 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Performance Sequence-to-Sequence Model for Streaming Speech Recognition
Paper and Code
Mar 22, 2020
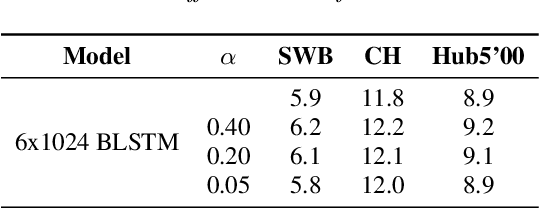


Recently sequence-to-sequence models have started to achieve state-of-the art performance on standard speech recognition tasks when processing audio data in batch mode, i.e., the complete audio data is available when starting processing. However, when it comes to perform run-on recognition on an input stream of audio data while producing recognition results in real-time and with a low word-based latency, these models face several challenges. For many techniques, the whole audio sequence to be decoded needs to be available at the start of the processing, e.g., for the attention mechanism or for the bidirectional LSTM (BLSTM). In this paper we propose several techniques to mitigate these problems. We introduce an additional loss function controlling the uncertainty of the attention mechanism, a modified beam search identifying partial, stable hypotheses, ways of working with BLSTM in the encoder, and the use of chunked BLSTM. Our experiments show that with the right combination of these techniques it is possible to perform run-on speech recognition with a low word-based latency without sacrificing performance in terms of word error rate.