 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comprehensive framework for occluded human pose estimation
Jan 09, 2024Occlusion presents a significant challenge in human pose estimation. The challenges posed by occlusion can be attributed to the following factors: 1) Data: The collection and annotation of occluded human pose samples are relatively challenging. 2) Feature: Occlusion can cause feature confusion due to the high similarity between the target person and interfering individuals. 3) Inference: Robust inference becomes challenging due to the loss of complete body structural information. The existing methods designed for occluded human pose estimation usually focus on addressing only one of these factors. In this paper, we propose a comprehensive framework DAG (Data, Attention, Graph) to address the performance degradation caused by occlusion. Specifically, we introduce the mask joints with instance paste data augmentation technique to simulate occlusion scenarios. Additionally, an Adaptive Discriminative Attention Module (ADAM) is proposed to effectively enhance the features of target individuals. Furthermore, we present the Feature-Guided Multi-Hop GCN (FGMP-GCN) to fully explore the prior knowledge of body structure and improve pose estimation results. Through extensive experiments conducted on three benchmark datasets for occluded human pose estimation, we demonstrate that the proposed method outperforms existing methods. Code and data will be publicly available.
Towards High Performance One-Stage Human Pose Estimation
Jan 12, 2023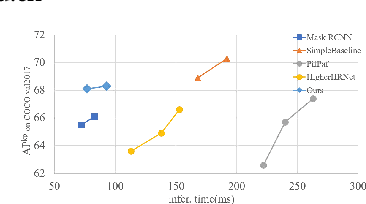



Making top-down human pose estimation method present both good performance and high efficiency is appealing. Mask RCNN can largely improve the efficiency by conducting person detection and pose estimation in a single framework, as the features provided by the backbone are able to be shared by the two tasks. However, the performance is not as good as traditional two-stage methods. In this paper, we aim to largely advance the human pose estimation results of Mask-RCNN and still keep the efficiency. Specifically, we make improvements on the whole process of pose estimation, which contains feature extraction and keypoint detection. The part of feature extraction is ensured to get enough and valuable information of pose. Then, we introduce a Global Context Module into the keypoints detection branch to enlarge the receptive field, as it is crucial to successful human pose estimation. On the COCO val2017 set, our model using the ResNet-50 backbone achieves an AP of 68.1, which is 2.6 higher than Mask RCNN (AP of 65.5). Compared to the classic two-stage top-down method SimpleBaseline, our model largely narrows the performance gap (68.1 AP vs. 68.9 AP) with a much faster inference speed (77 ms vs. 168 ms), demonstrating the effectiveness of the proposed method. Code is available at: https://github.com/lingl_space/maskrcnn_keypoint_refined.
* 5 pages, 5 figures, accepted at ACM Multimedia Asia (MMAsia) 2022