 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving
Paper and Code
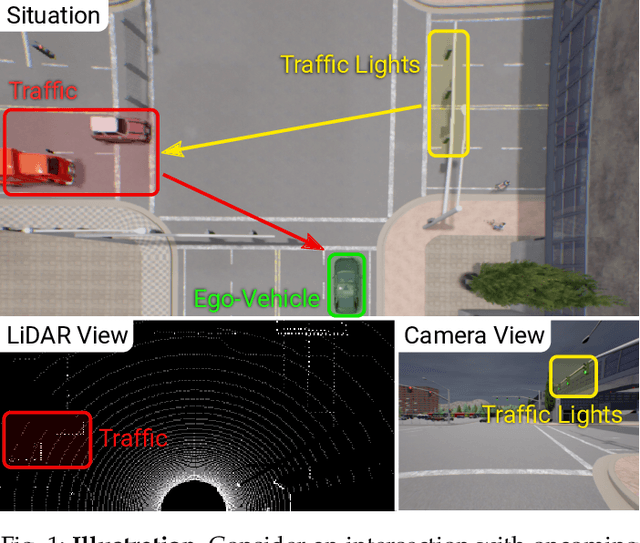
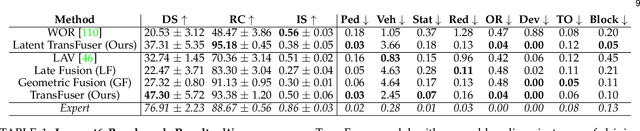
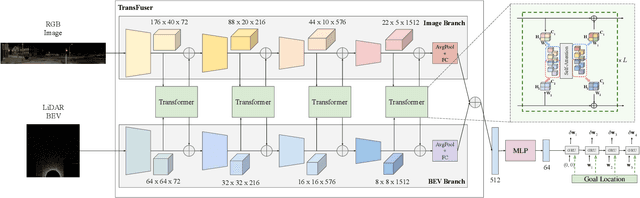
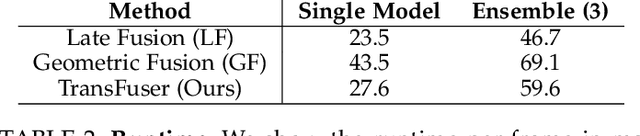
How should we integrate representations from complementary sensors for autonomous driving? Geometry-based fusion has shown promise for perception (e.g. object detection, motion forecasting). However, in the context of end-to-end driving, we find that imitation learning based on existing sensor fusion methods underperforms in complex driving scenarios with a high density of dynamic agents. Therefore, we propose TransFuser, a mechanism to integrate image and LiDAR representations using self-attention. Our approach uses transformer modules at multiple resolutions to fuse perspective view and bird's eye view feature maps. We experimentally validate its efficacy on a challenging new benchmark with long routes and dense traffic, as well as the official leaderboard of the CARLA urban driving simulator. At the time of submission, TransFuser outperforms all prior work on the CARLA leaderboard in terms of driving score by a large margin. Compared to geometry-based fusion, TransFuser reduces the average collisions per kilometer by 48%.