 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPFN-3: Technical Report
May 13, 2026Tabular data underpins most high-value prediction problems in science and industry, and TabPFN has driven the foundation model revolution for this modality. Designed with feedback from our users, TabPFN-3 builds on this foundation to scale state-of-the-art performance to datasets with 1M training rows and substantially reduce training and inference time. Pretrained exclusively on synthetic data from our prior, TabPFN-3 dramatically pushes the frontier of tabular prediction and brings substantial gains on time series, relational, and tabular-text data. On the standard tabular benchmark TabArena, a forward pass of TabPFN-3 outperforms all other models, including tuned and ensembled baselines, by a significant margin, and pareto-dominates the speed/performance frontier. On more diverse datasets, TabPFN-3 ranks first on datasets with many classes, and beats 8-hour-tuned gradient-boosted-tree baselines on datasets up to 1M training rows and 200 features. TabPFN-3 introduces test-time compute scaling to tabular foundation models. Our API offering TabPFN-3-Plus (Thinking) exploits this to beat all non-TabPFN models by over 200 Elo on TabArena, rising to 420 Elo on the largest data subset, and outperforms AutoGluon 1.5 extreme while being 10x faster, without using LLMs, real data, internet search or any other model besides TabPFN. TabPFN-3 extends the capabilities of our models, enabling SOTA prediction on relational data (new SOTA foundation model on RelBenchV1) and tabular-text data (SOTA on TabSTAR via TabPFN-3-Plus); and improves existing integrations: a specialized checkpoint, TabPFN-TS-3, ranks 2nd on the time-series benchmark fev-bench, and SHAP-value computation is up to 120x faster. TabPFN-3 achieves this performance while being up to 20x faster than TabPFN-2.5. In addition, a reduced KV cache and row-chunking scale to 1M rows on one H100 with fast inference speed.
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Nov 11, 2025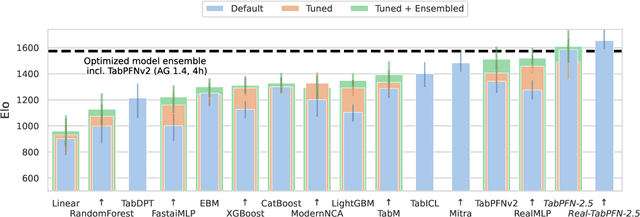
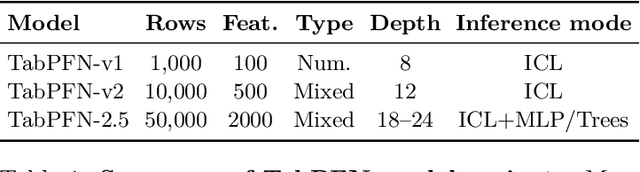
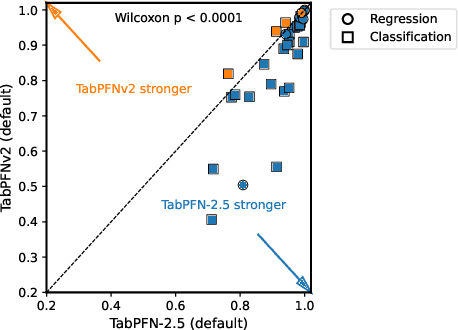
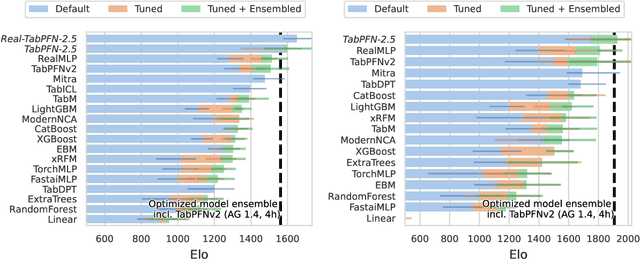
The first tabular foundation model, TabPFN, and its successor TabPFNv2 have impacted tabular AI substantially, with dozens of methods building on it and hundreds of applications across different use cases. This report introduces TabPFN-2.5, the next generation of our tabular foundation model, built for datasets with up to 50,000 data points and 2,000 features, a 20x increase in data cells compared to TabPFNv2. TabPFN-2.5 is now the leading method for the industry standard benchmark TabArena (which contains datasets with up to 100,000 training data points), substantially outperforming tuned tree-based models and matching the accuracy of AutoGluon 1.4, a complex four-hour tuned ensemble that even includes the previous TabPFNv2. Remarkably, default TabPFN-2.5 has a 100% win rate against default XGBoost on small to medium-sized classification datasets (<=10,000 data points, 500 features) and a 87% win rate on larger datasets up to 100K samples and 2K features (85% for regression). For production use cases, we introduce a new distillation engine that converts TabPFN-2.5 into a compact MLP or tree ensemble, preserving most of its accuracy while delivering orders-of-magnitude lower latency and plug-and-play deployment. This new release will immediately strengthen the performance of the many applications and methods already built on the TabPFN ecosystem.
