 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticraft: An Agentic System for Scalable Articulated 3D Asset Generation
May 14, 2026A bottleneck in learning to understand articulated 3D objects is the lack of large and diverse datasets. In this paper, we propose to leverage large language models (LLMs) to close this gap and generate articulated assets at scale. We reduce the problem of generating an articulated 3D asset to that of writing a program that builds it. We then introduce a new agentic system, Articraft, that writes such programs automatically. We design a programmatic interface and harness to help the LLM do so effectively. The LLM writes code against a domain-specific SDK for defining parts, composing geometry, specifying joints, and writing tests to validate the resulting assets. The harness exposes a restricted workspace and interface to the LLM, validates the resulting assets, and returns structured feedback. In this way, the LLM is not distracted by details such as authoring a URDF file or managing a complex software environment. We show that this produces higher-quality assets than both state-of-the-art articulated-asset generators and general-purpose coding agents. Using Articraft, we build Articraft-10K, a curated dataset of over 10K articulated assets spanning 245 categories, and show its utility both for training models of articulated assets and in downstream applications such as robotics simulation and virtual reality.
SpaceTimePilot: Generative Rendering of Dynamic Scenes Across Space and Time
Dec 31, 2025We present SpaceTimePilot, a video diffusion model that disentangles space and time for controllable generative rendering. Given a monocular video, SpaceTimePilot can independently alter the camera viewpoint and the motion sequence within the generative process, re-rendering the scene for continuous and arbitrary exploration across space and time. To achieve this, we introduce an effective animation time-embedding mechanism in the diffusion process, allowing explicit control of the output video's motion sequence with respect to that of the source video. As no datasets provide paired videos of the same dynamic scene with continuous temporal variations, we propose a simple yet effective temporal-warping training scheme that repurposes existing multi-view datasets to mimic temporal differences. This strategy effectively supervises the model to learn temporal control and achieve robust space-time disentanglement. To further enhance the precision of dual control, we introduce two additional components: an improved camera-conditioning mechanism that allows altering the camera from the first frame, and CamxTime, the first synthetic space-and-time full-coverage rendering dataset that provides fully free space-time video trajectories within a scene. Joint training on the temporal-warping scheme and the CamxTime dataset yields more precise temporal control. We evaluate SpaceTimePilot on both real-world and synthetic data, demonstrating clear space-time disentanglement and strong results compared to prior work. Project page: https://zheninghuang.github.io/Space-Time-Pilot/ Code: https://github.com/ZheningHuang/spacetimepilot
LiteReality: Graphics-Ready 3D Scene Reconstruction from RGB-D Scans
Jul 03, 2025


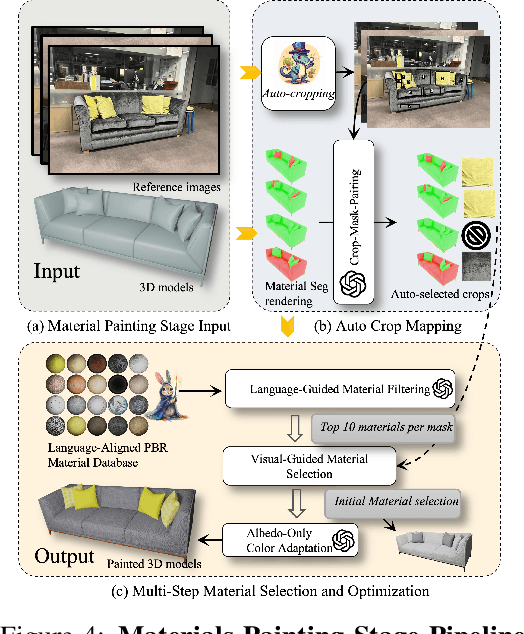
