 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Synthetic CT from CBCT via Multimodal Fusion: A Study on the Impact of CBCT Quality and Alignment
Jun 10, 2025

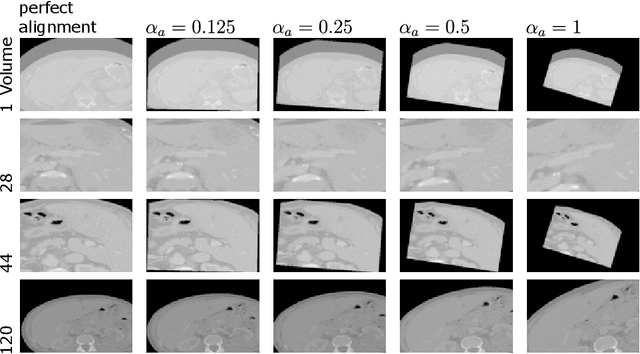

Cone-Beam Computed Tomography (CBCT) is widely used for real-time intraoperative imaging due to its low radiation dose and high acquisition speed. However, despite its high resolution, CBCT suffers from significant artifacts and thereby lower visual quality, compared to conventional Computed Tomography (CT). A recent approach to mitigate these artifacts is synthetic CT (sCT) generation, translating CBCT volumes into the CT domain. In this work, we enhance sCT generation through multimodal learning, integrating intraoperative CBCT with preoperative CT. Beyond validation on two real-world datasets, we use a versatile synthetic dataset, to analyze how CBCT-CT alignment and CBCT quality affect sCT quality. The results demonstrate that multimodal sCT consistently outperform unimodal baselines, with the most significant gains observed in well-aligned, low-quality CBCT-CT cases. Finally, we demonstrate that these findings are highly reproducible in real-world clinical datasets.
Initial Study On Improving Segmentation By Combining Preoperative CT And Intraoperative CBCT Using Synthetic Data
Dec 03, 2024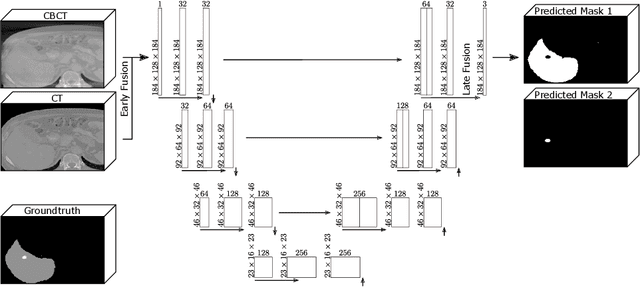

Computer-Assisted Interventions enable clinicians to perform precise, minimally invasive procedures, often relying on advanced imaging methods. Cone-beam computed tomography (CBCT) can be used to facilitate computer-assisted interventions, despite often suffering from artifacts that pose challenges for accurate interpretation. While the degraded image quality can affect image analysis, the availability of high quality, preoperative scans offers potential for improvements. Here we consider a setting where preoperative CT and intraoperative CBCT scans are available, however, the alignment (registration) between the scans is imperfect to simulate a real world scenario. We propose a multimodal learning method that fuses roughly aligned CBCT and CT scans and investigate the effect on segmentation performance. For this experiment we use synthetically generated data containing real CT and synthetic CBCT volumes with corresponding voxel annotations. We show that this fusion setup improves segmentation performance in $18$ out of $20$ investigated setups.
