 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimLingo: Vision-Only Closed-Loop Autonomous Driving with Language-Action Alignment
Paper and Code


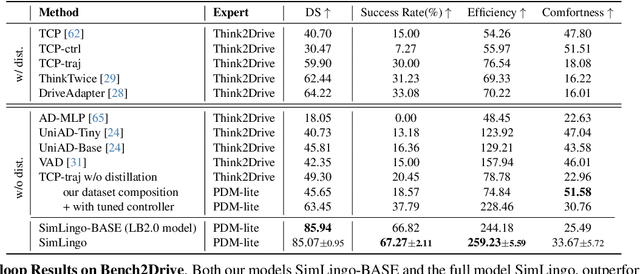

Integrating large language models (LLMs) into autonomous driving has attracted significant attention with the hope of improving generalization and explainability. However, existing methods often focus on either driving or vision-language understanding but achieving both high driving performance and extensive language understanding remains challenging. In addition, the dominant approach to tackle vision-language understanding is using visual question answering. However, for autonomous driving, this is only useful if it is aligned with the action space. Otherwise, the model's answers could be inconsistent with its behavior. Therefore, we propose a model that can handle three different tasks: (1) closed-loop driving, (2) vision-language understanding, and (3) language-action alignment. Our model SimLingo is based on a vision language model (VLM) and works using only camera, excluding expensive sensors like LiDAR. SimLingo obtains state-of-the-art performance on the widely used CARLA simulator on the Bench2Drive benchmark and is the winning entry at the CARLA challenge 2024. Additionally, we achieve strong results in a wide variety of language-related tasks while maintaining high driving performance.