We propose LiteReality, a novel pipeline that converts RGB-D scans of indoor environments into compact, realistic, and interactive 3D virtual replicas. LiteReality not only reconstructs scenes that visually resemble reality but also supports key features essential for graphics pipelines -- such as object individuality, articulation, high-quality physically based rendering materials, and physically based interaction. At its core, LiteReality first performs scene understanding and parses the results into a coherent 3D layout and objects with the help of a structured scene graph. It then reconstructs the scene by retrieving the most visually similar 3D artist-crafted models from a curated asset database. Next, the Material Painting module enhances realism by recovering high-quality, spatially varying materials. Finally, the reconstructed scene is integrated into a simulation engine with basic physical properties to enable interactive behavior. The resulting scenes are compact, editable, and fully compatible with standard graphics pipelines, making them suitable for applications in AR/VR, gaming, robotics, and digital twins. In addition, LiteReality introduces a training-free object retrieval module that achieves state-of-the-art similarity performance on the Scan2CAD benchmark, along with a robust material painting module capable of transferring appearances from images of any style to 3D assets -- even under severe misalignment, occlusion, and poor lighting. We demonstrate the effectiveness of LiteReality on both real-life scans and public datasets. Project page: https://litereality.github.io; Video: https://www.youtube.com/watch?v=ecK9m3LXg2c
SmallGS: Gaussian Splatting-based Camera Pose Estimation for Small-Baseline Videos
Apr 22, 2025Dynamic videos with small baseline motions are ubiquitous in daily life, especially on social media. However, these videos present a challenge to existing pose estimation frameworks due to ambiguous features, drift accumulation, and insufficient triangulation constraints. Gaussian splatting, which maintains an explicit representation for scenes, provides a reliable novel view rasterization when the viewpoint change is small. Inspired by this, we propose SmallGS, a camera pose estimation framework that is specifically designed for small-baseline videos. SmallGS optimizes sequential camera poses using Gaussian splatting, which reconstructs the scene from the first frame in each video segment to provide a stable reference for the rest. The temporal consistency of Gaussian splatting within limited viewpoint differences reduced the requirement of sufficient depth variations in traditional camera pose estimation. We further incorporate pretrained robust visual features, e.g. DINOv2, into Gaussian splatting, where high-dimensional feature map rendering enhances the robustness of camera pose estimation. By freezing the Gaussian splatting and optimizing camera viewpoints based on rasterized features, SmallGS effectively learns camera poses without requiring explicit feature correspondences or strong parallax motion. We verify the effectiveness of SmallGS in small-baseline videos in TUM-Dynamics sequences, which achieves impressive accuracy in camera pose estimation compared to MonST3R and DORID-SLAM for small-baseline videos in dynamic scenes. Our project page is at: https://yuxinyao620.github.io/SmallGS
OpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene Understanding
Feb 23, 2024


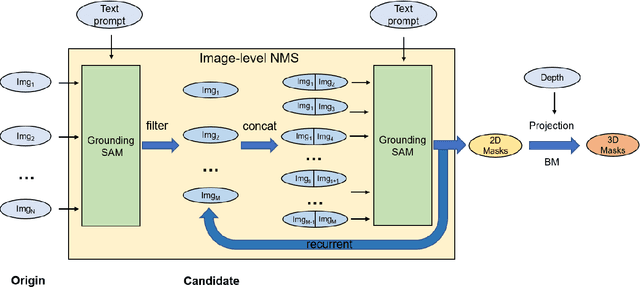
This report provides an overview of the challenge hosted at the OpenSUN3D Workshop on Open-Vocabulary 3D Scene Understanding held in conjunction with ICCV 2023. The goal of this workshop series is to provide a platform for exploration and discussion of open-vocabulary 3D scene understanding tasks, including but not limited to segmentation, detection and mapping. We provide an overview of the challenge hosted at the workshop, present the challenge dataset, the evaluation methodology, and brief descriptions of the winning methods. For additional details, please see https://opensun3d.github.io/index_iccv23.html.
