 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnfamiliar Finetuning Examples Control How Language Models Hallucinate
Paper and Code


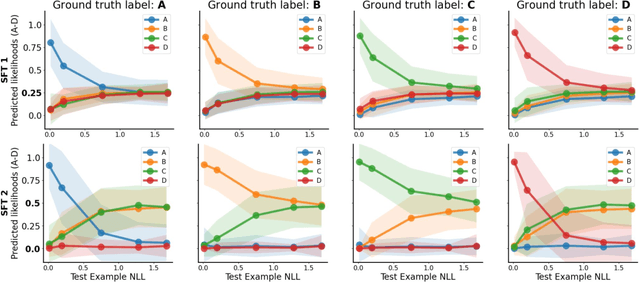

Large language models (LLMs) have a tendency to generate plausible-sounding yet factually incorrect responses, especially when queried on unfamiliar concepts. In this work, we explore the underlying mechanisms that govern how finetuned LLMs hallucinate. Our investigation reveals an interesting pattern: as inputs become more unfamiliar, LLM outputs tend to default towards a ``hedged'' prediction, whose form is determined by how the unfamiliar examples in the finetuning data are supervised. Thus, by strategically modifying these examples' supervision, we can control LLM predictions for unfamiliar inputs (e.g., teach them to say ``I don't know''). Based on these principles, we develop an RL approach that more reliably mitigates hallucinations for long-form generation tasks, by tackling the challenges presented by reward model hallucinations. We validate our findings with a series of controlled experiments in multiple-choice QA on MMLU, as well as long-form biography and book/movie plot generation tasks.