 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixUp-MIL: A Study on Linear & Multilinear Interpolation-Based Data Augmentation for Whole Slide Image Classification
Nov 06, 2023For classifying digital whole slide images in the absence of pixel level annotation, typically multiple instance learning methods are applied. Due to the generic applicability, such methods are currently of very high interest in the research community, however, the issue of data augmentation in this context is rarely explored. Here we investigate linear and multilinear interpolation between feature vectors, a data augmentation technique, which proved to be capable of improving the generalization performance classification networks and also for multiple instance learning. Experiments, however, have been performed on only two rather small data sets and one specific feature extraction approach so far and a strong dependence on the data set has been identified. Here we conduct a large study incorporating 10 different data set configurations, two different feature extraction approaches (supervised and self-supervised), stain normalization and two multiple instance learning architectures. The results showed an extraordinarily high variability in the effect of the method. We identified several interesting aspects to bring light into the darkness and identified novel promising fields of research.
MixUp-MIL: Novel Data Augmentation for Multiple Instance Learning and a Study on Thyroid Cancer Diagnosis
Nov 10, 2022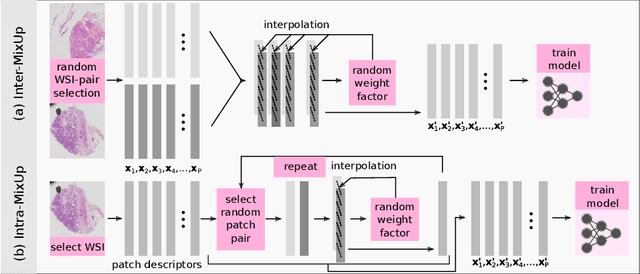
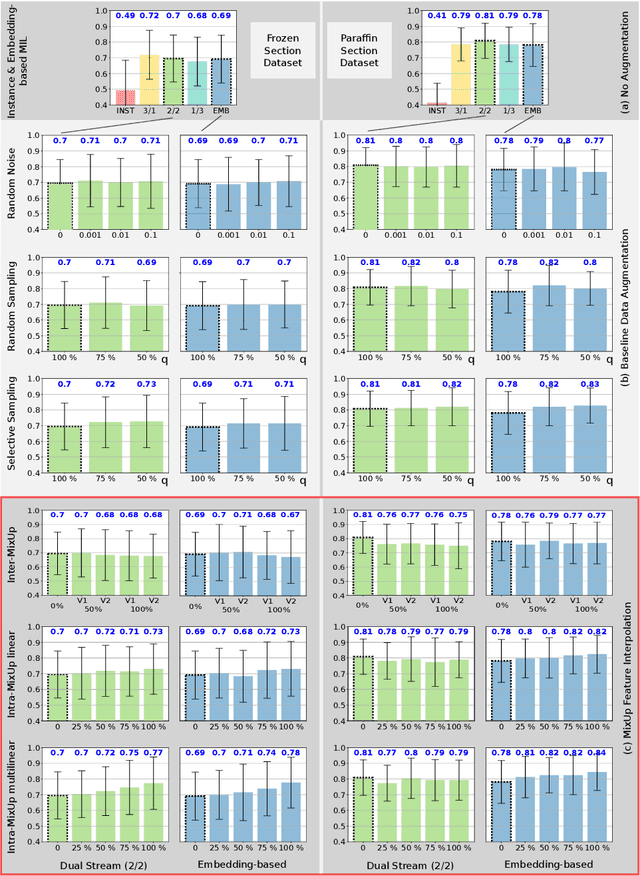
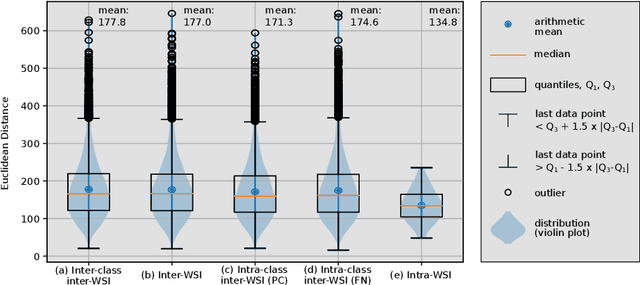
Multiple instance learning exhibits a powerful approach for whole slide image-based diagnosis in the absence of pixel- or patch-level annotations. In spite of the huge size of hole slide images, the number of individual slides is often rather small, leading to a small number of labeled samples. To improve training, we propose and investigate different data augmentation strategies for multiple instance learning based on the idea of linear interpolations of feature vectors (known as MixUp). Based on state-of-the-art multiple instance learning architectures and two thyroid cancer data sets, an exhaustive study is conducted considering a range of common data augmentation strategies. Whereas a strategy based on to the original MixUp approach showed decreases in accuracy, the use of a novel intra-slide interpolation method led to consistent increases in accuracy.
