 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Class Agnostic Segmentation with Contrastive Learning for Autonomous Driving
Paper and Code

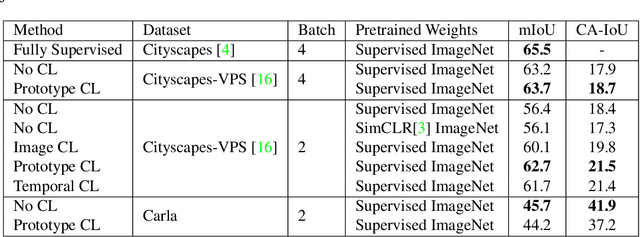


Semantic segmentation in autonomous driving predominantly focuses on learning from large-scale data with a closed set of known classes without considering unknown objects. Motivated by safety reasons, we address the video class agnostic segmentation task, which considers unknown objects outside the closed set of known classes in our training data. We propose a novel auxiliary contrastive loss to learn the segmentation of known classes and unknown objects. Unlike previous work in contrastive learning that samples the anchor, positive and negative examples on an image level, our contrastive learning method leverages pixel-wise semantic and temporal guidance. We conduct experiments on Cityscapes-VPS by withholding four classes from training and show an improvement gain for both known and unknown objects segmentation with the auxiliary contrastive loss. We further release a large-scale synthetic dataset for different autonomous driving scenarios that includes distinct and rare unknown objects. We conduct experiments on the full synthetic dataset and a reduced small-scale version, and show how contrastive learning is more effective in small scale datasets. Our proposed models, dataset, and code will be released at https://github.com/MSiam/video_class_agnostic_segmentation.