 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere to Look Next: Learning Viewpoint Recommendations for Informative Trajectory Planning
Mar 04, 2022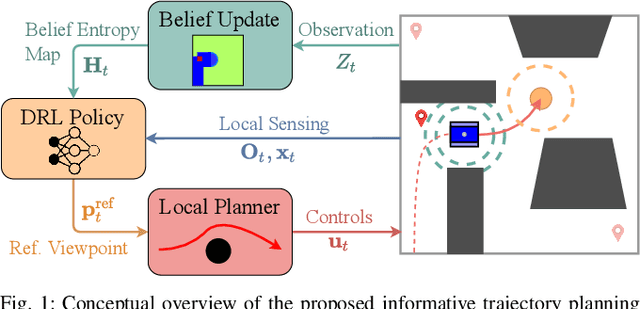



Search missions require motion planning and navigation methods for information gathering that continuously replan based on new observations of the robot's surroundings. Current methods for information gathering, such as Monte Carlo Tree Search, are capable of reasoning over long horizons, but they are computationally expensive. An alternative for fast online execution is to train, offline, an information gathering policy, which indirectly reasons about the information value of new observations. However, these policies lack safety guarantees and do not account for the robot dynamics. To overcome these limitations we train an information-aware policy via deep reinforcement learning, that guides a receding-horizon trajectory optimization planner. In particular, the policy continuously recommends a reference viewpoint to the local planner, such that the resulting dynamically feasible and collision-free trajectories lead to observations that maximize the information gain and reduce the uncertainty about the environment. In simulation tests in previously unseen environments, our method consistently outperforms greedy next-best-view policies and achieves competitive performance compared to Monte Carlo Tree Search, in terms of information gains and coverage time, with a reduction in execution time by three orders of magnitude.