 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Structure in Reward Learning by Learning Features
Paper and Code
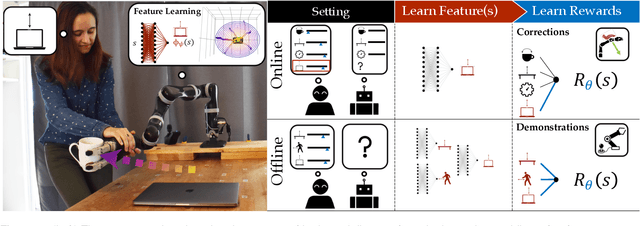


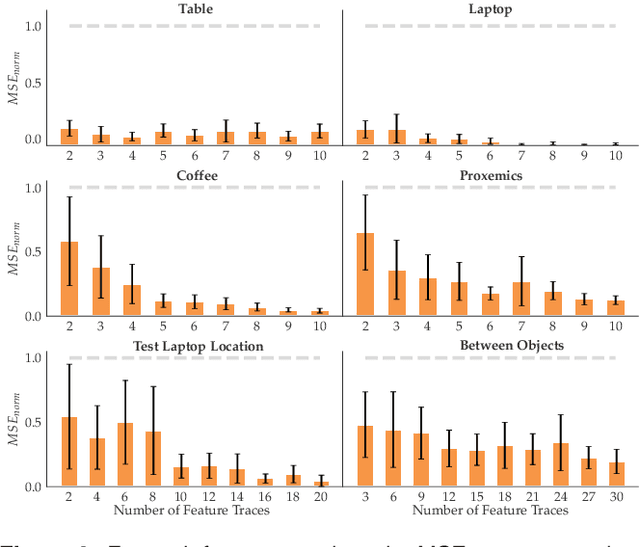
Reward learning enables robots to learn adaptable behaviors from human input. Traditional methods model the reward as a linear function of hand-crafted features, but that requires specifying all the relevant features a priori, which is impossible for real-world tasks. To get around this issue, recent deep Inverse Reinforcement Learning (IRL) methods learn rewards directly from the raw state but this is challenging because the robot has to implicitly learn the features that are important and how to combine them, simultaneously. Instead, we propose a divide and conquer approach: focus human input specifically on learning the features separately, and only then learn how to combine them into a reward. We introduce a novel type of human input for teaching features and an algorithm that utilizes it to learn complex features from the raw state space. The robot can then learn how to combine them into a reward using demonstrations, corrections, or other reward learning frameworks. We demonstrate our method in settings where all features have to be learned from scratch, as well as where some of the features are known. By first focusing human input specifically on the feature(s), our method decreases sample complexity and improves generalization of the learned reward over a deepIRL baseline. We show this in experiments with a physical 7DOF robot manipulator, as well as in a user study conducted in a simulated environment.