 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet-Based Training of Neural Barrier Certificates for Safety Verification of Dynamical Systems
May 04, 2026Barrier certificates are scalar functions over the state space of dynamical systems that separate all unsafe states from all reachable states. The existence of a barrier certificate formally verifies the safety of the dynamical system. Recent approaches synthesize barrier certificates by iteratively training a neural network. In each iteration, the candidate is formally verified - if successful, the barrier certificate is found. Instead, we propose a set-based training approach that tightly integrates verification into training via a set-based loss function that soundly encodes all barrier certificate properties. A loss of zero formally proves the validity of the barrier certificate, collapsing the iterative training and verification into a single training procedure. Our experiments demonstrate that our set-based training approach scales well with the system dimension and naturally handles complex nonlinear dynamics.
The 6th International Verification of Neural Networks Competition (VNN-COMP 2025): Summary and Results
Dec 22, 2025This report summarizes the 6th International Verification of Neural Networks Competition (VNN-COMP 2025), held as a part of the 8th International Symposium on AI Verification (SAIV), that was collocated with the 37th International Conference on Computer-Aided Verification (CAV). VNN-COMP is held annually to facilitate the fair and objective comparison of state-of-the-art neural network verification tools, encourage the standardization of tool interfaces, and bring together the neural network verification community. To this end, standardized formats for networks (ONNX) and specification (VNN-LIB) were defined, tools were evaluated on equal-cost hardware (using an automatic evaluation pipeline based on AWS instances), and tool parameters were chosen by the participants before the final test sets were made public. In the 2025 iteration, 8 teams participated on a diverse set of 16 regular and 9 extended benchmarks. This report summarizes the rules, benchmarks, participating tools, results, and lessons learned from this iteration of this competition.
Out of the Shadows: Exploring a Latent Space for Neural Network Verification
May 23, 2025Neural networks are ubiquitous. However, they are often sensitive to small input changes. Hence, to prevent unexpected behavior in safety-critical applications, their formal verification -- a notoriously hard problem -- is necessary. Many state-of-the-art verification algorithms use reachability analysis or abstract interpretation to enclose the set of possible outputs of a neural network. Often, the verification is inconclusive due to the conservatism of the enclosure. To address this problem, we design a novel latent space for formal verification that enables the transfer of output specifications to the input space for an iterative specification-driven input refinement, i.e., we iteratively reduce the set of possible inputs to only enclose the unsafe ones. The latent space is constructed from a novel view of projection-based set representations, e.g., zonotopes, which are commonly used in reachability analysis of neural networks. A projection-based set representation is a "shadow" of a higher-dimensional set -- a latent space -- that does not change during a set propagation through a neural network. Hence, the input set and the output enclosure are "shadows" of the same latent space that we can use to transfer constraints. We present an efficient verification tool for neural networks that uses our iterative refinement to significantly reduce the number of subproblems in a branch-and-bound procedure. Using zonotopes as a set representation, unlike many other state-of-the-art approaches, our approach can be realized by only using matrix operations, which enables a significant speed-up through efficient GPU acceleration. We demonstrate that our tool achieves competitive performance, which would place it among the top-ranking tools of the last neural network verification competition (VNN-COMP'24).
Training Verifiably Robust Agents Using Set-Based Reinforcement Learning
Aug 17, 2024



Reinforcement learning often uses neural networks to solve complex control tasks. However, neural networks are sensitive to input perturbations, which makes their deployment in safety-critical environments challenging. This work lifts recent results from formally verifying neural networks against such disturbances to reinforcement learning in continuous state and action spaces using reachability analysis. While previous work mainly focuses on adversarial attacks for robust reinforcement learning, we train neural networks utilizing entire sets of perturbed inputs and maximize the worst-case reward. The obtained agents are verifiably more robust than agents obtained by related work, making them more applicable in safety-critical environments. This is demonstrated with an extensive empirical evaluation of four different benchmarks.