OpenIns3D: Snap and Lookup for 3D Open-vocabulary Instance Segmentation
Sep 04, 2023Current 3D open-vocabulary scene understanding methods mostly utilize well-aligned 2D images as the bridge to learn 3D features with language. However, applying these approaches becomes challenging in scenarios where 2D images are absent. In this work, we introduce a completely new pipeline, namely, OpenIns3D, which requires no 2D image inputs, for 3D open-vocabulary scene understanding at the instance level. The OpenIns3D framework employs a "Mask-Snap-Lookup" scheme. The "Mask" module learns class-agnostic mask proposals in 3D point clouds. The "Snap" module generates synthetic scene-level images at multiple scales and leverages 2D vision language models to extract interesting objects. The "Lookup" module searches through the outcomes of "Snap" with the help of Mask2Pixel maps, which contain the precise correspondence between 3D masks and synthetic images, to assign category names to the proposed masks. This 2D input-free, easy-to-train, and flexible approach achieved state-of-the-art results on a wide range of indoor and outdoor datasets with a large margin. Furthermore, OpenIns3D allows for effortless switching of 2D detectors without re-training. When integrated with state-of-the-art 2D open-world models such as ODISE and GroundingDINO, superb results are observed on open-vocabulary instance segmentation. When integrated with LLM-powered 2D models like LISA, it demonstrates a remarkable capacity to process highly complex text queries, including those that require intricate reasoning and world knowledge. Project page: https://zheninghuang.github.io/OpenIns3D/
GeoSpark: Sparking up Point Cloud Segmentation with Geometry Clue
Mar 14, 2023Current point cloud segmentation architectures suffer from limited long-range feature modeling, as they mostly rely on aggregating information with local neighborhoods. Furthermore, in order to learn point features at multiple scales, most methods utilize a data-agnostic sampling approach to decrease the number of points after each stage. Such sampling methods, however, often discard points for small objects in the early stages, leading to inadequate feature learning. We believe these issues are can be mitigated by introducing explicit geometry clues as guidance. To this end, we propose GeoSpark, a Plug-in module that incorporates Geometry clues into the network to Spark up feature learning and downsampling. GeoSpark can be easily integrated into various backbones. For feature aggregation, it improves feature modeling by allowing the network to learn from both local points and neighboring geometry partitions, resulting in an enlarged data-tailored receptive field. Additionally, GeoSpark utilizes geometry partition information to guide the downsampling process, where points with unique features are preserved while redundant points are fused, resulting in better preservation of key points throughout the network. We observed consistent improvements after adding GeoSpark to various backbones including PointNet++, KPConv, and PointTransformer. Notably, when integrated with Point Transformer, our GeoSpark module achieves a 74.7% mIoU on the ScanNetv2 dataset (4.1% improvement) and 71.5% mIoU on the S3DIS Area 5 dataset (1.1% improvement), ranking top on both benchmarks. Code and models will be made publicly available.
NHA12D: A New Pavement Crack Dataset and a Comparison Study Of Crack Detection Algorithms
May 02, 2022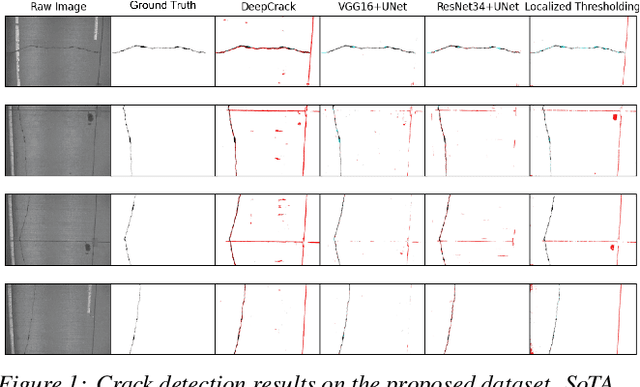

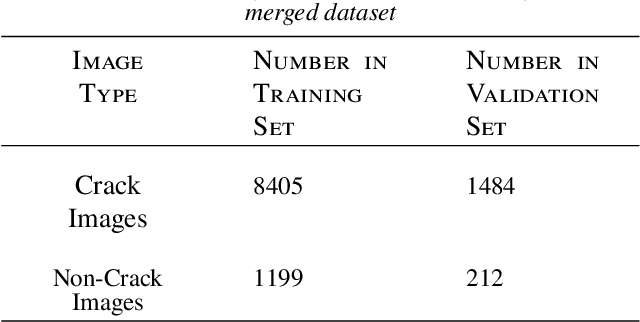

Crack detection plays a key role in automated pavement inspection. Although a large number of algorithms have been developed in recent years to further boost performance, there are still remaining challenges in practice, due to the complexity of pavement images. To further accelerate the development and identify the remaining challenges, this paper conducts a comparison study to evaluate the performance of the state of the art crack detection algorithms quantitatively and objectively. A more comprehensive annotated pavement crack dataset (NHA12D) that contains images with different viewpoints and pavements types is proposed. In the comparison study, crack detection algorithms were trained equally on the largest public crack dataset collected and evaluated on the proposed dataset (NHA12D). Overall, the U-Net model with VGG-16 as backbone has the best all-around performance, but models generally fail to distinguish cracks from concrete joints, leading to a high false-positive rate. It also found that detecting cracks from concrete pavement images still has huge room for improvement. Dataset for concrete pavement images is also missing in the literature. Future directions in this area include filling the gap for concrete pavement images and using domain adaptation techniques to enhance the detection results on unseen datasets.
