 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery SAM Drop Counts: Embracing Semantic Priors for Multi-Modality Image Fusion and Beyond
Mar 03, 2025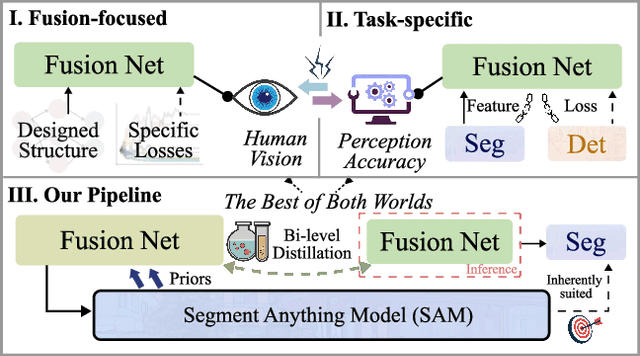
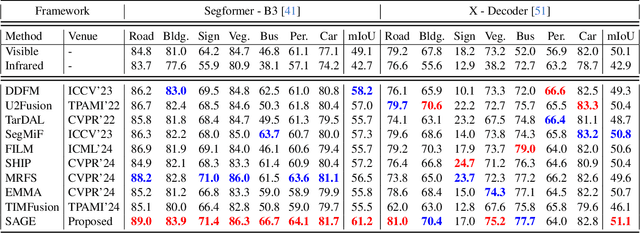

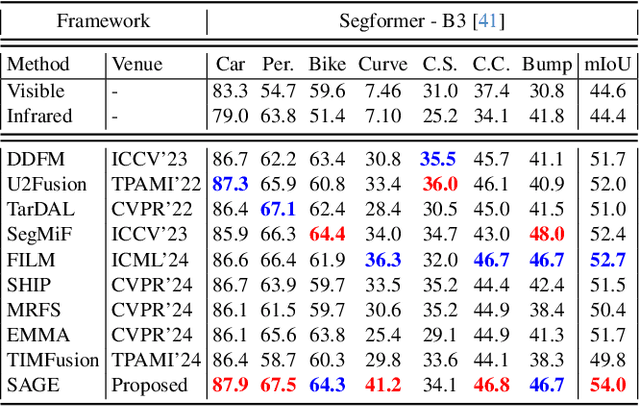
Multi-modality image fusion, particularly infrared and visible image fusion, plays a crucial role in integrating diverse modalities to enhance scene understanding. Early research primarily focused on visual quality, yet challenges remain in preserving fine details, making it difficult to adapt to subsequent tasks. Recent approaches have shifted towards task-specific design, but struggle to achieve the ``The Best of Both Worlds'' due to inconsistent optimization goals. To address these issues, we propose a novel method that leverages the semantic knowledge from the Segment Anything Model (SAM) to Grow the quality of fusion results and Establish downstream task adaptability, namely SAGE. Specifically, we design a Semantic Persistent Attention (SPA) Module that efficiently maintains source information via the persistent repository while extracting high-level semantic priors from SAM. More importantly, to eliminate the impractical dependence on SAM during inference, we introduce a bi-level optimization-driven distillation mechanism with triplet losses, which allow the student network to effectively extract knowledge at the feature, pixel, and contrastive semantic levels, thereby removing reliance on the cumbersome SAM model. Extensive experiments show that our method achieves a balance between high-quality visual results and downstream task adaptability while maintaining practical deployment efficiency.