 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Filtering for Predicting User Preferences for Organizing Objects
Dec 20, 2015
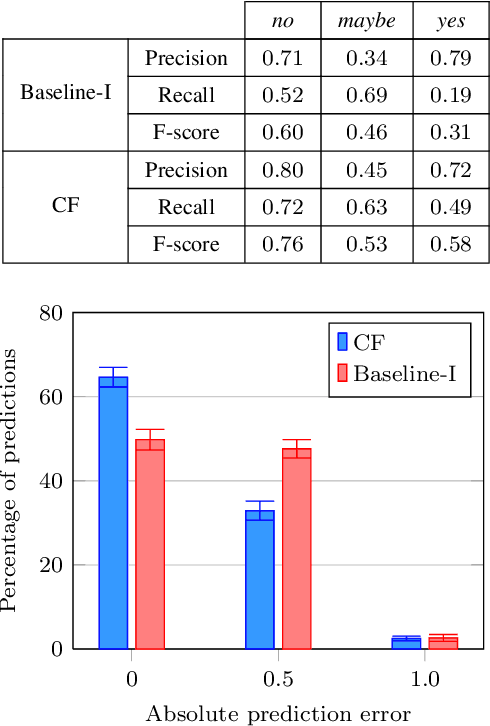
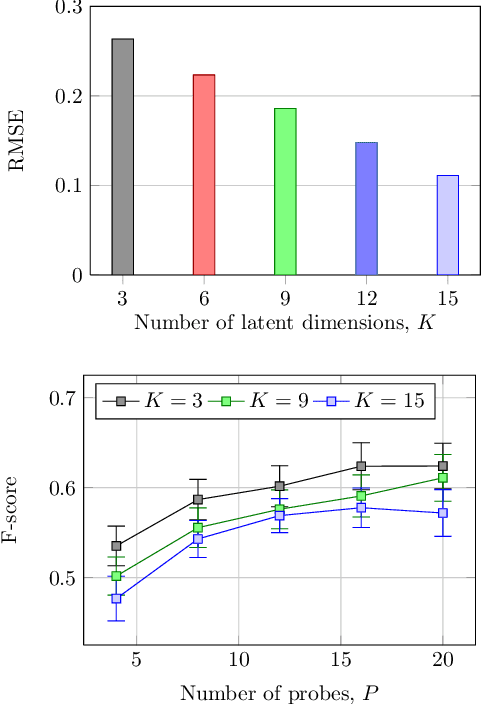
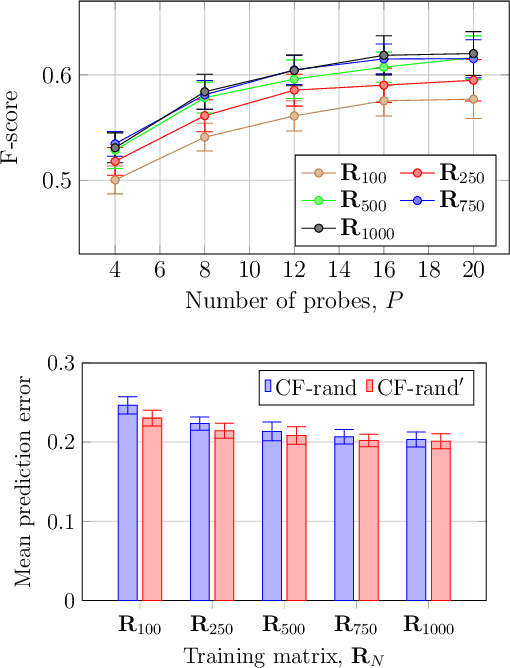
As service robots become more and more capable of performing useful tasks for us, there is a growing need to teach robots how we expect them to carry out these tasks. However, different users typically have their own preferences, for example with respect to arranging objects on different shelves. As many of these preferences depend on a variety of factors including personal taste, cultural background, or common sense, it is challenging for an expert to pre-program a robot in order to accommodate all potential users. At the same time, it is impractical for robots to constantly query users about how they should perform individual tasks. In this work, we present an approach to learn patterns in user preferences for the task of tidying up objects in containers, e.g., shelves or boxes. Our method builds upon the paradigm of collaborative filtering for making personalized recommendations and relies on data from different users that we gather using crowdsourcing. To deal with novel objects for which we have no data, we propose a method that compliments standard collaborative filtering by leveraging information mined from the Web. When solving a tidy-up task, we first predict pairwise object preferences of the user. Then, we subdivide the objects in containers by modeling a spectral clustering problem. Our solution is easy to update, does not require complex modeling, and improves with the amount of user data. We evaluate our approach using crowdsourcing data from over 1,200 users and demonstrate its effectiveness for two tidy-up scenarios. Additionally, we show that a real robot can reliably predict user preferences using our approach.
Multimodal Deep Learning for Robust RGB-D Object Recognition
Aug 18, 2015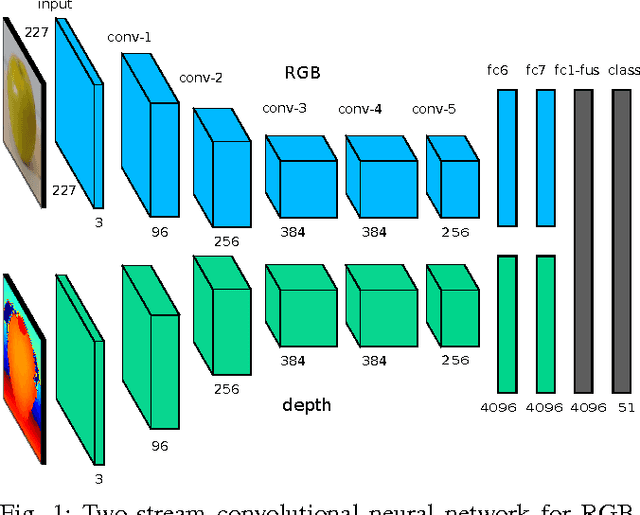



Robust object recognition is a crucial ingredient of many, if not all, real-world robotics applications. This paper leverages recent progress on Convolutional Neural Networks (CNNs) and proposes a novel RGB-D architecture for object recognition. Our architecture is composed of two separate CNN processing streams - one for each modality - which are consecutively combined with a late fusion network. We focus on learning with imperfect sensor data, a typical problem in real-world robotics tasks. For accurate learning, we introduce a multi-stage training methodology and two crucial ingredients for handling depth data with CNNs. The first, an effective encoding of depth information for CNNs that enables learning without the need for large depth datasets. The second, a data augmentation scheme for robust learning with depth images by corrupting them with realistic noise patterns. We present state-of-the-art results on the RGB-D object dataset and show recognition in challenging RGB-D real-world noisy settings.
Metric Localization using Google Street View
Apr 16, 2015



Accurate metrical localization is one of the central challenges in mobile robotics. Many existing methods aim at localizing after building a map with the robot. In this paper, we present a novel approach that instead uses geotagged panoramas from the Google Street View as a source of global positioning. We model the problem of localization as a non-linear least squares estimation in two phases. The first estimates the 3D position of tracked feature points from short monocular camera sequences. The second computes the rigid body transformation between the Street View panoramas and the estimated points. The only input of this approach is a stream of monocular camera images and odometry estimates. We quantified the accuracy of the method by running the approach on a robotic platform in a parking lot by using visual fiducials as ground truth. Additionally, we applied the approach in the context of personal localization in a real urban scenario by using data from a Google Tango tablet.