PC-SwinMorph: Patch Representation for Unsupervised Medical Image Registration and Segmentation
Mar 10, 2022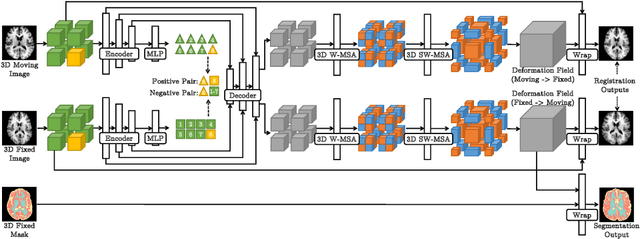
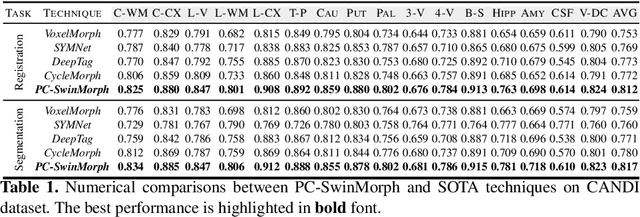
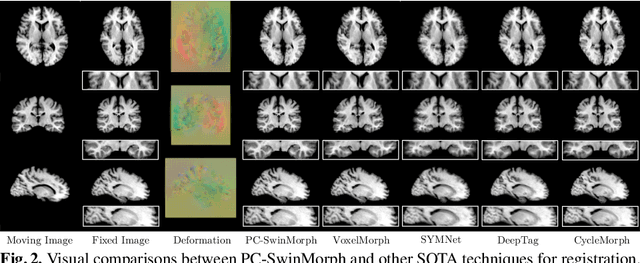
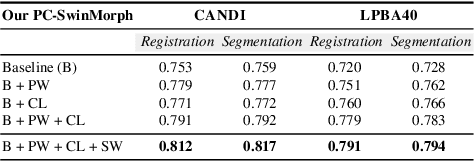
Medical image registration and segmentation are critical tasks for several clinical procedures. Manual realisation of those tasks is time-consuming and the quality is highly dependent on the level of expertise of the physician. To mitigate that laborious task, automatic tools have been developed where the majority of solutions are supervised techniques. However, in medical domain, the strong assumption of having a well-representative ground truth is far from being realistic. To overcome this challenge, unsupervised techniques have been investigated. However, they are still limited in performance and they fail to produce plausible results. In this work, we propose a novel unified unsupervised framework for image registration and segmentation that we called PC-SwinMorph. The core of our framework is two patch-based strategies, where we demonstrate that patch representation is key for performance gain. We first introduce a patch-based contrastive strategy that enforces locality conditions and richer feature representation. Secondly, we utilise a 3D window/shifted-window multi-head self-attention module as a patch stitching strategy to eliminate artifacts from the patch splitting. We demonstrate, through a set of numerical and visual results, that our technique outperforms current state-of-the-art unsupervised techniques.