 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning the Evaluation of Probabilistic Predictions with Downstream Value
Aug 25, 2025Every prediction is ultimately used in a downstream task. Consequently, evaluating prediction quality is more meaningful when considered in the context of its downstream use. Metrics based solely on predictive performance often diverge from measures of real-world downstream impact. Existing approaches incorporate the downstream view by relying on multiple task-specific metrics, which can be burdensome to analyze, or by formulating cost-sensitive evaluations that require an explicit cost structure, typically assumed to be known a priori. We frame this mismatch as an evaluation alignment problem and propose a data-driven method to learn a proxy evaluation function aligned with the downstream evaluation. Building on the theory of proper scoring rules, we explore transformations of scoring rules that ensure the preservation of propriety. Our approach leverages weighted scoring rules parametrized by a neural network, where weighting is learned to align with the performance in the downstream task. This enables fast and scalable evaluation cycles across tasks where the weighting is complex or unknown a priori. We showcase our framework through synthetic and real-data experiments for regression tasks, demonstrating its potential to bridge the gap between predictive evaluation and downstream utility in modular prediction systems.
Improving Calibration by Relating Focal Loss, Temperature Scaling, and Properness
Aug 21, 2024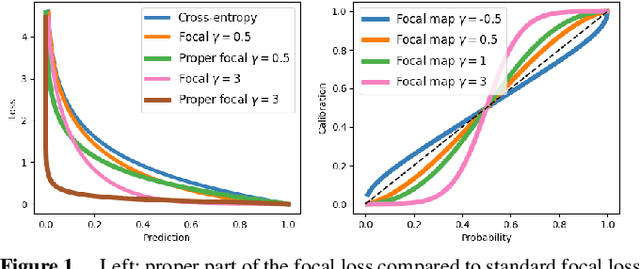
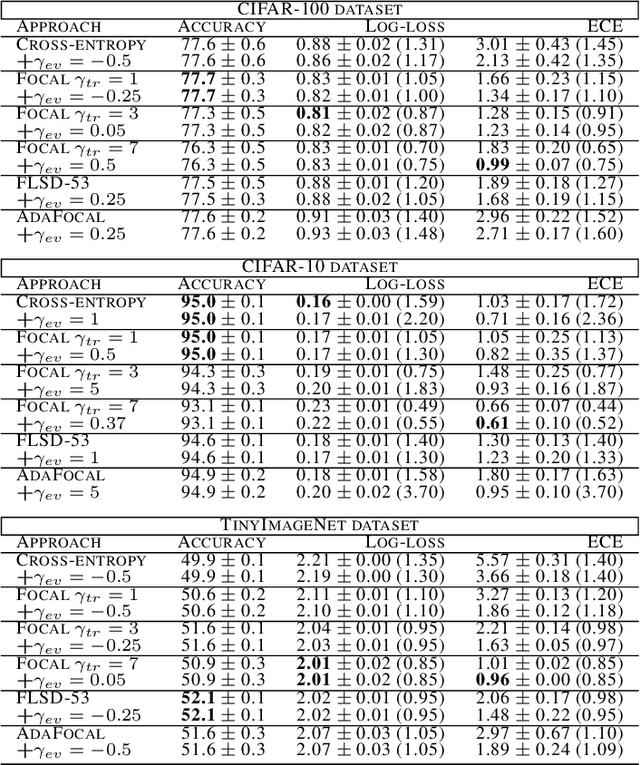
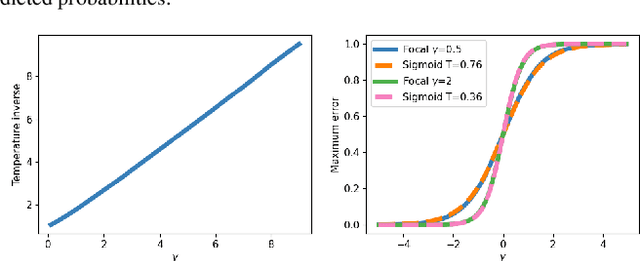

Proper losses such as cross-entropy incentivize classifiers to produce class probabilities that are well-calibrated on the training data. Due to the generalization gap, these classifiers tend to become overconfident on the test data, mandating calibration methods such as temperature scaling. The focal loss is not proper, but training with it has been shown to often result in classifiers that are better calibrated on test data. Our first contribution is a simple explanation about why focal loss training often leads to better calibration than cross-entropy training. For this, we prove that focal loss can be decomposed into a confidence-raising transformation and a proper loss. This is why focal loss pushes the model to provide under-confident predictions on the training data, resulting in being better calibrated on the test data, due to the generalization gap. Secondly, we reveal a strong connection between temperature scaling and focal loss through its confidence-raising transformation, which we refer to as the focal calibration map. Thirdly, we propose focal temperature scaling - a new post-hoc calibration method combining focal calibration and temperature scaling. Our experiments on three image classification datasets demonstrate that focal temperature scaling outperforms standard temperature scaling.
