 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalsification-Based Robust Adversarial Reinforcement Learning
Paper and Code
Jul 17, 2020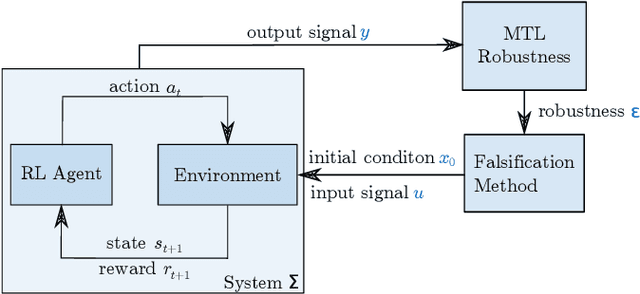

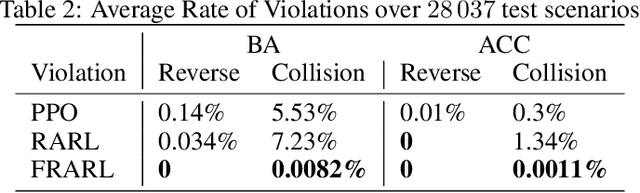
Reinforcement learning (RL) has achieved tremendous progress in solving various sequential decision-making problems, e.g., control tasks in robotics. However, RL methods often fail to generalize to safety-critical scenarios since policies are overfitted to training environments. Previously, robust adversarial reinforcement learning (RARL) was proposed to train an adversarial network that applies disturbances to a system, which improves robustness in test scenarios. A drawback of neural-network-based adversaries is that integrating system requirements without handcrafting sophisticated reward signals is difficult. Safety falsification methods allow one to find a set of initial conditions as well as an input sequence, such that the system violates a given property formulated in temporal logic. In this paper, we propose falsification-based RARL (FRARL), the first generic framework for integrating temporal-logic falsification in adversarial learning to improve policy robustness. With falsification method, we do not need to construct an extra reward function for the adversary. We evaluate our approach on a braking assistance system and an adaptive cruise control system of autonomous vehicles. Experiments show that policies trained with a falsification-based adversary generalize better and show less violation of the safety specification in test scenarios than the ones trained without an adversary or with an adversarial network.