 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Implementing Machine Learning on Omics Data
Paper and Code
Nov 26, 2018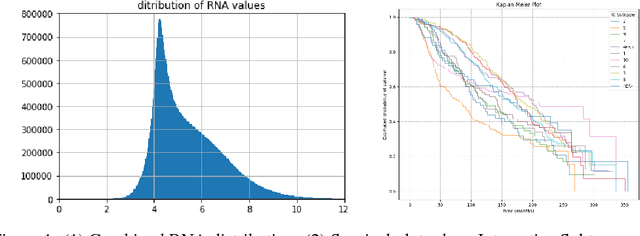
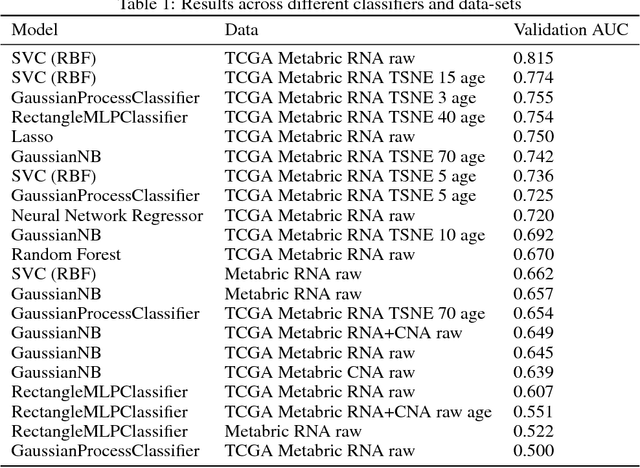
The potential benefits of applying machine learning methods to -omics data are becoming increasingly apparent, especially in clinical settings. However, the unique characteristics of these data are not always well suited to machine learning techniques. These data are often generated across different technologies in different labs, and frequently with high dimensionality. In this paper we present a framework for combining -omics data sets, and for handling high dimensional data, making -omics research more accessible to machine learning applications. We demonstrate the success of this framework through integration and analysis of multi-analyte data for a set of 3,533 breast cancers. We then use this data-set to predict breast cancer patient survival for individuals at risk of an impending event, with higher accuracy and lower variance than methods trained on individual data-sets. We hope that our pipelines for data-set generation and transformation will open up -omics data to machine learning researchers. We have made these freely available for noncommercial use at www.ccg.ai.