 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Imitation: Learning Long-Horizon Manipulation Tasks from Few Demonstrations
Paper and Code
Jul 18, 2024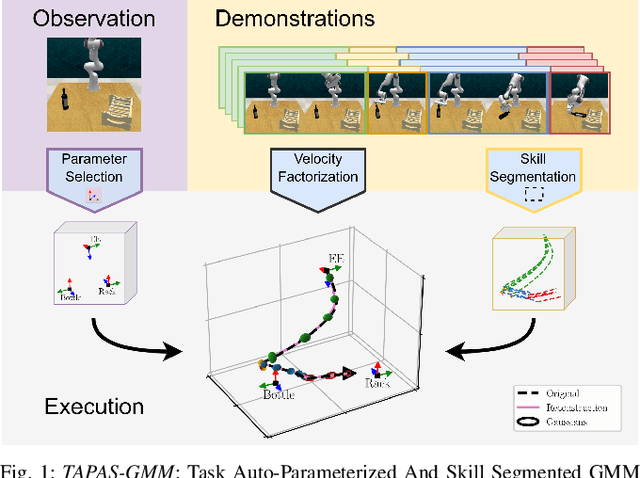
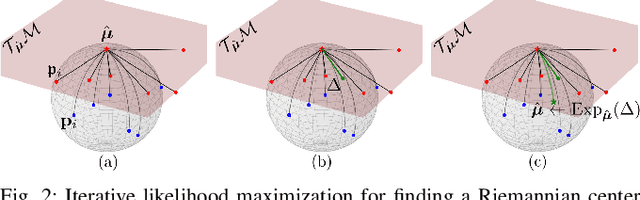
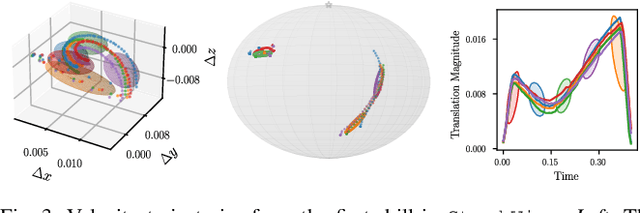
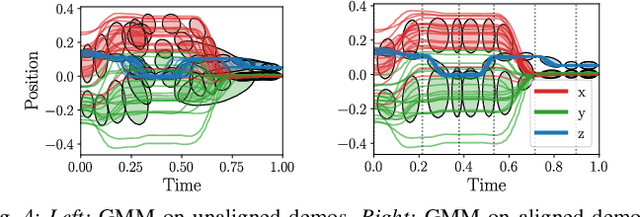
Task Parametrized Gaussian Mixture Models (TP-GMM) are a sample-efficient method for learning object-centric robot manipulation tasks. However, there are several open challenges to applying TP-GMMs in the wild. In this work, we tackle three crucial challenges synergistically. First, end-effector velocities are non-Euclidean and thus hard to model using standard GMMs. We thus propose to factorize the robot's end-effector velocity into its direction and magnitude, and model them using Riemannian GMMs. Second, we leverage the factorized velocities to segment and sequence skills from complex demonstration trajectories. Through the segmentation, we further align skill trajectories and hence leverage time as a powerful inductive bias. Third, we present a method to automatically detect relevant task parameters per skill from visual observations. Our approach enables learning complex manipulation tasks from just five demonstrations while using only RGB-D observations. Extensive experimental evaluations on RLBench demonstrate that our approach achieves state-of-the-art performance with 20-fold improved sample efficiency. Our policies generalize across different environments, object instances, and object positions, while the learned skills are reusable.