CBCTLiTS: A Synthetic, Paired CBCT/CT Dataset For Segmentation And Style Transfer
Jul 20, 2024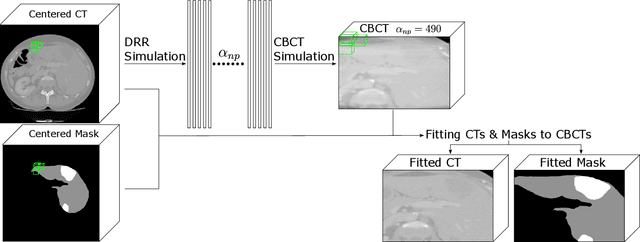
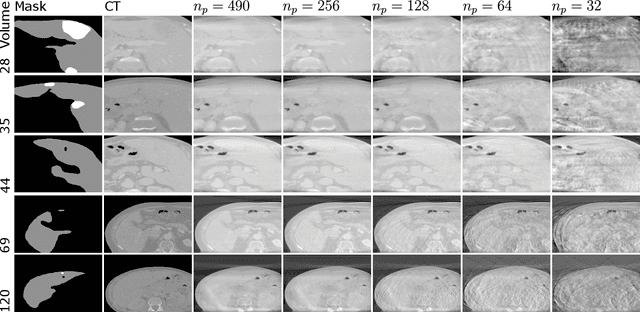
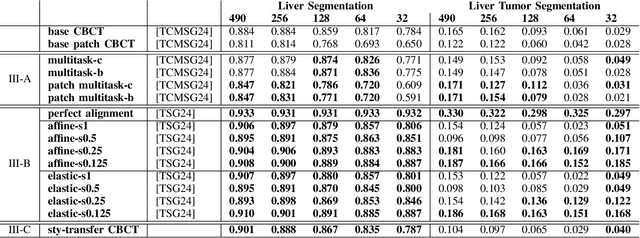
Medical imaging is vital in computer assisted intervention. Particularly cone beam computed tomography (CBCT) with defacto real time and mobility capabilities plays an important role. However, CBCT images often suffer from artifacts, which pose challenges for accurate interpretation, motivating research in advanced algorithms for more effective use in clinical practice. In this work we present CBCTLiTS, a synthetically generated, labelled CBCT dataset for segmentation with paired and aligned, high quality computed tomography data. The CBCT data is provided in 5 different levels of quality, reaching from a large number of projections with high visual quality and mild artifacts to a small number of projections with severe artifacts. This allows thorough investigations with the quality as a degree of freedom. We also provide baselines for several possible research scenarios like uni- and multimodal segmentation, multitask learning and style transfer followed by segmentation of relatively simple, liver to complex liver tumor segmentation. CBCTLiTS is accesssible via https://www.kaggle.com/datasets/maximiliantschuchnig/cbct-liver-and-liver-tumor-segmentation-train-data.
Virtually Objective Quantification of in vitro Wound Healing Scratch Assays with the Segment Anything Model
Jul 02, 2024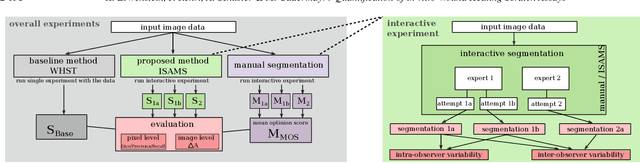
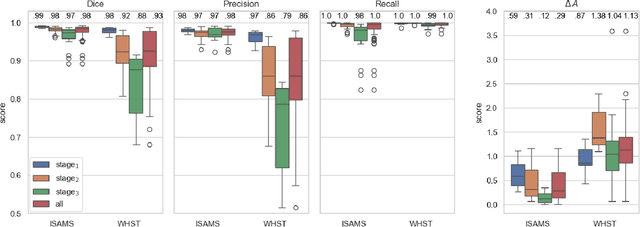
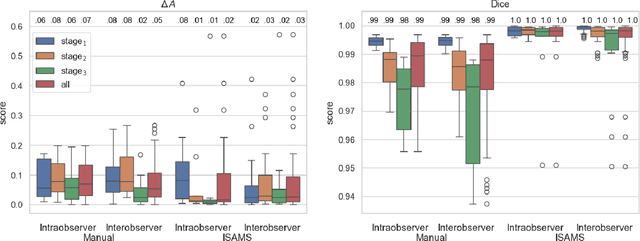

The in vitro scratch assay is a widely used assay in cell biology to assess the rate of wound closure related to a variety of therapeutic interventions. While manual measurement is subjective and vulnerable to intra- and interobserver variability, computer-based tools are theoretically objective, but in practice often contain parameters which are manually adjusted (individually per image or data set) and thereby provide a source for subjectivity. Modern deep learning approaches typically require large annotated training data which complicates instant applicability. In this paper, we make use of the segment anything model, a deep foundation model based on interactive point-prompts, which enables class-agnostic segmentation without tuning the network's parameters based on domain specific training data. The proposed method clearly outperformed a semi-objective baseline method that required manual inspection and, if necessary, adjustment of parameters per image. Even though the point prompts of the proposed approach are theoretically also a source for subjectivity, results attested very low intra- and interobserver variability, even compared to manual segmentation of domain experts.
