 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInitial Study On Improving Segmentation By Combining Preoperative CT And Intraoperative CBCT Using Synthetic Data
Dec 03, 2024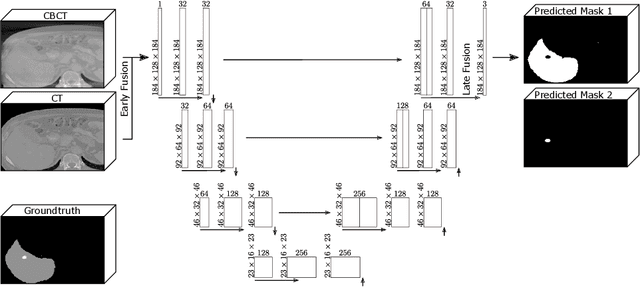

Computer-Assisted Interventions enable clinicians to perform precise, minimally invasive procedures, often relying on advanced imaging methods. Cone-beam computed tomography (CBCT) can be used to facilitate computer-assisted interventions, despite often suffering from artifacts that pose challenges for accurate interpretation. While the degraded image quality can affect image analysis, the availability of high quality, preoperative scans offers potential for improvements. Here we consider a setting where preoperative CT and intraoperative CBCT scans are available, however, the alignment (registration) between the scans is imperfect to simulate a real world scenario. We propose a multimodal learning method that fuses roughly aligned CBCT and CT scans and investigate the effect on segmentation performance. For this experiment we use synthetically generated data containing real CT and synthetic CBCT volumes with corresponding voxel annotations. We show that this fusion setup improves segmentation performance in $18$ out of $20$ investigated setups.
CBCTLiTS: A Synthetic, Paired CBCT/CT Dataset For Segmentation And Style Transfer
Jul 20, 2024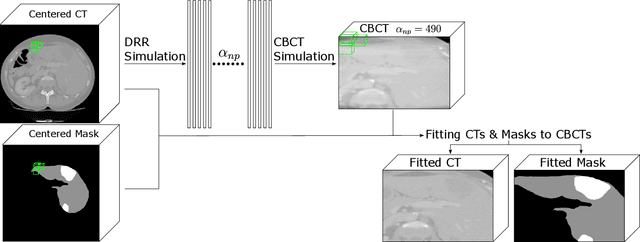
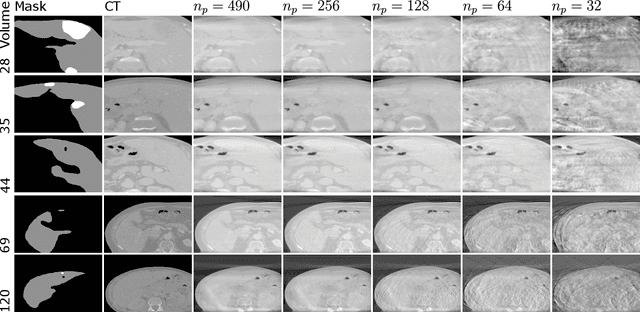
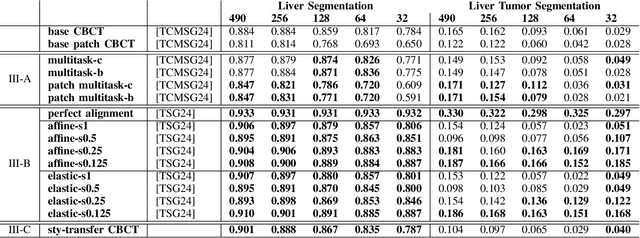
Medical imaging is vital in computer assisted intervention. Particularly cone beam computed tomography (CBCT) with defacto real time and mobility capabilities plays an important role. However, CBCT images often suffer from artifacts, which pose challenges for accurate interpretation, motivating research in advanced algorithms for more effective use in clinical practice. In this work we present CBCTLiTS, a synthetically generated, labelled CBCT dataset for segmentation with paired and aligned, high quality computed tomography data. The CBCT data is provided in 5 different levels of quality, reaching from a large number of projections with high visual quality and mild artifacts to a small number of projections with severe artifacts. This allows thorough investigations with the quality as a degree of freedom. We also provide baselines for several possible research scenarios like uni- and multimodal segmentation, multitask learning and style transfer followed by segmentation of relatively simple, liver to complex liver tumor segmentation. CBCTLiTS is accesssible via https://www.kaggle.com/datasets/maximiliantschuchnig/cbct-liver-and-liver-tumor-segmentation-train-data.
