 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Contrastive Learning for Sequential Recommendation with Similarity-based Positive Pair Selection
Apr 27, 2025Contrastive Learning (CL) enhances the training of sequential recommendation (SR) models through informative self-supervision signals. Existing methods often rely on data augmentation strategies to create positive samples and promote representation invariance. Some strategies such as item reordering and item substitution may inadvertently alter user intent. Supervised Contrastive Learning (SCL) based methods find an alternative to augmentation-based CL methods by selecting same-target sequences (interaction sequences with the same target item) to form positive samples. However, SCL-based methods suffer from the scarcity of same-target sequences and consequently lack enough signals for contrastive learning. In this work, we propose to use similar sequences (with different target items) as additional positive samples and introduce a Relative Contrastive Learning (RCL) framework for sequential recommendation. RCL comprises a dual-tiered positive sample selection module and a relative contrastive learning module. The former module selects same-target sequences as strong positive samples and selects similar sequences as weak positive samples. The latter module employs a weighted relative contrastive loss, ensuring that each sequence is represented closer to its strong positive samples than its weak positive samples. We apply RCL on two mainstream deep learning-based SR models, and our empirical results reveal that RCL can achieve 4.88% improvement averagely than the state-of-the-art SR methods on five public datasets and one private dataset.
Cross-domain Cross-architecture Black-box Attacks on Fine-tuned Models with Transferred Evolutionary Strategies
Aug 28, 2022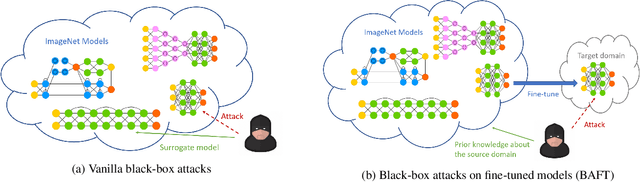
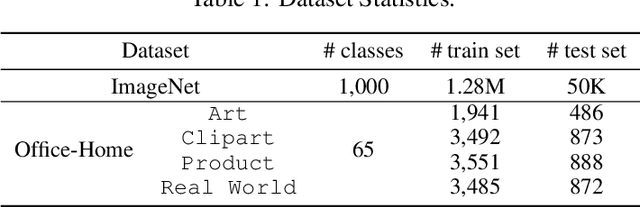
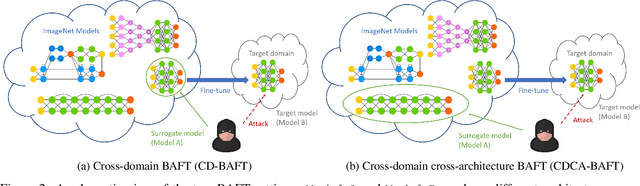

Fine-tuning can be vulnerable to adversarial attacks. Existing works about black-box attacks on fine-tuned models (BAFT) are limited by strong assumptions. To fill the gap, we propose two novel BAFT settings, cross-domain and cross-domain cross-architecture BAFT, which only assume that (1) the target model for attacking is a fine-tuned model, and (2) the source domain data is known and accessible. To successfully attack fine-tuned models under both settings, we propose to first train an adversarial generator against the source model, which adopts an encoder-decoder architecture and maps a clean input to an adversarial example. Then we search in the low-dimensional latent space produced by the encoder of the adversarial generator. The search is conducted under the guidance of the surrogate gradient obtained from the source model. Experimental results on different domains and different network architectures demonstrate that the proposed attack method can effectively and efficiently attack the fine-tuned models.
Two Sides of the Same Coin: White-box and Black-box Attacks for Transfer Learning
Aug 25, 2020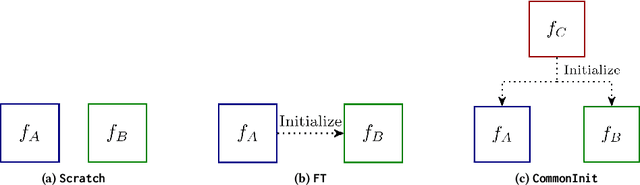
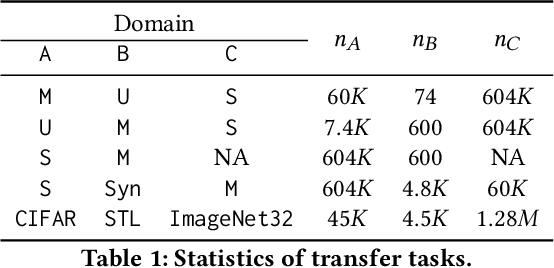
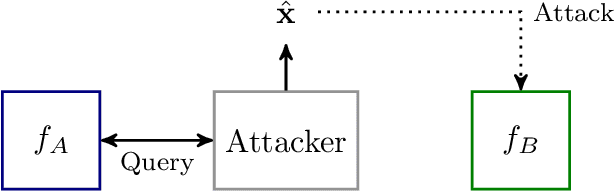
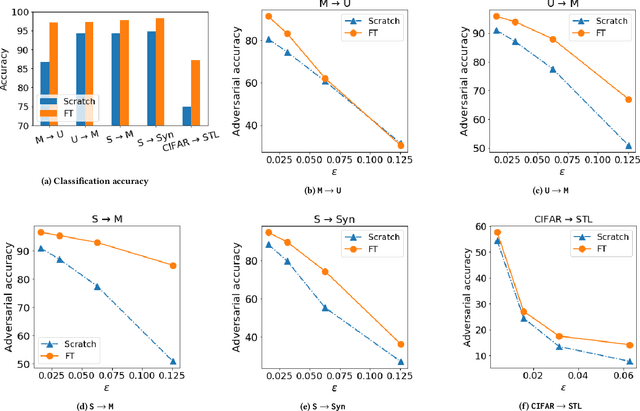
Transfer learning has become a common practice for training deep learning models with limited labeled data in a target domain. On the other hand, deep models are vulnerable to adversarial attacks. Though transfer learning has been widely applied, its effect on model robustness is unclear. To figure out this problem, we conduct extensive empirical evaluations to show that fine-tuning effectively enhances model robustness under white-box FGSM attacks. We also propose a black-box attack method for transfer learning models which attacks the target model with the adversarial examples produced by its source model. To systematically measure the effect of both white-box and black-box attacks, we propose a new metric to evaluate how transferable are the adversarial examples produced by a source model to a target model. Empirical results show that the adversarial examples are more transferable when fine-tuning is used than they are when the two networks are trained independently.
Fisher Deep Domain Adaptation
Mar 12, 2020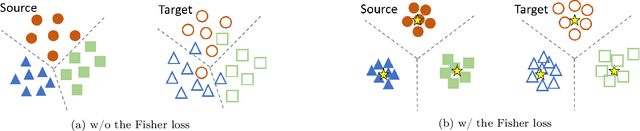



