 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Sustainable Energy: A Survey
Jul 26, 2024



The transition to sustainable energy is a key challenge of our time, requiring modifications in the entire pipeline of energy production, storage, transmission, and consumption. At every stage, new sequential decision-making challenges emerge, ranging from the operation of wind farms to the management of electrical grids or the scheduling of electric vehicle charging stations. All such problems are well suited for reinforcement learning, the branch of machine learning that learns behavior from data. Therefore, numerous studies have explored the use of reinforcement learning for sustainable energy. This paper surveys this literature with the intention of bridging both the underlying research communities: energy and machine learning. After a brief introduction of both fields, we systematically list relevant sustainability challenges, how they can be modeled as a reinforcement learning problem, and what solution approaches currently exist in the literature. Afterwards, we zoom out and identify overarching reinforcement learning themes that appear throughout sustainability, such as multi-agent, offline, and safe reinforcement learning. Lastly, we also cover standardization of environments, which will be crucial for connecting both research fields, and highlight potential directions for future work. In summary, this survey provides an extensive overview of reinforcement learning methods for sustainable energy, which may play a vital role in the energy transition.
Interaction-Aware Sampling-Based MPC with Learned Local Goal Predictions
Sep 26, 2023Motion planning for autonomous robots in tight, interaction-rich, and mixed human-robot environments is challenging. State-of-the-art methods typically separate prediction and planning, predicting other agents' trajectories first and then planning the ego agent's motion in the remaining free space. However, agents' lack of awareness of their influence on others can lead to the freezing robot problem. We build upon Interaction-Aware Model Predictive Path Integral (IA-MPPI) control and combine it with learning-based trajectory predictions, thereby relaxing its reliance on communicated short-term goals for other agents. We apply this framework to Autonomous Surface Vessels (ASVs) navigating urban canals. By generating an artificial dataset in real sections of Amsterdam's canals, adapting and training a prediction model for our domain, and proposing heuristics to extract local goals, we enable effective cooperation in planning. Our approach improves autonomous robot navigation in complex, crowded environments, with potential implications for multi-agent systems and human-robot interaction.
A Framework for Fast Prototyping of Photo-realistic Environments with Multiple Pedestrians
Apr 14, 2023



Robotic applications involving people often require advanced perception systems to better understand complex real-world scenarios. To address this challenge, photo-realistic and physics simulators are gaining popularity as a means of generating accurate data labeling and designing scenarios for evaluating generalization capabilities, e.g., lighting changes, camera movements or different weather conditions. We develop a photo-realistic framework built on Unreal Engine and AirSim to generate easily scenarios with pedestrians and mobile robots. The framework is capable to generate random and customized trajectories for each person and provides up to 50 ready-to-use people models along with an API for their metadata retrieval. We demonstrate the usefulness of the proposed framework with a use case of multi-target tracking, a popular problem in real pedestrian scenarios. The notable feature variability in the obtained perception data is presented and evaluated.
Active Classification of Moving Targets with Learned Control Policies
Dec 07, 2022In this paper, we consider the problem where a drone has to collect semantic information to classify multiple moving targets. In particular, we address the challenge of computing control inputs that move the drone to informative viewpoints, position and orientation, when the information is extracted using a "black-box" classifier, e.g., a deep learning neural network. These algorithms typically lack of analytical relationships between the viewpoints and their associated outputs, preventing their use in information-gathering schemes. To fill this gap, we propose a novel attention-based architecture, trained via Reinforcement Learning (RL), that outputs the next viewpoint for the drone favoring the acquisition of evidence from as many unclassified targets as possible while reasoning about their movement, orientation, and occlusions. Then, we use a low-level MPC controller to move the drone to the desired viewpoint taking into account its actual dynamics. We show that our approach not only outperforms a variety of baselines but also generalizes to scenarios unseen during training. Additionally, we show that the network scales to large numbers of targets and generalizes well to different movement dynamics of the targets.
Where to Look Next: Learning Viewpoint Recommendations for Informative Trajectory Planning
Mar 04, 2022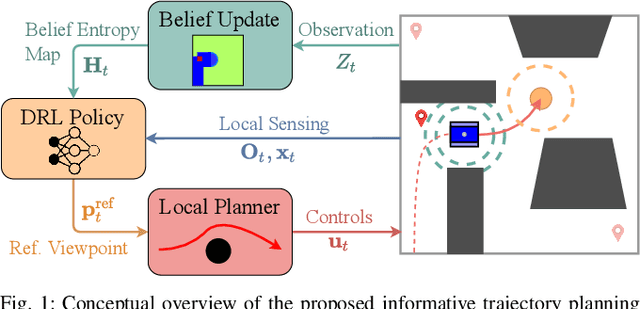