End-To-End Set-Based Training for Neural Network Verification
Jan 26, 2024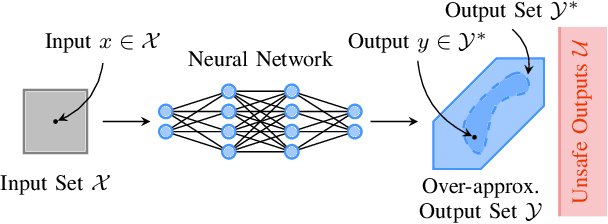
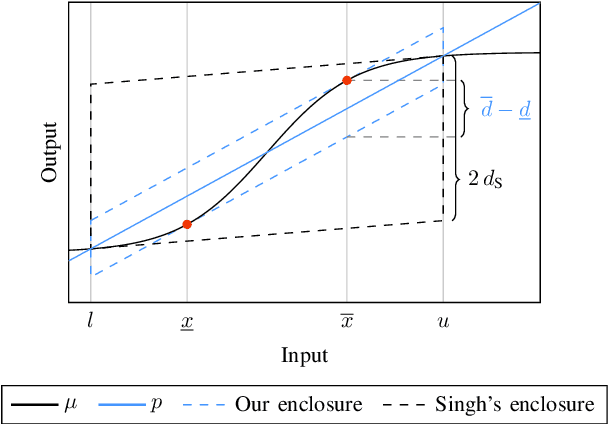
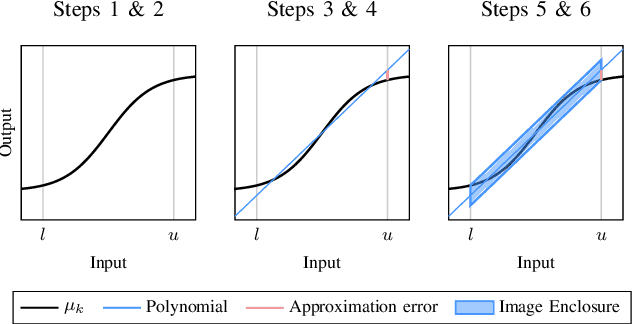
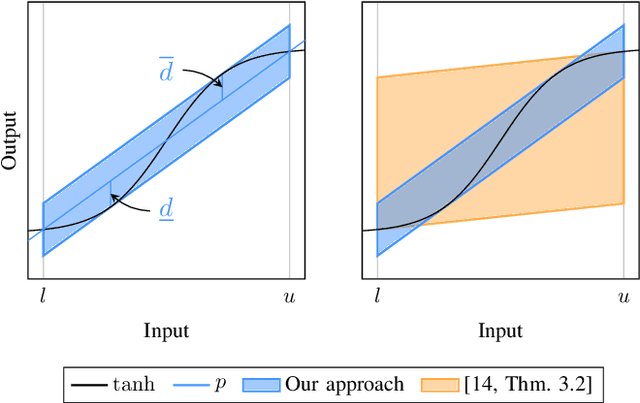
Neural networks are vulnerable to adversarial attacks, i.e., small input perturbations can result in substantially different outputs of a neural network. Safety-critical environments require neural networks that are robust against input perturbations. However, training and formally verifying robust neural networks is challenging. We address this challenge by employing, for the first time, a end-to-end set-based training procedure that trains robust neural networks for formal verification. Our training procedure drastically simplifies the subsequent formal robustness verification of the trained neural network. While previous research has predominantly focused on augmenting neural network training with adversarial attacks, our approach leverages set-based computing to train neural networks with entire sets of perturbed inputs. Moreover, we demonstrate that our set-based training procedure effectively trains robust neural networks, which are easier to verify. In many cases, set-based trained neural networks outperform neural networks trained with state-of-the-art adversarial attacks.
MixUp-MIL: A Study on Linear & Multilinear Interpolation-Based Data Augmentation for Whole Slide Image Classification
Nov 06, 2023



For classifying digital whole slide images in the absence of pixel level annotation, typically multiple instance learning methods are applied. Due to the generic applicability, such methods are currently of very high interest in the research community, however, the issue of data augmentation in this context is rarely explored. Here we investigate linear and multilinear interpolation between feature vectors, a data augmentation technique, which proved to be capable of improving the generalization performance classification networks and also for multiple instance learning. Experiments, however, have been performed on only two rather small data sets and one specific feature extraction approach so far and a strong dependence on the data set has been identified. Here we conduct a large study incorporating 10 different data set configurations, two different feature extraction approaches (supervised and self-supervised), stain normalization and two multiple instance learning architectures. The results showed an extraordinarily high variability in the effect of the method. We identified several interesting aspects to bring light into the darkness and identified novel promising fields of research.
