Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExARN: self-attending RNN for target speaker extraction
Paper and Code
Dec 02, 2022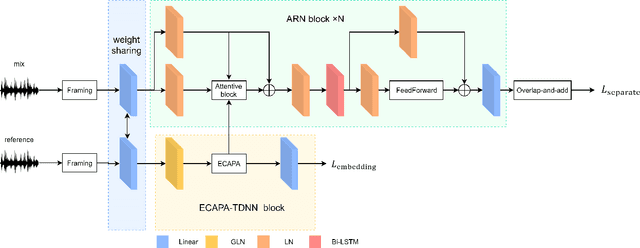
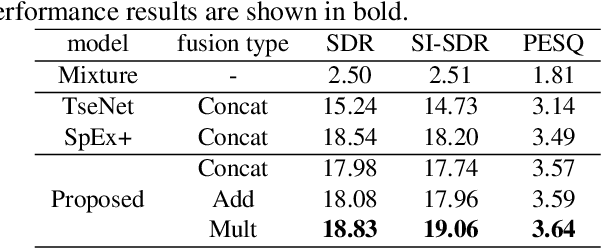
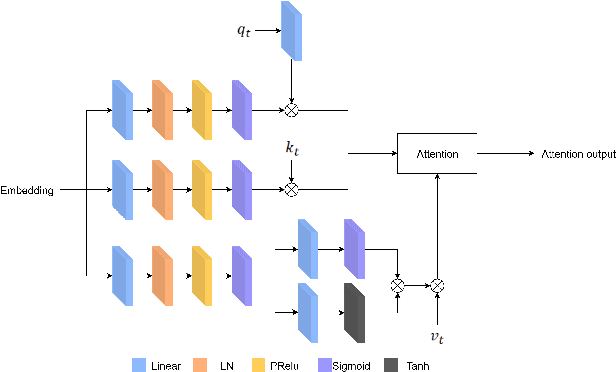
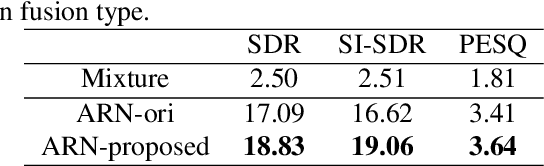
Target speaker extraction is to extract the target speaker, specified by enrollment utterance, in an environment with other competing speakers. Therefore, the task needs to solve two problems, speaker identification and separation, at the same time. In this paper, we combine self-attention and Recurrent Neural Networks (RNN). Further, we exploit various ways to combining different auxiliary information with mixed representations. Experimental results show that our proposed model achieves excellent performance on the task of target speaker extraction.
* Submitted to ICASSP 2023, 5 pages with 3 figures
View paper on