 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruct-Particulate: Scaling Feed-Forward 3D Object Articulation with Kinematic Control
Jun 12, 2026Reconstructing articulated 3D objects is important for animation, gaming, and robotic simulations. Recent neural networks can estimate the articulated structure of 3D objects, but their generalization remains limited by the scarcity of annotated data for this task. To address this gap, we introduce Instruct-Particulate, a model that takes a 3D mesh together with a target kinematic specification, including part descriptions, connectivity, joint types, and optional point prompts, and predicts the corresponding kinematic part segmentation and joint motion parameters. The kinematic specification disambiguates the task and allows the model to target annotations of different granularity, thereby making it possible to use more abundant heterogeneous training data. At test time, the kinematic specification can be obtained automatically from large-scale vision-language models, so the model can be applied to any input mesh. To train our model at scale, we construct a heterogeneous dataset of more than 150,000 articulated 3D objects, extending existing publicly available collections with data obtained by partially labelling other 3D models (monolithic or already decomposed into parts) with kinematic labels by means of vision-language models. Experiments show that our model generalizes better across categories and to AI-generated meshes, enabling articulated asset reconstruction from real-world images via image-to-3D models.
Efficient Camera-Controlled Video Generation of Static Scenes via Sparse Diffusion and 3D Rendering
Jan 14, 2026Modern video generative models based on diffusion models can produce very realistic clips, but they are computationally inefficient, often requiring minutes of GPU time for just a few seconds of video. This inefficiency poses a critical barrier to deploying generative video in applications that require real-time interactions, such as embodied AI and VR/AR. This paper explores a new strategy for camera-conditioned video generation of static scenes: using diffusion-based generative models to generate a sparse set of keyframes, and then synthesizing the full video through 3D reconstruction and rendering. By lifting keyframes into a 3D representation and rendering intermediate views, our approach amortizes the generation cost across hundreds of frames while enforcing geometric consistency. We further introduce a model that predicts the optimal number of keyframes for a given camera trajectory, allowing the system to adaptively allocate computation. Our final method, SRENDER, uses very sparse keyframes for simple trajectories and denser ones for complex camera motion. This results in video generation that is more than 40 times faster than the diffusion-based baseline in generating 20 seconds of video, while maintaining high visual fidelity and temporal stability, offering a practical path toward efficient and controllable video synthesis.
SpaceTimePilot: Generative Rendering of Dynamic Scenes Across Space and Time
Dec 31, 2025We present SpaceTimePilot, a video diffusion model that disentangles space and time for controllable generative rendering. Given a monocular video, SpaceTimePilot can independently alter the camera viewpoint and the motion sequence within the generative process, re-rendering the scene for continuous and arbitrary exploration across space and time. To achieve this, we introduce an effective animation time-embedding mechanism in the diffusion process, allowing explicit control of the output video's motion sequence with respect to that of the source video. As no datasets provide paired videos of the same dynamic scene with continuous temporal variations, we propose a simple yet effective temporal-warping training scheme that repurposes existing multi-view datasets to mimic temporal differences. This strategy effectively supervises the model to learn temporal control and achieve robust space-time disentanglement. To further enhance the precision of dual control, we introduce two additional components: an improved camera-conditioning mechanism that allows altering the camera from the first frame, and CamxTime, the first synthetic space-and-time full-coverage rendering dataset that provides fully free space-time video trajectories within a scene. Joint training on the temporal-warping scheme and the CamxTime dataset yields more precise temporal control. We evaluate SpaceTimePilot on both real-world and synthetic data, demonstrating clear space-time disentanglement and strong results compared to prior work. Project page: https://zheninghuang.github.io/Space-Time-Pilot/ Code: https://github.com/ZheningHuang/spacetimepilot
Particulate: Feed-Forward 3D Object Articulation
Dec 12, 2025We present Particulate, a feed-forward approach that, given a single static 3D mesh of an everyday object, directly infers all attributes of the underlying articulated structure, including its 3D parts, kinematic structure, and motion constraints. At its core is a transformer network, Part Articulation Transformer, which processes a point cloud of the input mesh using a flexible and scalable architecture to predict all the aforementioned attributes with native multi-joint support. We train the network end-to-end on a diverse collection of articulated 3D assets from public datasets. During inference, Particulate lifts the network's feed-forward prediction to the input mesh, yielding a fully articulated 3D model in seconds, much faster than prior approaches that require per-object optimization. Particulate can also accurately infer the articulated structure of AI-generated 3D assets, enabling full-fledged extraction of articulated 3D objects from a single (real or synthetic) image when combined with an off-the-shelf image-to-3D generator. We further introduce a new challenging benchmark for 3D articulation estimation curated from high-quality public 3D assets, and redesign the evaluation protocol to be more consistent with human preferences. Quantitative and qualitative results show that Particulate significantly outperforms state-of-the-art approaches.
