 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGDFormer: One-stage Transformer-based Architecture for Cross-Spectral Stereo Image Guided Denoising
Mar 30, 2024



Cross-spectral image guided denoising has shown its great potential in recovering clean images with rich details, such as using the near-infrared image to guide the denoising process of the visible one. To obtain such image pairs, a feasible and economical way is to employ a stereo system, which is widely used on mobile devices. Current works attempt to generate an aligned guidance image to handle the disparity between two images. However, due to occlusion, spectral differences and noise degradation, the aligned guidance image generally exists ghosting and artifacts, leading to an unsatisfactory denoised result. To address this issue, we propose a one-stage transformer-based architecture, named SGDFormer, for cross-spectral Stereo image Guided Denoising. The architecture integrates the correspondence modeling and feature fusion of stereo images into a unified network. Our transformer block contains a noise-robust cross-attention (NRCA) module and a spatially variant feature fusion (SVFF) module. The NRCA module captures the long-range correspondence of two images in a coarse-to-fine manner to alleviate the interference of noise. The SVFF module further enhances salient structures and suppresses harmful artifacts through dynamically selecting useful information. Thanks to the above design, our SGDFormer can restore artifact-free images with fine structures, and achieves state-of-the-art performance on various datasets. Additionally, our SGDFormer can be extended to handle other unaligned cross-model guided restoration tasks such as guided depth super-resolution.
TFDet: Target-aware Fusion for RGB-T Pedestrian Detection
May 26, 2023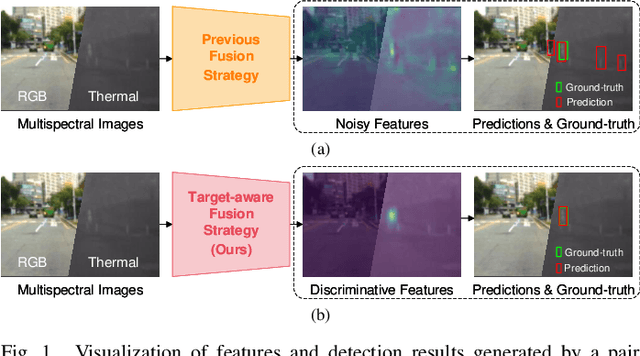
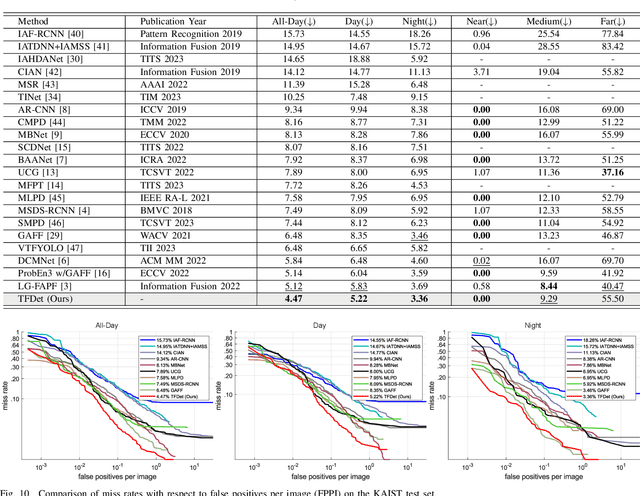

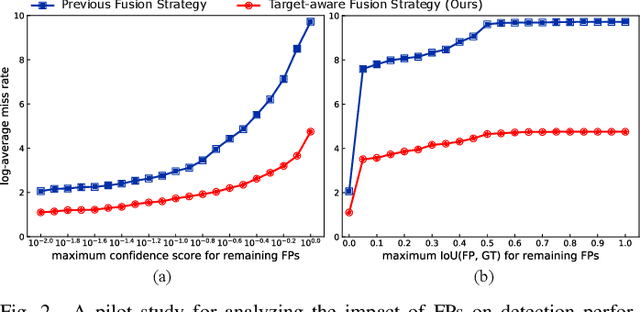
Pedestrian detection is a critical task in computer vision because of its role in ensuring traffic safety. However, existing methods that rely solely on RGB images suffer from performance degradation under low-light conditions due to the lack of useful information. To address this issue, recent multispectral detection approaches combine thermal images to provide complementary information. Nevertheless, these approaches have limitations such as the noisy fused feature maps and the loss of informative features. In this paper, we propose a novel target-aware fusion strategy for multispectral pedestrian detection, named TFDet. Unlike existing methods, TFDet enhances features by supervising the fusion process with a correlation-maximum loss function. Our fusion strategy highlights the pedestrian-related features while suppressing the unrelated ones. TFDet achieves state-of-the-art performances on both KAIST and LLVIP benchmarks, with a speed comparable to the previous state-of-the-art counterpart. Importantly, TFDet performs remarkably well under low-light conditions, which is a significant advancement for road safety.