MixUp-MIL: Novel Data Augmentation for Multiple Instance Learning and a Study on Thyroid Cancer Diagnosis
Nov 10, 2022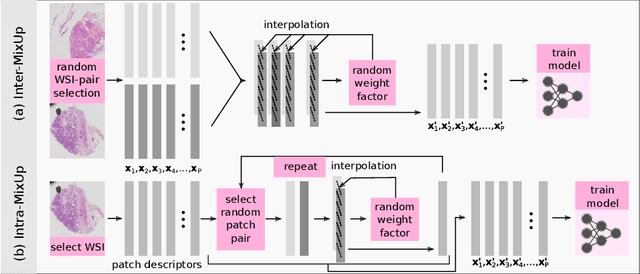
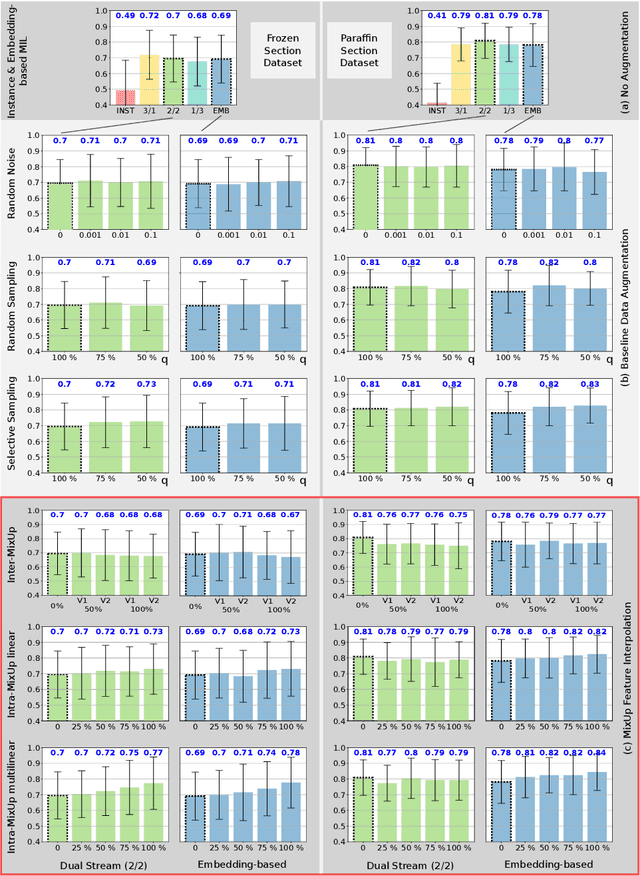
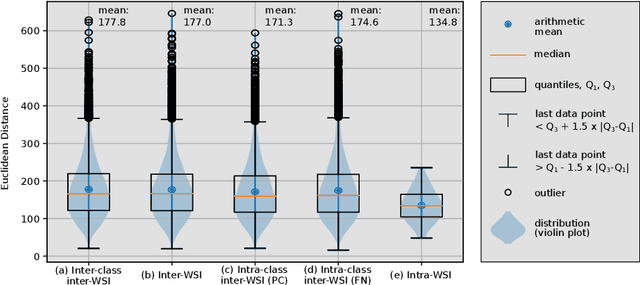
Multiple instance learning exhibits a powerful approach for whole slide image-based diagnosis in the absence of pixel- or patch-level annotations. In spite of the huge size of hole slide images, the number of individual slides is often rather small, leading to a small number of labeled samples. To improve training, we propose and investigate different data augmentation strategies for multiple instance learning based on the idea of linear interpolations of feature vectors (known as MixUp). Based on state-of-the-art multiple instance learning architectures and two thyroid cancer data sets, an exhaustive study is conducted considering a range of common data augmentation strategies. Whereas a strategy based on to the original MixUp approach showed decreases in accuracy, the use of a novel intra-slide interpolation method led to consistent increases in accuracy.
Formal Semantics and Formally Verified Validation for Temporal Planning
Mar 25, 2022


We present a simple and concise semantics for temporal planning. Our semantics are developed and formalised in the logic of the interactive theorem prover Isabelle/HOL. We derive from those semantics a validation algorithm for temporal planning and show, using a formal proof in Isabelle/HOL, that this validation algorithm implements our semantics. We experimentally evaluate our verified validation algorithm and show that it is practical.