LiteReality: Graphics-Ready 3D Scene Reconstruction from RGB-D Scans
Jul 03, 2025


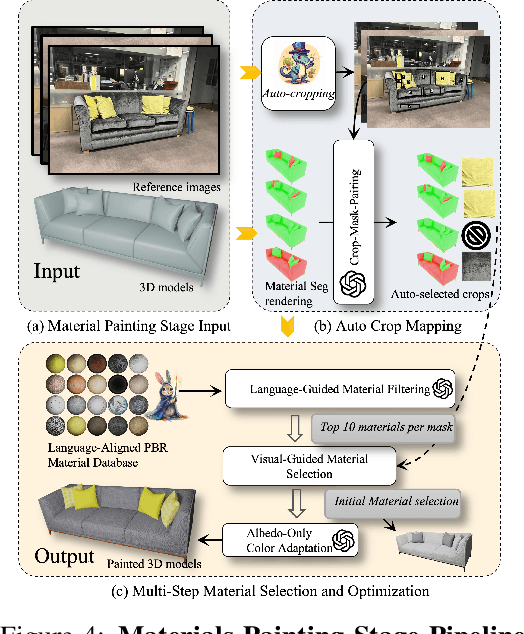
We propose LiteReality, a novel pipeline that converts RGB-D scans of indoor environments into compact, realistic, and interactive 3D virtual replicas. LiteReality not only reconstructs scenes that visually resemble reality but also supports key features essential for graphics pipelines -- such as object individuality, articulation, high-quality physically based rendering materials, and physically based interaction. At its core, LiteReality first performs scene understanding and parses the results into a coherent 3D layout and objects with the help of a structured scene graph. It then reconstructs the scene by retrieving the most visually similar 3D artist-crafted models from a curated asset database. Next, the Material Painting module enhances realism by recovering high-quality, spatially varying materials. Finally, the reconstructed scene is integrated into a simulation engine with basic physical properties to enable interactive behavior. The resulting scenes are compact, editable, and fully compatible with standard graphics pipelines, making them suitable for applications in AR/VR, gaming, robotics, and digital twins. In addition, LiteReality introduces a training-free object retrieval module that achieves state-of-the-art similarity performance on the Scan2CAD benchmark, along with a robust material painting module capable of transferring appearances from images of any style to 3D assets -- even under severe misalignment, occlusion, and poor lighting. We demonstrate the effectiveness of LiteReality on both real-life scans and public datasets. Project page: https://litereality.github.io; Video: https://www.youtube.com/watch?v=ecK9m3LXg2c
SmallGS: Gaussian Splatting-based Camera Pose Estimation for Small-Baseline Videos
Apr 22, 2025Dynamic videos with small baseline motions are ubiquitous in daily life, especially on social media. However, these videos present a challenge to existing pose estimation frameworks due to ambiguous features, drift accumulation, and insufficient triangulation constraints. Gaussian splatting, which maintains an explicit representation for scenes, provides a reliable novel view rasterization when the viewpoint change is small. Inspired by this, we propose SmallGS, a camera pose estimation framework that is specifically designed for small-baseline videos. SmallGS optimizes sequential camera poses using Gaussian splatting, which reconstructs the scene from the first frame in each video segment to provide a stable reference for the rest. The temporal consistency of Gaussian splatting within limited viewpoint differences reduced the requirement of sufficient depth variations in traditional camera pose estimation. We further incorporate pretrained robust visual features, e.g. DINOv2, into Gaussian splatting, where high-dimensional feature map rendering enhances the robustness of camera pose estimation. By freezing the Gaussian splatting and optimizing camera viewpoints based on rasterized features, SmallGS effectively learns camera poses without requiring explicit feature correspondences or strong parallax motion. We verify the effectiveness of SmallGS in small-baseline videos in TUM-Dynamics sequences, which achieves impressive accuracy in camera pose estimation compared to MonST3R and DORID-SLAM for small-baseline videos in dynamic scenes. Our project page is at: https://yuxinyao620.github.io/SmallGS
Continuous non-contact vital sign monitoring of neonates in intensive care units using RGB-D cameras
Dec 08, 2024Neonates in intensive care require continuous monitoring. Current measurement devices are limited for long-term use due to the fragility of newborn skin and the interference of wires with medical care and parental interactions. Camera-based vital sign monitoring has the potential to address these limitations and has become of considerable interest in recent years due to the absence of physical contact between the recording equipment and the neonates, as well as the introduction of low-cost devices. We present a novel system to capture vital signs while offering clinical insights beyond current technologies using a single RGB-D camera. Heart rate and oxygen saturation were measured using colour and infrared signals with mean average errors (MAE) of 7.69 bpm and 3.37%, respectively. Using the depth signals, an MAE of 4.83 breaths per minute was achieved for respiratory rate. Tidal volume measurements were obtained with a MAE of 0.61 mL. Flow-volume loops can also be calculated from camera data, which have applications in respiratory disease diagnosis. Our system demonstrates promising capabilities for neonatal monitoring, augmenting current clinical recording techniques to potentially improve outcomes for neonates.