Correlated daily time series and forecasting in the M4 competition
Mar 31, 2020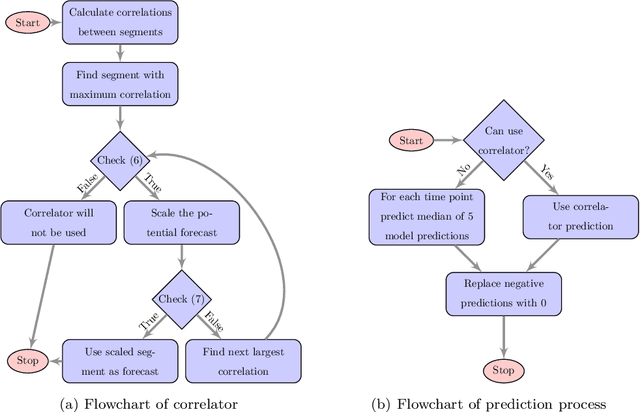
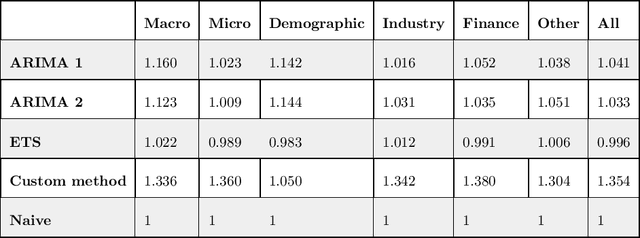
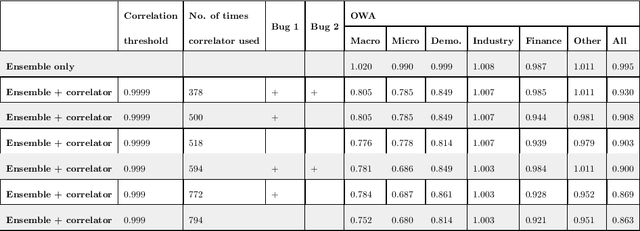
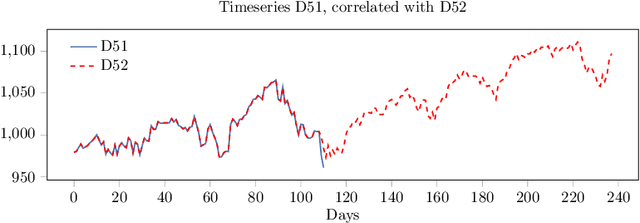
We participated in the M4 competition for time series forecasting and describe here our methods for forecasting daily time series. We used an ensemble of five statistical forecasting methods and a method that we refer to as the correlator. Our retrospective analysis using the ground truth values published by the M4 organisers after the competition demonstrates that the correlator was responsible for most of our gains over the naive constant forecasting method. We identify data leakage as one reason for its success, partly due to test data selected from different time intervals, and partly due to quality issues in the original time series. We suggest that future forecasting competitions should provide actual dates for the time series so that some of those leakages could be avoided by the participants.