 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Adversarial Examples by Input Transformations, Defense Perturbations, and Voting
Paper and Code
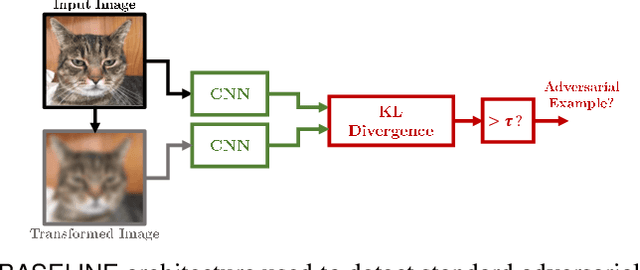
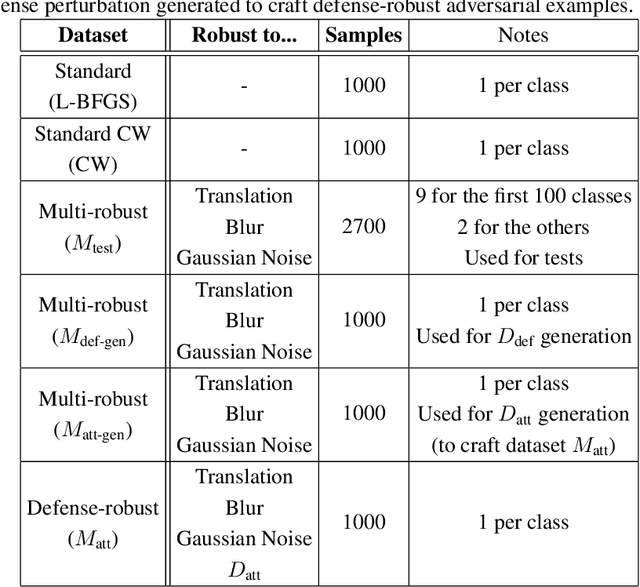
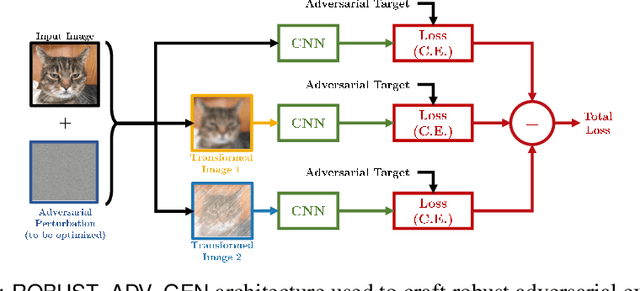
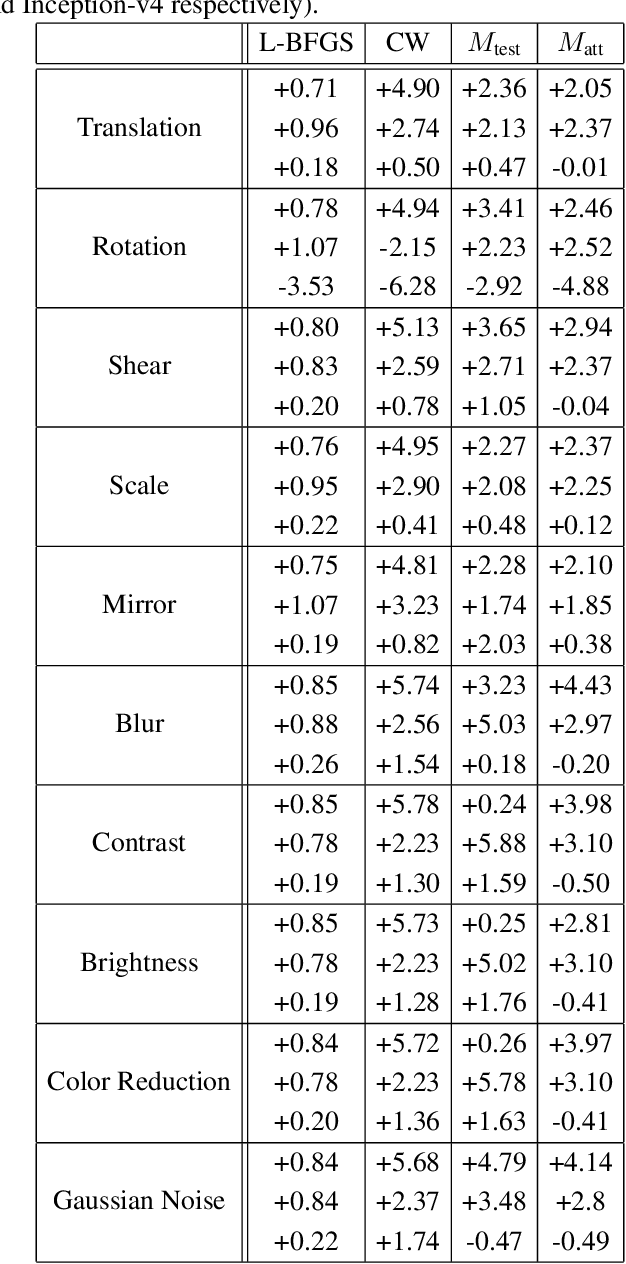
Over the last few years, convolutional neural networks (CNNs) have proved to reach super-human performance in visual recognition tasks. However, CNNs can easily be fooled by adversarial examples, i.e., maliciously-crafted images that force the networks to predict an incorrect output while being extremely similar to those for which a correct output is predicted. Regular adversarial examples are not robust to input image transformations, which can then be used to detect whether an adversarial example is presented to the network. Nevertheless, it is still possible to generate adversarial examples that are robust to such transformations. This paper extensively explores the detection of adversarial examples via image transformations and proposes a novel methodology, called \textit{defense perturbation}, to detect robust adversarial examples with the same input transformations the adversarial examples are robust to. Such a \textit{defense perturbation} is shown to be an effective counter-measure to robust adversarial examples. Furthermore, multi-network adversarial examples are introduced. This kind of adversarial examples can be used to simultaneously fool multiple networks, which is critical in systems that use network redundancy, such as those based on architectures with majority voting over multiple CNNs. An extensive set of experiments based on state-of-the-art CNNs trained on the Imagenet dataset is finally reported.