STAResNet: a Network in Spacetime Algebra to solve Maxwell's PDEs
Aug 24, 2024



We introduce STAResNet, a ResNet architecture in Spacetime Algebra (STA) to solve Maxwell's partial differential equations (PDEs). Recently, networks in Geometric Algebra (GA) have been demonstrated to be an asset for truly geometric machine learning. In \cite{brandstetter2022clifford}, GA networks have been employed for the first time to solve partial differential equations (PDEs), demonstrating an increased accuracy over real-valued networks. In this work we solve Maxwell's PDEs both in GA and STA employing the same ResNet architecture and dataset, to discuss the impact that the choice of the right algebra has on the accuracy of GA networks. Our study on STAResNet shows how the correct geometric embedding in Clifford Networks gives a mean square error (MSE), between ground truth and estimated fields, up to 2.6 times lower than than obtained with a standard Clifford ResNet with 6 times fewer trainable parameters. STAREsNet demonstrates consistently lower MSE and higher correlation regardless of scenario. The scenarios tested are: sampling period of the dataset; presence of obstacles with either seen or unseen configurations; the number of channels in the ResNet architecture; the number of rollout steps; whether the field is in 2D or 3D space. This demonstrates how choosing the right algebra in Clifford networks is a crucial factor for more compact, accurate, descriptive and better generalising pipelines.
OpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene Understanding
Feb 23, 2024


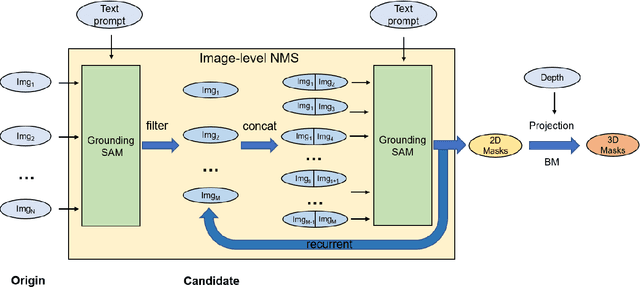
This report provides an overview of the challenge hosted at the OpenSUN3D Workshop on Open-Vocabulary 3D Scene Understanding held in conjunction with ICCV 2023. The goal of this workshop series is to provide a platform for exploration and discussion of open-vocabulary 3D scene understanding tasks, including but not limited to segmentation, detection and mapping. We provide an overview of the challenge hosted at the workshop, present the challenge dataset, the evaluation methodology, and brief descriptions of the winning methods. For additional details, please see https://opensun3d.github.io/index_iccv23.html.
OpenIns3D: Snap and Lookup for 3D Open-vocabulary Instance Segmentation
Sep 04, 2023Current 3D open-vocabulary scene understanding methods mostly utilize well-aligned 2D images as the bridge to learn 3D features with language. However, applying these approaches becomes challenging in scenarios where 2D images are absent. In this work, we introduce a completely new pipeline, namely, OpenIns3D, which requires no 2D image inputs, for 3D open-vocabulary scene understanding at the instance level. The OpenIns3D framework employs a "Mask-Snap-Lookup" scheme. The "Mask" module learns class-agnostic mask proposals in 3D point clouds. The "Snap" module generates synthetic scene-level images at multiple scales and leverages 2D vision language models to extract interesting objects. The "Lookup" module searches through the outcomes of "Snap" with the help of Mask2Pixel maps, which contain the precise correspondence between 3D masks and synthetic images, to assign category names to the proposed masks. This 2D input-free, easy-to-train, and flexible approach achieved state-of-the-art results on a wide range of indoor and outdoor datasets with a large margin. Furthermore, OpenIns3D allows for effortless switching of 2D detectors without re-training. When integrated with state-of-the-art 2D open-world models such as ODISE and GroundingDINO, superb results are observed on open-vocabulary instance segmentation. When integrated with LLM-powered 2D models like LISA, it demonstrates a remarkable capacity to process highly complex text queries, including those that require intricate reasoning and world knowledge. Project page: https://zheninghuang.github.io/OpenIns3D/