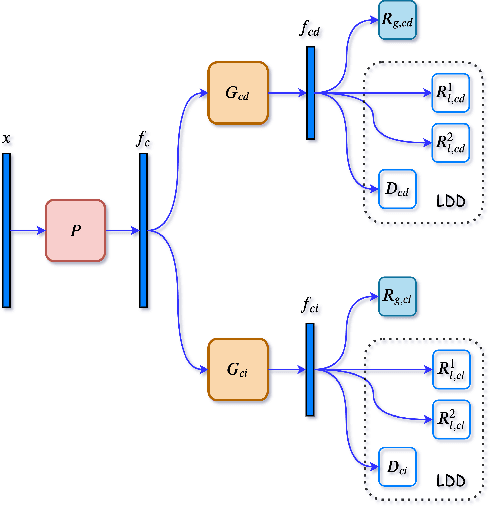
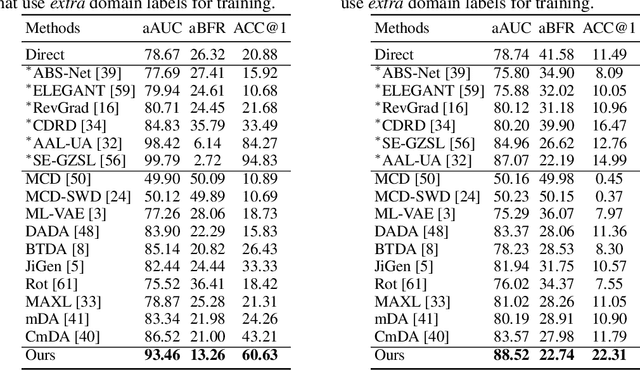

Authentication is the task of confirming the matching relationship between a data instance and a given identity. Typical examples of authentication problems include face recognition and person re-identification. Data-driven authentication could be affected by undesired biases, i.e., the models are often trained in one domain (e.g., for people wearing spring outfits) while applied in other domains (e.g., they change the clothes to summer outfits). Previous works have made efforts to eliminate domain-difference. They typically assume domain annotations are provided, and all the domains share classes. However, for authentication, there could be a large number of domains shared by different identities/classes, and it is impossible to annotate these domains exhaustively. It could make domain-difference challenging to model and eliminate. In this paper, we propose a domain-agnostic method that eliminates domain-difference without domain labels. We alternately perform latent domain discovery and domain-difference elimination until our model no longer detects domain-difference. In our approach, the latent domains are discovered by learning the heterogeneous predictive relationships between inputs and outputs. Then domain-difference is eliminated in both class-dependent and class-independent components. Comprehensive empirical evaluation results are provided to demonstrate the effectiveness and superiority of our proposed method.
Hybrid Differentially Private Federated Learning on Vertically Partitioned Data
Sep 06, 2020
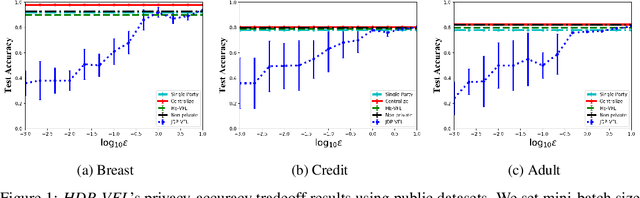
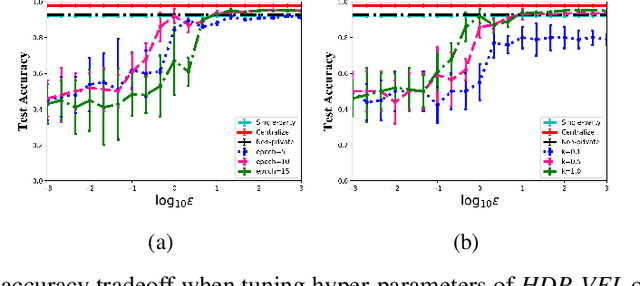

We present HDP-VFL, the first hybrid differentially private (DP) framework for vertical federated learning (VFL) to demonstrate that it is possible to jointly learn a generalized linear model (GLM) from vertically partitioned data with only a negligible cost, w.r.t. training time, accuracy, etc., comparing to idealized non-private VFL. Our work builds on the recent advances in VFL-based collaborative training among different organizations which rely on protocols like Homomorphic Encryption (HE) and Secure Multi-Party Computation (MPC) to secure computation and training. In particular, we analyze how VFL's intermediate result (IR) can leak private information of the training data during communication and design a DP-based privacy-preserving algorithm to ensure the data confidentiality of VFL participants. We mathematically prove that our algorithm not only provides utility guarantees for VFL, but also offers multi-level privacy, i.e. DP w.r.t. IR and joint differential privacy (JDP) w.r.t. model weights. Experimental results demonstrate that our work, under adequate privacy budgets, is quantitatively and qualitatively similar to GLMs, learned in idealized non-private VFL setting, rather than the increased cost in memory and processing time in most prior works based on HE or MPC. Our codes will be released if this paper is accepted.