Multimodal Learning With Intraoperative CBCT & Variably Aligned Preoperative CT Data To Improve Segmentation
Jul 01, 2024



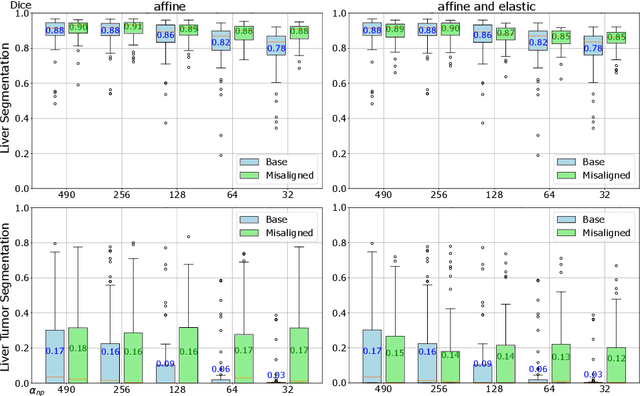
Cone-beam computed tomography (CBCT) is an important tool facilitating computer aided interventions, despite often suffering from artifacts that pose challenges for accurate interpretation. While the degraded image quality can affect downstream segmentation, the availability of high quality, preoperative scans represents potential for improvements. Here we consider a setting where preoperative CT and intraoperative CBCT scans are available, however, the alignment (registration) between the scans is imperfect. We propose a multimodal learning method that fuses roughly aligned CBCT and CT scans and investigate the effect of CBCT quality and misalignment on the final segmentation performance. For that purpose, we make use of a synthetically generated data set containing real CT and synthetic CBCT volumes. As an application scenario, we focus on liver and liver tumor segmentation. We show that the fusion of preoperative CT and simulated, intraoperative CBCT mostly improves segmentation performance (compared to using intraoperative CBCT only) and that even clearly misaligned preoperative data has the potential to improve segmentation performance.
Multimodal Learning To Improve Segmentation With Intraoperative CBCT & Preoperative CT
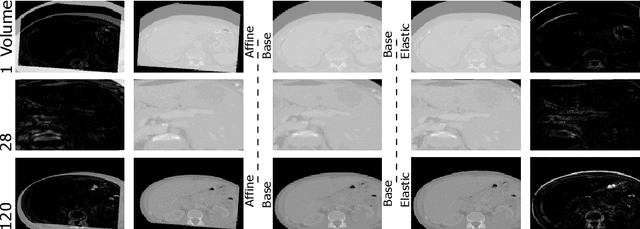
Jun 17, 2024Intraoperative medical imaging, particularly Cone-beam computed tomography (CBCT), is an important tool facilitating computer aided interventions, despite a lower visual quality. While this degraded image quality can affect downstream segmentation, the availability of high quality preoperative scans represents potential for improvements. Here we consider a setting where preoperative CT and intraoperative CBCT scans are available, however, the alignment (registration) between the scans is imperfect. We propose a multimodal learning method that fuses roughly aligned CBCT and CT scans and investigate the effect of CBCT quality and misalignment (affine and elastic transformations facilitating misalignment) on the final segmentation performance. As an application scenario, we focus on the segmentation of liver and liver tumor semantic segmentation and evaluate the effect of intraoperative image quality and misalignment on segmentation performance. To accomplish this, high quality, labelled CTs are defined as preoperative and used as a basis to simulate intraoperative CBCT. We show that the fusion of preoperative CT and simulated, intraoperative CBCT mostly improves segmentation performance and that even clearly misaligned preoperative data has the potential to improve segmentation performance.