Deep domain adaptation models learn a neural network in an unlabeled target domain by leveraging the knowledge from a labeled source domain. This can be achieved by learning a domain-invariant feature space. Though the learned representations are separable in the source domain, they usually have a large variance and samples with different class labels tend to overlap in the target domain, which yields suboptimal adaptation performance. To fill the gap, a Fisher loss is proposed to learn discriminative representations which are within-class compact and between-class separable. Experimental results on two benchmark datasets show that the Fisher loss is a general and effective loss for deep domain adaptation. Noticeable improvements are brought when it is used together with widely adopted transfer criteria, including MMD, CORAL and domain adversarial loss. For example, an absolute improvement of 6.67% in terms of the mean accuracy is attained when the Fisher loss is used together with the domain adversarial loss on the Office-Home dataset.
Parameter Transfer Unit for Deep Neural Networks
Apr 23, 2018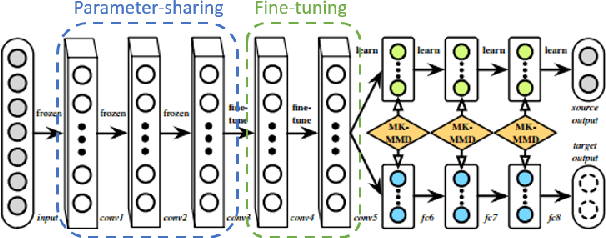
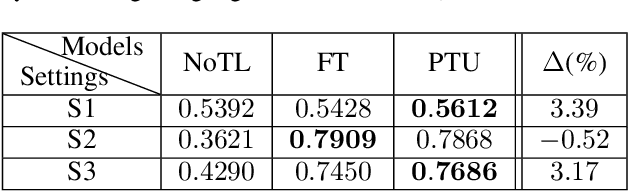

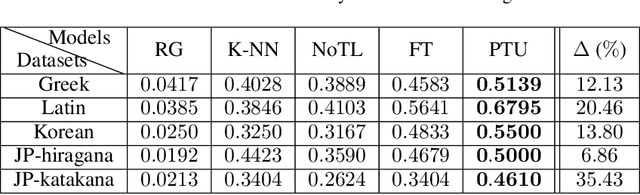
Parameters in deep neural networks which are trained on large-scale databases can generalize across multiple domains, which is referred as "transferability". Unfortunately, the transferability is usually defined as discrete states and it differs with domains and network architectures. Existing works usually heuristically apply parameter-sharing or fine-tuning, and there is no principled approach to learn a parameter transfer strategy. To address the gap, a parameter transfer unit (PTU) is proposed in this paper. The PTU learns a fine-grained nonlinear combination of activations from both the source and the target domain networks, and subsumes hand-crafted discrete transfer states. In the PTU, the transferability is controlled by two gates which are artificial neurons and can be learned from data. The PTU is a general and flexible module which can be used in both CNNs and RNNs. Experiments are conducted with various network architectures and multiple transfer domain pairs. Results demonstrate the effectiveness of the PTU as it outperforms heuristic parameter-sharing and fine-tuning in most settings.