Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA SOM-based Gradient-Free Deep Learning Method with Convergence Analysis
Paper and Code
Jan 12, 2021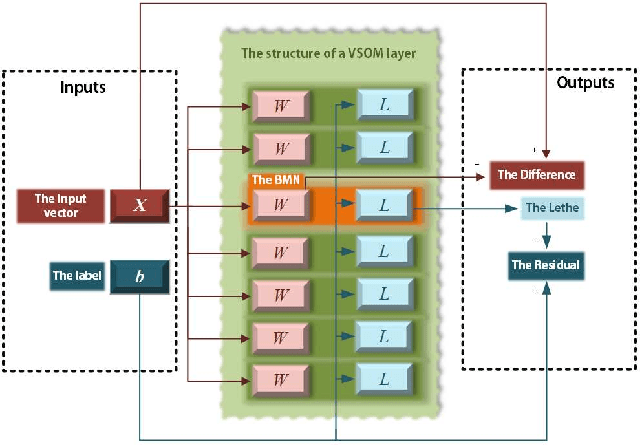
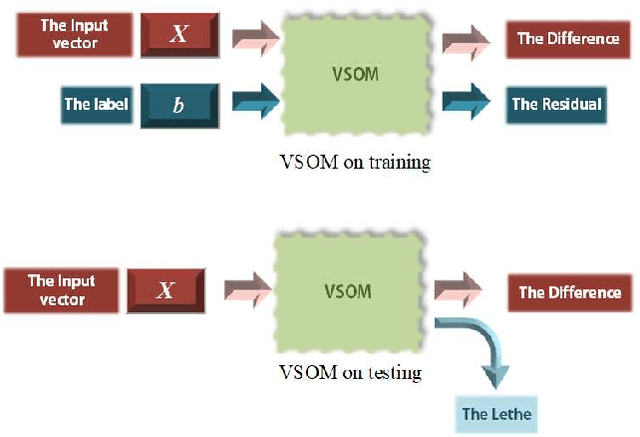
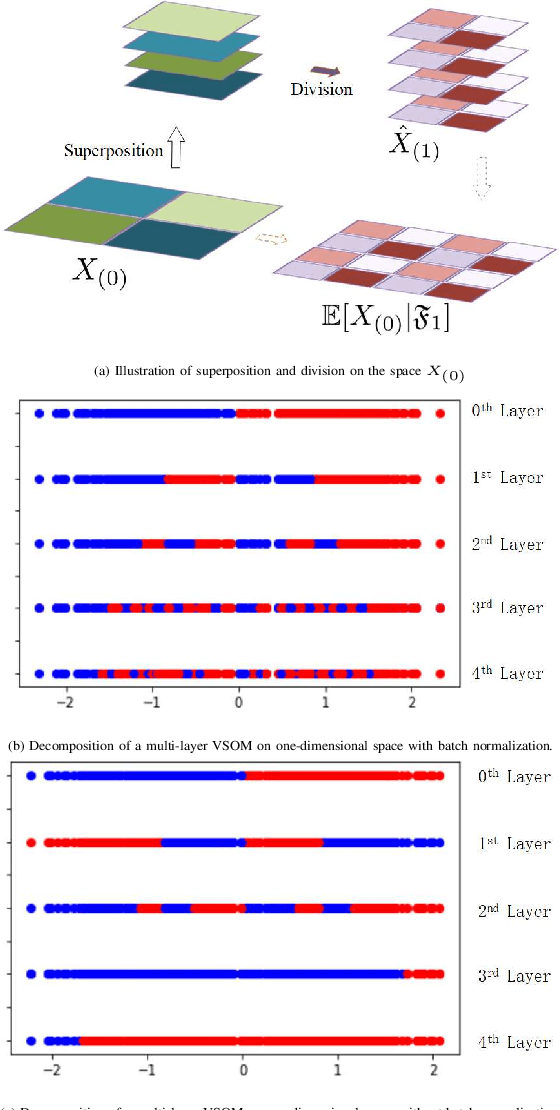
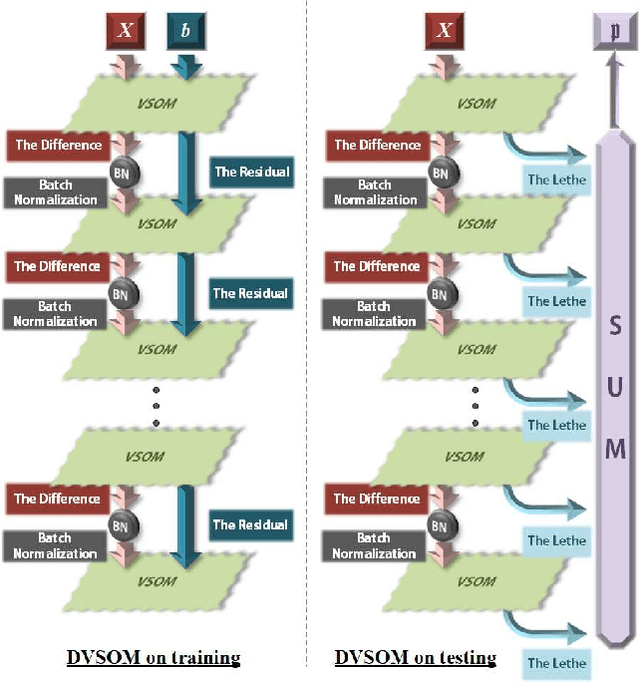
As gradient descent method in deep learning causes a series of questions, this paper proposes a novel gradient-free deep learning structure. By adding a new module into traditional Self-Organizing Map and introducing residual into the map, a Deep Valued Self-Organizing Map network is constructed. And analysis about the convergence performance of such a deep Valued Self-Organizing Map network is proved in this paper, which gives an inequality about the designed parameters with the dimension of inputs and the loss of prediction.
View paper on