Multi-task Learning To Improve Semantic Segmentation Of CBCT Scans Using Image Reconstruction
Dec 20, 2023Semantic segmentation is a crucial task in medical image processing, essential for segmenting organs or lesions such as tumors. In this study we aim to improve automated segmentation in CBCTs through multi-task learning. To evaluate effects on different volume qualities, a CBCT dataset is synthesised from the CT Liver Tumor Segmentation Benchmark (LiTS) dataset. To improve segmentation, two approaches are investigated. First, we perform multi-task learning to add morphology based regularization through a volume reconstruction task. Second, we use this reconstruction task to reconstruct the best quality CBCT (most similar to the original CT), facilitating denoising effects. We explore both holistic and patch-based approaches. Our findings reveal that, especially using a patch-based approach, multi-task learning improves segmentation in most cases and that these results can further be improved by our denoising approach.
MixUp-MIL: A Study on Linear & Multilinear Interpolation-Based Data Augmentation for Whole Slide Image Classification
Nov 06, 2023



For classifying digital whole slide images in the absence of pixel level annotation, typically multiple instance learning methods are applied. Due to the generic applicability, such methods are currently of very high interest in the research community, however, the issue of data augmentation in this context is rarely explored. Here we investigate linear and multilinear interpolation between feature vectors, a data augmentation technique, which proved to be capable of improving the generalization performance classification networks and also for multiple instance learning. Experiments, however, have been performed on only two rather small data sets and one specific feature extraction approach so far and a strong dependence on the data set has been identified. Here we conduct a large study incorporating 10 different data set configurations, two different feature extraction approaches (supervised and self-supervised), stain normalization and two multiple instance learning architectures. The results showed an extraordinarily high variability in the effect of the method. We identified several interesting aspects to bring light into the darkness and identified novel promising fields of research.
Inflation forecasting with attention based transformer neural networks
Mar 29, 2023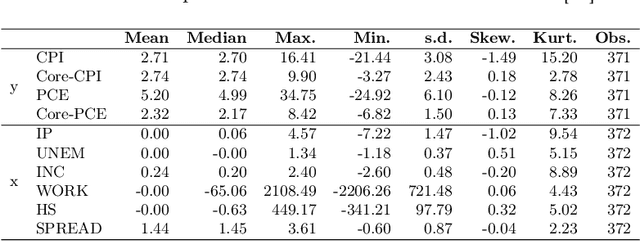
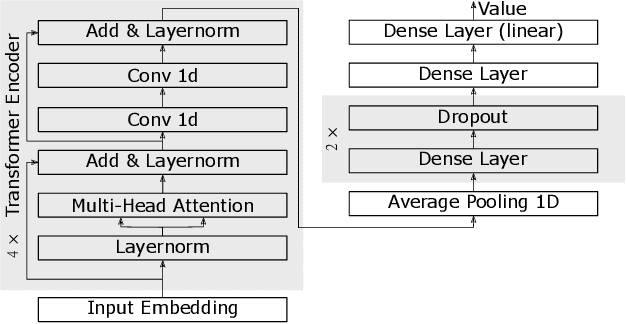
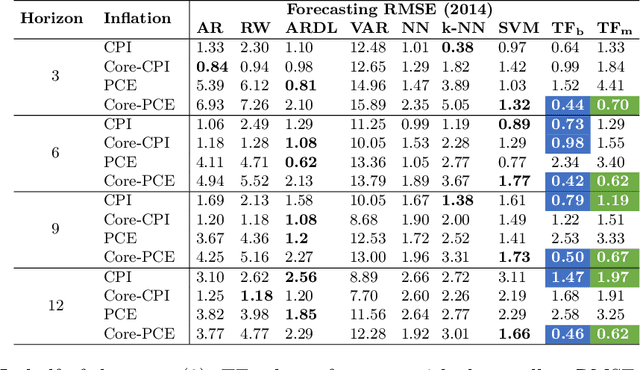
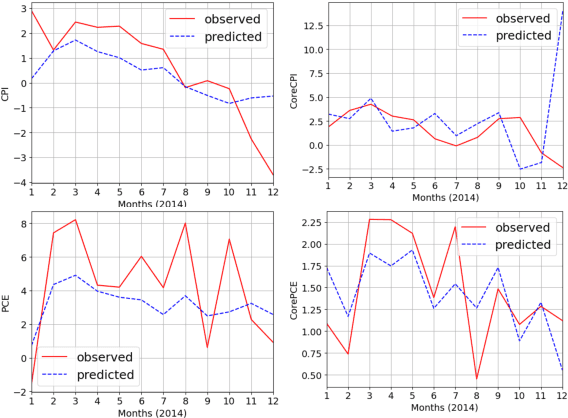
Inflation is a major determinant for allocation decisions and its forecast is a fundamental aim of governments and central banks. However, forecasting inflation is not a trivial task, as its prediction relies on low frequency, highly fluctuating data with unclear explanatory variables. While classical models show some possibility of predicting inflation, reliably beating the random walk benchmark remains difficult. Recently, (deep) neural networks have shown impressive results in a multitude of applications, increasingly setting the new state-of-the-art. This paper investigates the potential of the transformer deep neural network architecture to forecast different inflation rates. The results are compared to a study on classical time series and machine learning models. We show that our adapted transformer, on average, outperforms the baseline in 6 out of 16 experiments, showing best scores in two out of four investigated inflation rates. Our results demonstrate that a transformer based neural network can outperform classical regression and machine learning models in certain inflation rates and forecasting horizons.
