 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiFace: A Generic Training Mechanism for Boosting Face Recognition Performance
Jan 31, 2021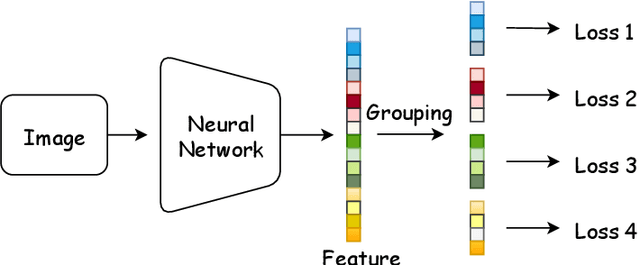
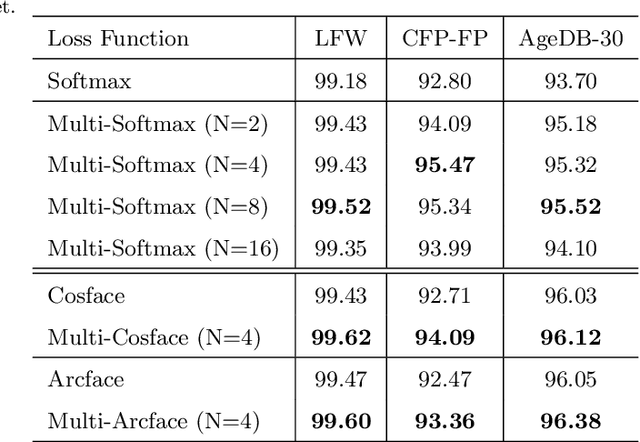
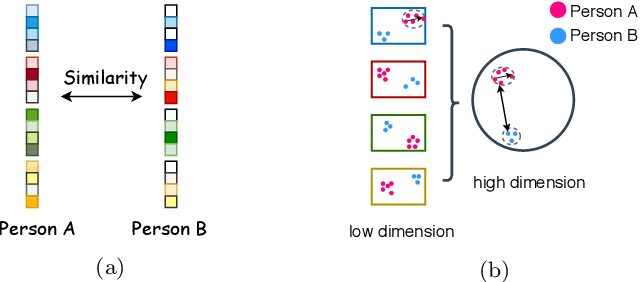
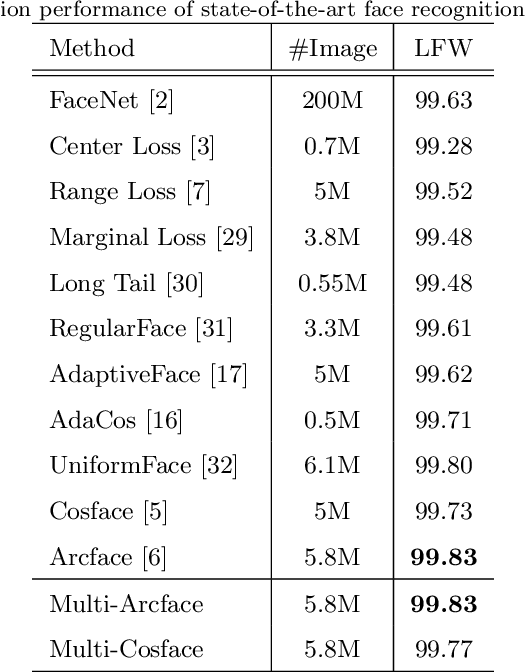
Deep Convolutional Neural Networks (DCNNs) and their variants have been widely used in large scale face recognition(FR) recently. Existing methods have achieved good performance on many FR benchmarks. However, most of them suffer from two major problems. First, these methods converge quite slowly since they optimize the loss functions in a high-dimensional and sparse Gaussian Sphere. Second, the high dimensionality of features, despite the powerful descriptive ability, brings difficulty to the optimization, which may lead to a sub-optimal local optimum. To address these problems, we propose a simple yet efficient training mechanism called MultiFace, where we approximate the original high-dimensional features by the ensemble of low-dimensional features. The proposed mechanism is also generic and can be easily applied to many advanced FR models. Moreover, it brings the benefits of good interpretability to FR models via the clustering effect. In detail, the ensemble of these low-dimensional features can capture complementary yet discriminative information, which can increase the intra-class compactness and inter-class separability. Experimental results show that the proposed mechanism can accelerate 2-3 times with the softmax loss and 1.2-1.5 times with Arcface or Cosface, while achieving state-of-the-art performances in several benchmark datasets. Especially, the significant improvements on large-scale datasets(e.g., IJB and MageFace) demonstrate the flexibility of our new training mechanism.
Improving Reinforcement Learning Based Image Captioning with Natural Language Prior
Sep 13, 2018

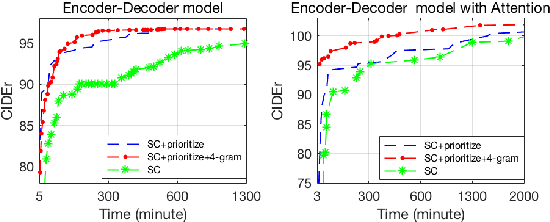
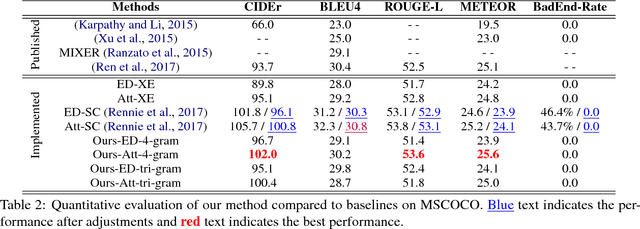
Recently, Reinforcement Learning (RL) approaches have demonstrated advanced performance in image captioning by directly optimizing the metric used for testing. However, this shaped reward introduces learning biases, which reduces the readability of generated text. In addition, the large sample space makes training unstable and slow. To alleviate these issues, we propose a simple coherent solution that constrains the action space using an n-gram language prior. Quantitative and qualitative evaluations on benchmarks show that RL with the simple add-on module performs favorably against its counterpart in terms of both readability and speed of convergence. Human evaluation results show that our model is more human readable and graceful. The implementation will become publicly available upon the acceptance of the paper.