Scalable Scene Flow from Point Clouds in the Real World
Mar 15, 2021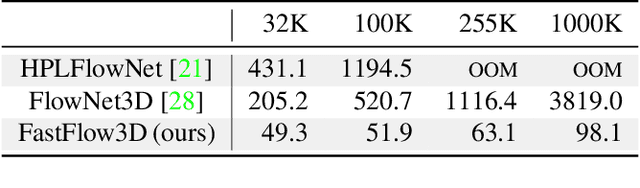
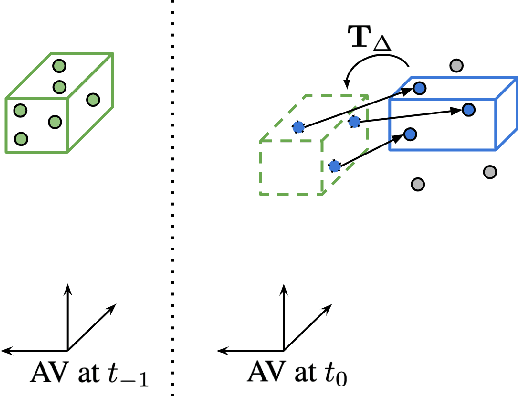
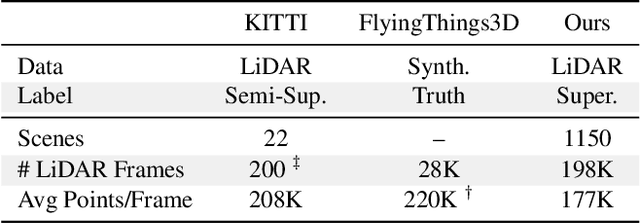
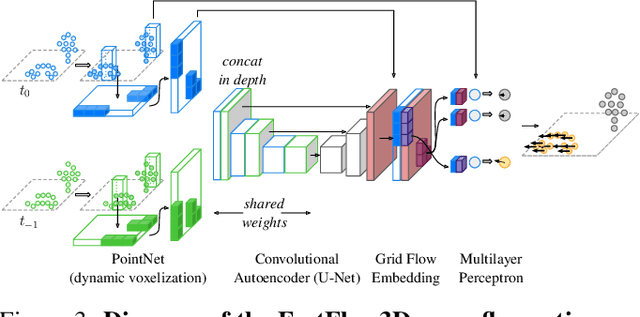
Autonomous vehicles operate in highly dynamic environments necessitating an accurate assessment of which aspects of a scene are moving and where they are moving to. A popular approach to 3D motion estimation -- termed scene flow -- is to employ 3D point cloud data from consecutive LiDAR scans, although such approaches have been limited by the small size of real-world, annotated LiDAR data. In this work, we introduce a new large scale benchmark for scene flow based on the Waymo Open Dataset. The dataset is $\sim$1,000$\times$ larger than previous real-world datasets in terms of the number of annotated frames and is derived from the corresponding tracked 3D objects. We demonstrate how previous works were bounded based on the amount of real LiDAR data available, suggesting that larger datasets are required to achieve state-of-the-art predictive performance. Furthermore, we show how previous heuristics for operating on point clouds such as artificial down-sampling heavily degrade performance, motivating a new class of models that are tractable on the full point cloud. To address this issue, we introduce the model architecture FastFlow3D that provides real time inference on the full point cloud. Finally, we demonstrate that this problem is amenable to techniques from semi-supervised learning by highlighting open problems for generalizing methods for predicting motion on unlabeled objects. We hope that this dataset may provide new opportunities for developing real world scene flow systems and motivate a new class of machine learning problems.