Multimodal Learning With Intraoperative CBCT & Variably Aligned Preoperative CT Data To Improve Segmentation
Jul 01, 2024



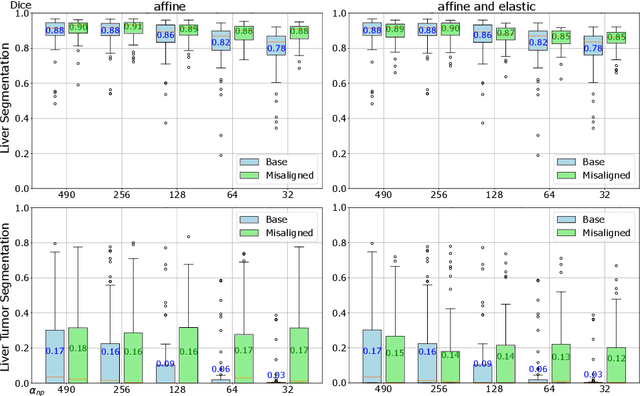
Cone-beam computed tomography (CBCT) is an important tool facilitating computer aided interventions, despite often suffering from artifacts that pose challenges for accurate interpretation. While the degraded image quality can affect downstream segmentation, the availability of high quality, preoperative scans represents potential for improvements. Here we consider a setting where preoperative CT and intraoperative CBCT scans are available, however, the alignment (registration) between the scans is imperfect. We propose a multimodal learning method that fuses roughly aligned CBCT and CT scans and investigate the effect of CBCT quality and misalignment on the final segmentation performance. For that purpose, we make use of a synthetically generated data set containing real CT and synthetic CBCT volumes. As an application scenario, we focus on liver and liver tumor segmentation. We show that the fusion of preoperative CT and simulated, intraoperative CBCT mostly improves segmentation performance (compared to using intraoperative CBCT only) and that even clearly misaligned preoperative data has the potential to improve segmentation performance.
Multimodal Learning To Improve Segmentation With Intraoperative CBCT & Preoperative CT
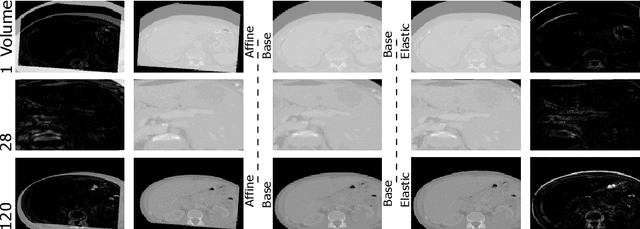
Jun 17, 2024Intraoperative medical imaging, particularly Cone-beam computed tomography (CBCT), is an important tool facilitating computer aided interventions, despite a lower visual quality. While this degraded image quality can affect downstream segmentation, the availability of high quality preoperative scans represents potential for improvements. Here we consider a setting where preoperative CT and intraoperative CBCT scans are available, however, the alignment (registration) between the scans is imperfect. We propose a multimodal learning method that fuses roughly aligned CBCT and CT scans and investigate the effect of CBCT quality and misalignment (affine and elastic transformations facilitating misalignment) on the final segmentation performance. As an application scenario, we focus on the segmentation of liver and liver tumor semantic segmentation and evaluate the effect of intraoperative image quality and misalignment on segmentation performance. To accomplish this, high quality, labelled CTs are defined as preoperative and used as a basis to simulate intraoperative CBCT. We show that the fusion of preoperative CT and simulated, intraoperative CBCT mostly improves segmentation performance and that even clearly misaligned preoperative data has the potential to improve segmentation performance.
