 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Reinforcement Learning Based Image Captioning with Natural Language Prior
Paper and Code


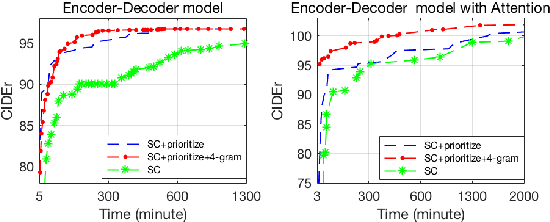
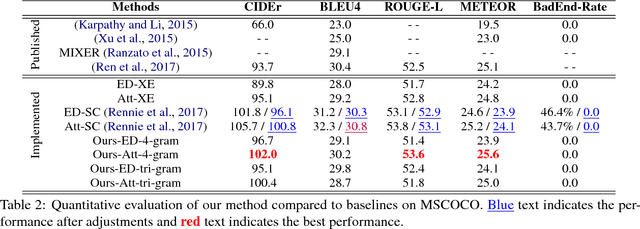
Recently, Reinforcement Learning (RL) approaches have demonstrated advanced performance in image captioning by directly optimizing the metric used for testing. However, this shaped reward introduces learning biases, which reduces the readability of generated text. In addition, the large sample space makes training unstable and slow. To alleviate these issues, we propose a simple coherent solution that constrains the action space using an n-gram language prior. Quantitative and qualitative evaluations on benchmarks show that RL with the simple add-on module performs favorably against its counterpart in terms of both readability and speed of convergence. Human evaluation results show that our model is more human readable and graceful. The implementation will become publicly available upon the acceptance of the paper.