 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Transfer Unit for Deep Neural Networks
Paper and Code
Apr 23, 2018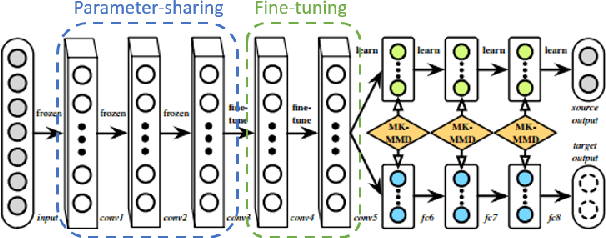
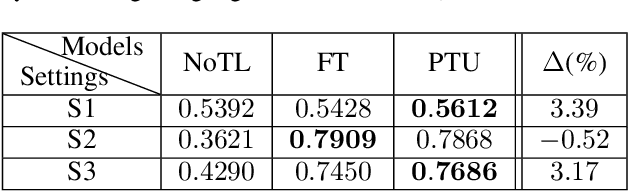

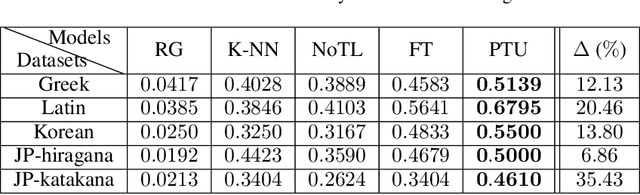
Parameters in deep neural networks which are trained on large-scale databases can generalize across multiple domains, which is referred as "transferability". Unfortunately, the transferability is usually defined as discrete states and it differs with domains and network architectures. Existing works usually heuristically apply parameter-sharing or fine-tuning, and there is no principled approach to learn a parameter transfer strategy. To address the gap, a parameter transfer unit (PTU) is proposed in this paper. The PTU learns a fine-grained nonlinear combination of activations from both the source and the target domain networks, and subsumes hand-crafted discrete transfer states. In the PTU, the transferability is controlled by two gates which are artificial neurons and can be learned from data. The PTU is a general and flexible module which can be used in both CNNs and RNNs. Experiments are conducted with various network architectures and multiple transfer domain pairs. Results demonstrate the effectiveness of the PTU as it outperforms heuristic parameter-sharing and fine-tuning in most settings.