Frozen-to-Paraffin: Categorization of Histological Frozen Sections by the Aid of Paraffin Sections and Generative Adversarial Networks
Dec 15, 2020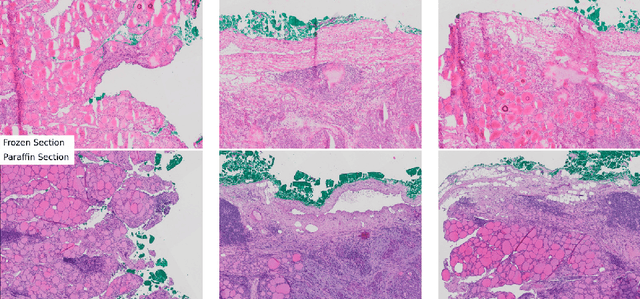
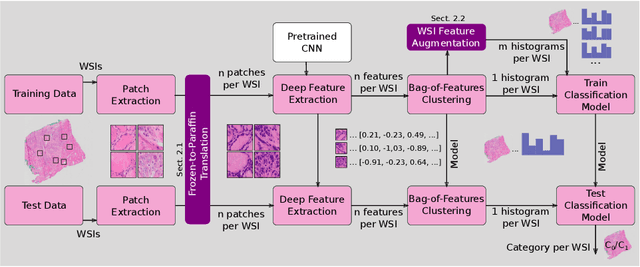
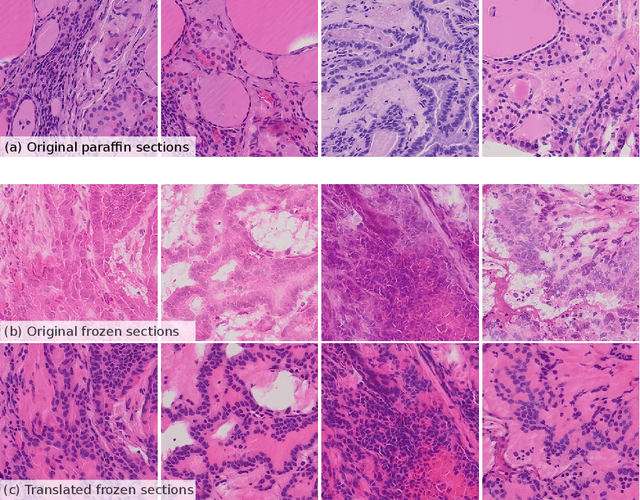
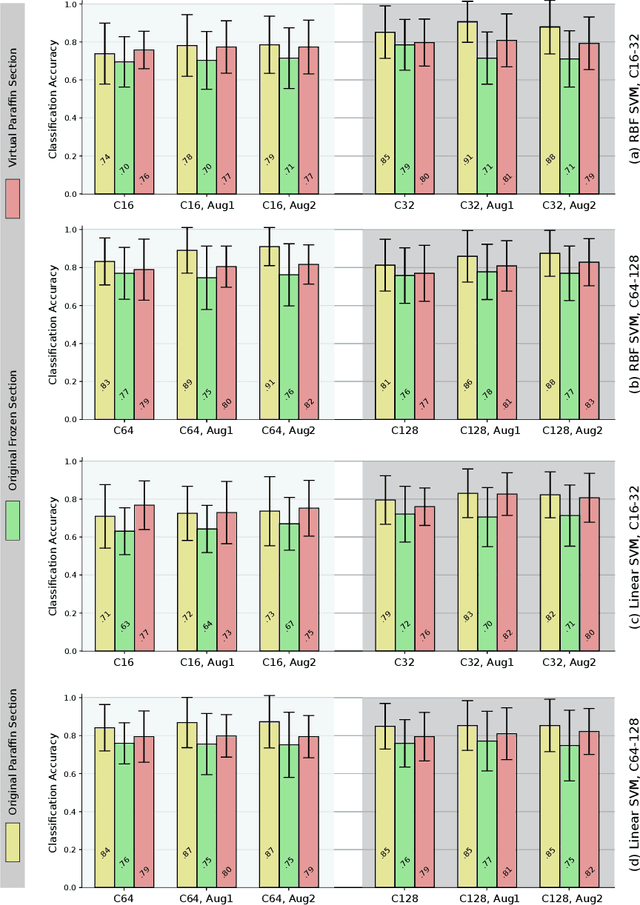
In contrast to paraffin sections, frozen sections can be quickly generated during surgical interventions. This procedure allows surgeons to wait for histological findings during the intervention to base intra-operative decisions on the outcome of the histology. However, compared to paraffin sections, the quality of frozen sections is typically lower, leading to a higher ratio of miss-classification. In this work, we investigated the effect of the section type on automated decision support approaches for classification of thyroid cancer. This was enabled by a data set consisting of pairs of sections for individual patients. Moreover, we investigated, whether a frozen-to-paraffin translation could help to optimize classification scores. Finally, we propose a specific data augmentation strategy to deal with a small amount of training data and to increase classification accuracy even further.