Optimization Beyond the Convolution: Generalizing Spatial Relations with End-to-End Metric Learning
Mar 24, 2018
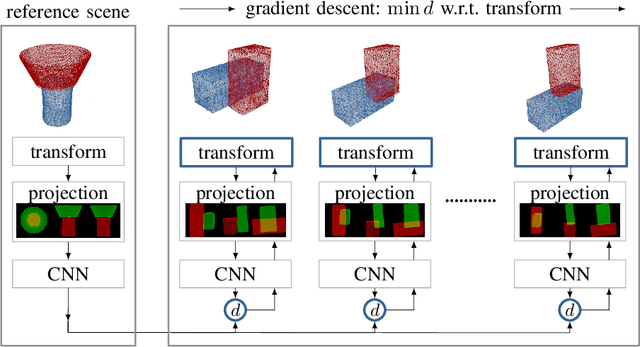
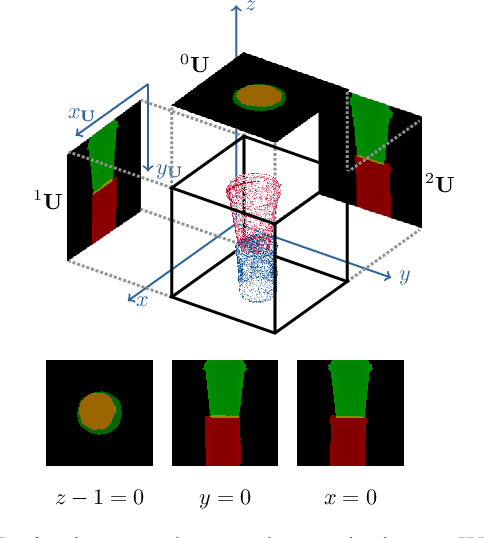
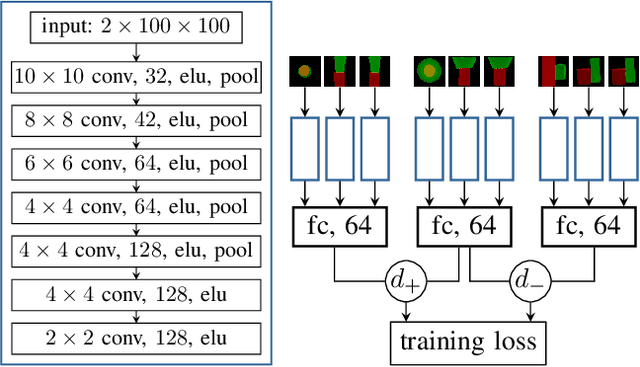
To operate intelligently in domestic environments, robots require the ability to understand arbitrary spatial relations between objects and to generalize them to objects of varying sizes and shapes. In this work, we present a novel end-to-end approach to generalize spatial relations based on distance metric learning. We train a neural network to transform 3D point clouds of objects to a metric space that captures the similarity of the depicted spatial relations, using only geometric models of the objects. Our approach employs gradient-based optimization to compute object poses in order to imitate an arbitrary target relation by reducing the distance to it under the learned metric. Our results based on simulated and real-world experiments show that the proposed method enables robots to generalize spatial relations to unknown objects over a continuous spectrum.
The Freiburg Groceries Dataset
Nov 17, 2016
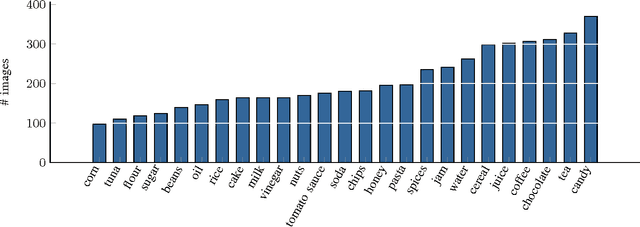


With the increasing performance of machine learning techniques in the last few years, the computer vision and robotics communities have created a large number of datasets for benchmarking object recognition tasks. These datasets cover a large spectrum of natural images and object categories, making them not only useful as a testbed for comparing machine learning approaches, but also a great resource for bootstrapping different domain-specific perception and robotic systems. One such domain is domestic environments, where an autonomous robot has to recognize a large variety of everyday objects such as groceries. This is a challenging task due to the large variety of objects and products, and where there is great need for real-world training data that goes beyond product images available online. In this paper, we address this issue and present a dataset consisting of 5,000 images covering 25 different classes of groceries, with at least 97 images per class. We collected all images from real-world settings at different stores and apartments. In contrast to existing groceries datasets, our dataset includes a large variety of perspectives, lighting conditions, and degrees of clutter. Overall, our images contain thousands of different object instances. It is our hope that machine learning and robotics researchers find this dataset of use for training, testing, and bootstrapping their approaches. As a baseline classifier to facilitate comparison, we re-trained the CaffeNet architecture (an adaptation of the well-known AlexNet) on our dataset and achieved a mean accuracy of 78.9%. We release this trained model along with the code and data splits we used in our experiments.