 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Imitation Learning in Sparse Reward Settings
Paper and Code



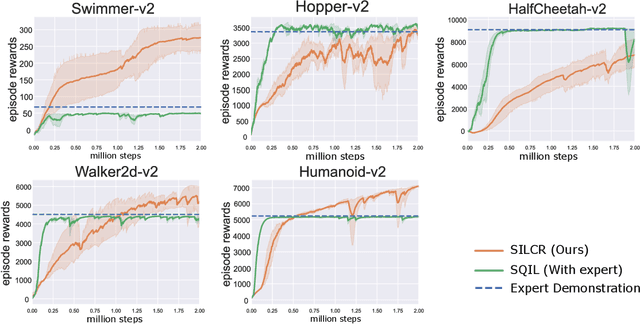
The application of reinforcement learning (RL) in real-world is still limited in the environments with sparse and delayed rewards. Self-imitation learning (SIL) is developed as an auxiliary component of RL to relieve the problem by encouraging the agents to imitate their historical best behaviors. In this paper, we propose a practical SIL algorithm named Self-Imitation Learning with Constant Reward (SILCR). Instead of requiring hand-defined immediate rewards from environments, our algorithm assigns the immediate rewards at each timestep with constant values according to their final episodic rewards. In this way, even if the dense rewards from environments are unavailable, every action taken by the agents would be guided properly. We demonstrate the effectiveness of our method in some challenging MuJoCo locomotion tasks and the results show that our method significantly outperforms the alternative methods in tasks with delayed and sparse rewards. Even compared with alternatives with dense rewards available, our method achieves competitive performance. The ablation experiments also show the stability and reproducibility of our method.