Search missions require motion planning and navigation methods for information gathering that continuously replan based on new observations of the robot's surroundings. Current methods for information gathering, such as Monte Carlo Tree Search, are capable of reasoning over long horizons, but they are computationally expensive. An alternative for fast online execution is to train, offline, an information gathering policy, which indirectly reasons about the information value of new observations. However, these policies lack safety guarantees and do not account for the robot dynamics. To overcome these limitations we train an information-aware policy via deep reinforcement learning, that guides a receding-horizon trajectory optimization planner. In particular, the policy continuously recommends a reference viewpoint to the local planner, such that the resulting dynamically feasible and collision-free trajectories lead to observations that maximize the information gain and reduce the uncertainty about the environment. In simulation tests in previously unseen environments, our method consistently outperforms greedy next-best-view policies and achieves competitive performance compared to Monte Carlo Tree Search, in terms of information gains and coverage time, with a reduction in execution time by three orders of magnitude.
With Whom to Communicate: Learning Efficient Communication for Multi-Robot Collision Avoidance
Sep 25, 2020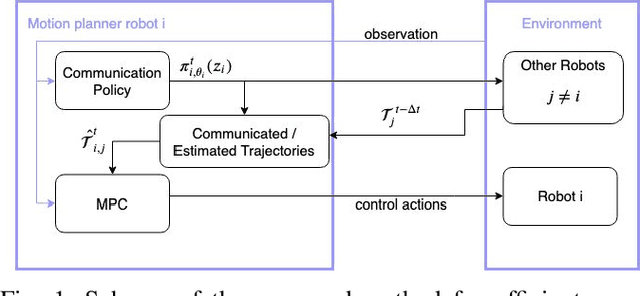
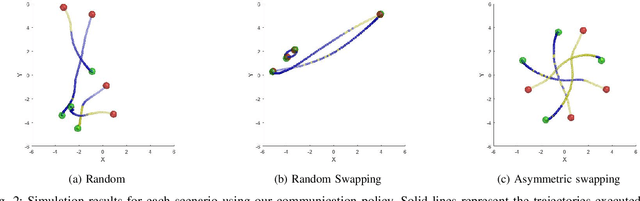
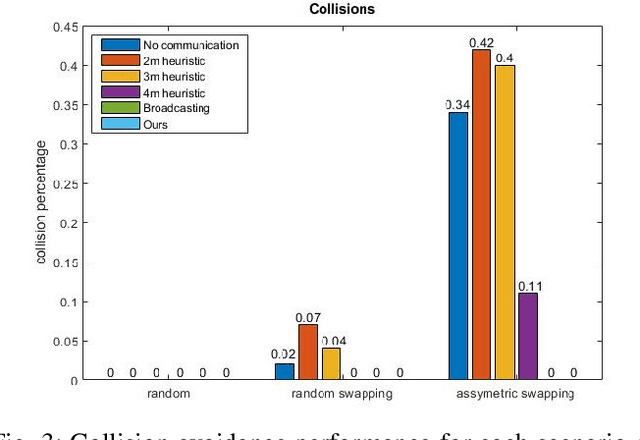

Decentralized multi-robot systems typically perform coordinated motion planning by constantly broadcasting their intentions as a means to cope with the lack of a central system coordinating the efforts of all robots. Especially in complex dynamic environments, the coordination boost allowed by communication is critical to avoid collisions between cooperating robots. However, the risk of collision between a pair of robots fluctuates through their motion and communication is not always needed. Additionally, constant communication makes much of the still valuable information shared in previous time steps redundant. This paper presents an efficient communication method that solves the problem of "when" and with "whom" to communicate in multi-robot collision avoidance scenarios. In this approach, every robot learns to reason about other robots' states and considers the risk of future collisions before asking for the trajectory plans of other robots. We evaluate and verify the proposed communication strategy in simulation with four quadrotors and compare it with three baseline strategies: non-communicating, broadcasting and a distance-based method broadcasting information with quadrotors within a predefined distance.