MixUp-MIL: Novel Data Augmentation for Multiple Instance Learning and a Study on Thyroid Cancer Diagnosis
Nov 10, 2022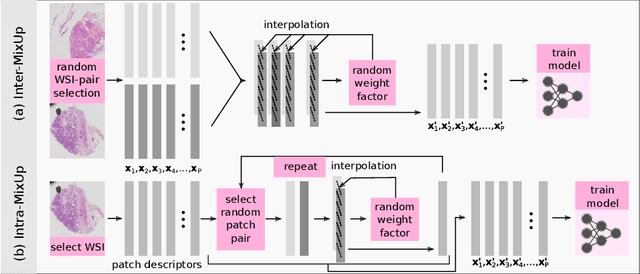
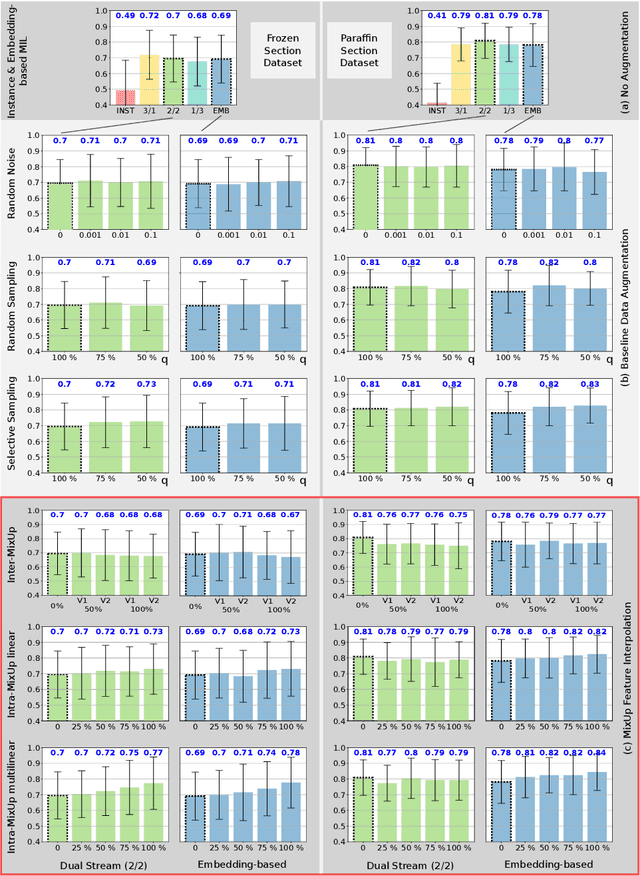
Multiple instance learning exhibits a powerful approach for whole slide image-based diagnosis in the absence of pixel- or patch-level annotations. In spite of the huge size of hole slide images, the number of individual slides is often rather small, leading to a small number of labeled samples. To improve training, we propose and investigate different data augmentation strategies for multiple instance learning based on the idea of linear interpolations of feature vectors (known as MixUp). Based on state-of-the-art multiple instance learning architectures and two thyroid cancer data sets, an exhaustive study is conducted considering a range of common data augmentation strategies. Whereas a strategy based on to the original MixUp approach showed decreases in accuracy, the use of a novel intra-slide interpolation method led to consistent increases in accuracy.