 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian multilingual topic model for zero-shot cross-lingual topic identification
Paper and Code
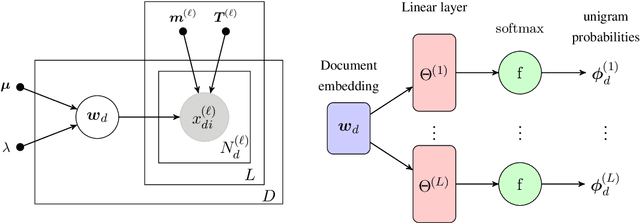


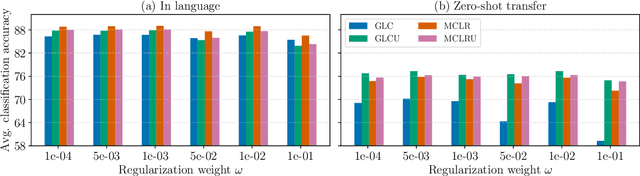
This paper presents a Bayesian multilingual topic model for learning language-independent document embeddings. Our model learns to represent the documents in the form of Gaussian distributions, thereby encoding the uncertainty in its covariance. We propagate the learned uncertainties through linear classifiers for zero-shot cross-lingual topic identification. Our experiments on 5 language Europarl and Reuters (MLDoc) corpora show that the proposed model outperforms multi-lingual word embedding and BiLSTM sentence encoder based systems with significant margins in the majority of the transfer directions. Moreover, our system trained under a single day on a single GPU with much lower amounts of data performs competitively as compared to the state-of-the-art universal BiLSTM sentence encoder trained on 93 languages. Our experimental analysis shows that the amount of parallel data improves the overall performance of embeddings. Nonetheless, exploiting the uncertainties is always beneficial.