Iterative Deep Homography Estimation
Mar 30, 2022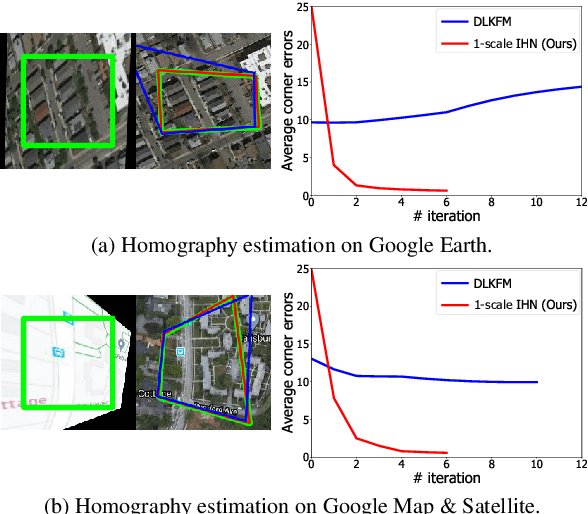
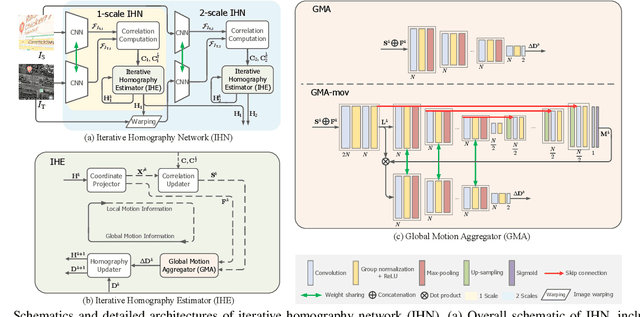
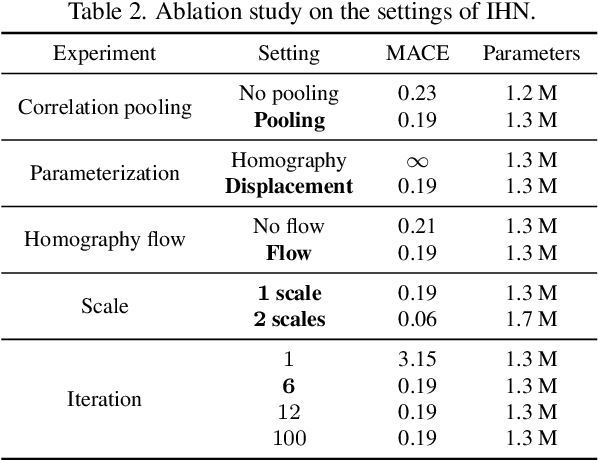
We propose Iterative Homography Network, namely IHN, a new deep homography estimation architecture. Different from previous works that achieve iterative refinement by network cascading or untrainable IC-LK iterator, the iterator of IHN has tied weights and is completely trainable. IHN achieves state-of-the-art accuracy on several datasets including challenging scenes. We propose 2 versions of IHN: (1) IHN for static scenes, (2) IHN-mov for dynamic scenes with moving objects. Both versions can be arranged in 1-scale for efficiency or 2-scale for accuracy. We show that the basic 1-scale IHN already outperforms most of the existing methods. On a variety of datasets, the 2-scale IHN outperforms all competitors by a large gap. We introduce IHN-mov by producing an inlier mask to further improve the estimation accuracy of moving-objects scenes. We experimentally show that the iterative framework of IHN can achieve 95% error reduction while considerably saving network parameters. When processing sequential image pairs, IHN can achieve 32.7 fps, which is about 8x the speed of IC-LK iterator. Source code is available at https://github.com/imdumpl78/IHN.