Two Sides of the Same Coin: White-box and Black-box Attacks for Transfer Learning
Aug 25, 2020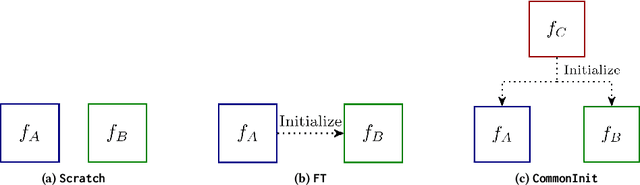
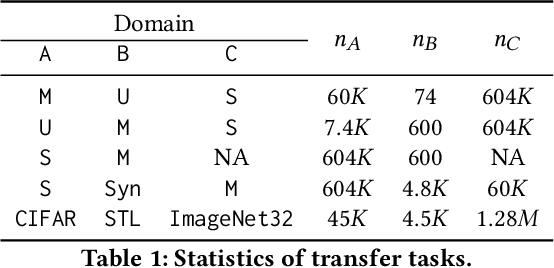
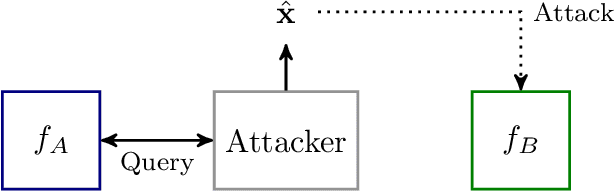
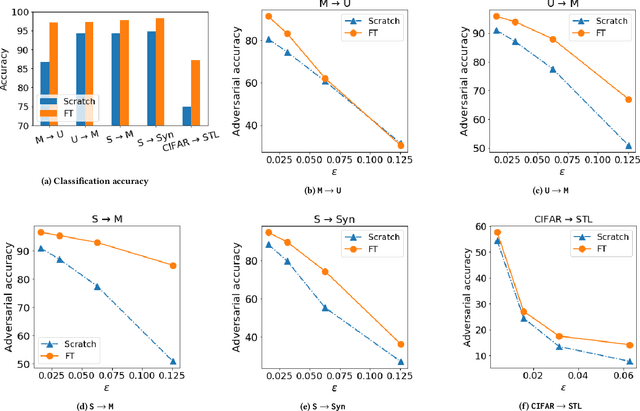
Transfer learning has become a common practice for training deep learning models with limited labeled data in a target domain. On the other hand, deep models are vulnerable to adversarial attacks. Though transfer learning has been widely applied, its effect on model robustness is unclear. To figure out this problem, we conduct extensive empirical evaluations to show that fine-tuning effectively enhances model robustness under white-box FGSM attacks. We also propose a black-box attack method for transfer learning models which attacks the target model with the adversarial examples produced by its source model. To systematically measure the effect of both white-box and black-box attacks, we propose a new metric to evaluate how transferable are the adversarial examples produced by a source model to a target model. Empirical results show that the adversarial examples are more transferable when fine-tuning is used than they are when the two networks are trained independently.