Evaluation of Multi-Scale Multiple Instance Learning to Improve Thyroid Cancer Classification
Apr 22, 2022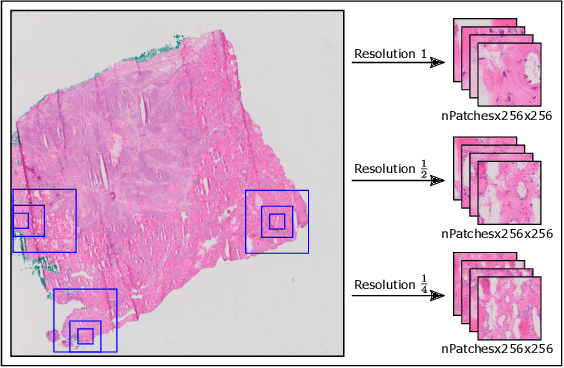
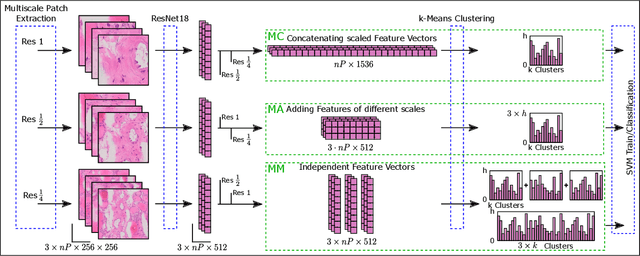
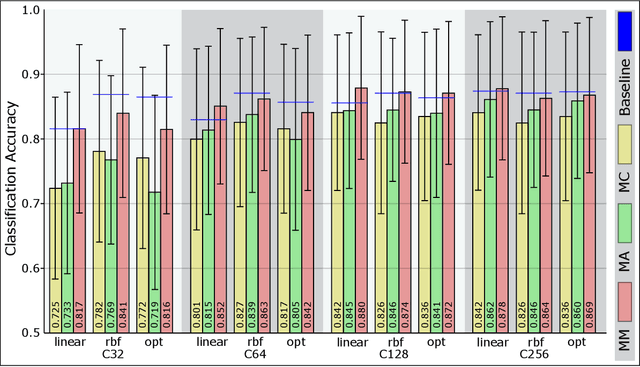
Thyroid cancer is currently the fifth most common malignancy diagnosed in women. Since differentiation of cancer sub-types is important for treatment and current, manual methods are time consuming and subjective, automatic computer-aided differentiation of cancer types is crucial. Manual differentiation of thyroid cancer is based on tissue sections, analysed by pathologists using histological features. Due to the enormous size of gigapixel whole slide images, holistic classification using deep learning methods is not feasible. Patch based multiple instance learning approaches, combined with aggregations such as bag-of-words, is a common approach. This work's contribution is to extend a patch based state-of-the-art method by generating and combining feature vectors of three different patch resolutions and analysing three distinct ways of combining them. The results showed improvements in one of the three multi-scale approaches, while the others led to decreased scores. This provides motivation for analysis and discussion of the individual approaches.
Anomaly Detection in Medical Imaging -- A Mini Review
Aug 25, 2021
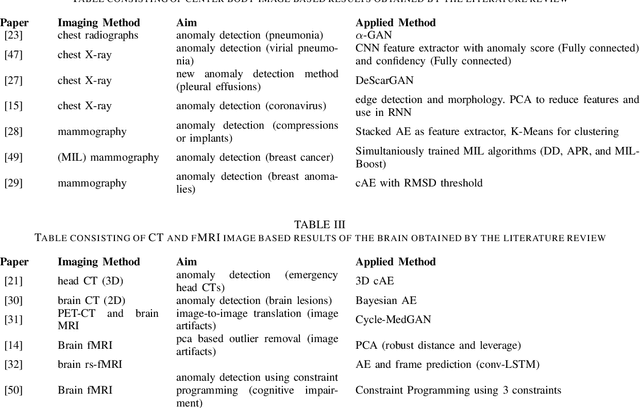
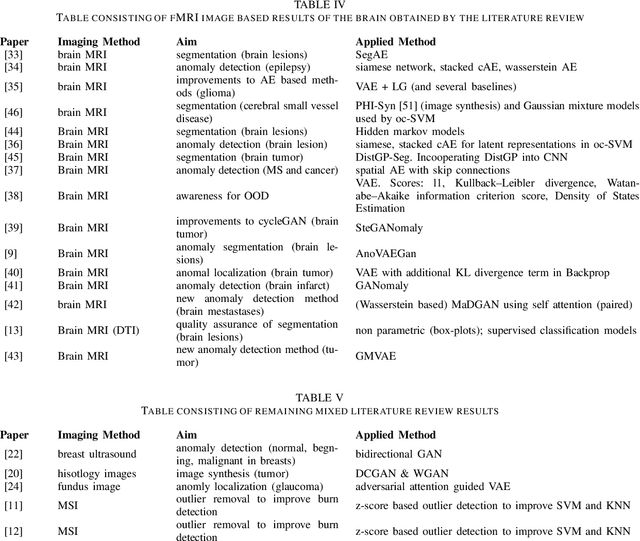
The increasing digitization of medical imaging enables machine learning based improvements in detecting, visualizing and segmenting lesions, easing the workload for medical experts. However, supervised machine learning requires reliable labelled data, which is is often difficult or impossible to collect or at least time consuming and thereby costly. Therefore methods requiring only partly labeled data (semi-supervised) or no labeling at all (unsupervised methods) have been applied more regularly. Anomaly detection is one possible methodology that is able to leverage semi-supervised and unsupervised methods to handle medical imaging tasks like classification and segmentation. This paper uses a semi-exhaustive literature review of relevant anomaly detection papers in medical imaging to cluster into applications, highlight important results, establish lessons learned and give further advice on how to approach anomaly detection in medical imaging. The qualitative analysis is based on google scholar and 4 different search terms, resulting in 120 different analysed papers. The main results showed that the current research is mostly motivated by reducing the need for labelled data. Also, the successful and substantial amount of research in the brain MRI domain shows the potential for applications in further domains like OCT and chest X-ray.