 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoGrasp: World-Space Hand-Object Interaction Estimation from Egocentric Videos
Jan 03, 2026We propose EgoGrasp, the first method to reconstruct world-space hand-object interactions (W-HOI) from egocentric monocular videos with dynamic cameras in the wild. Accurate W-HOI reconstruction is critical for understanding human behavior and enabling applications in embodied intelligence and virtual reality. However, existing hand-object interactions (HOI) methods are limited to single images or camera coordinates, failing to model temporal dynamics or consistent global trajectories. Some recent approaches attempt world-space hand estimation but overlook object poses and HOI constraints. Their performance also suffers under severe camera motion and frequent occlusions common in egocentric in-the-wild videos. To address these challenges, we introduce a multi-stage framework with a robust pre-process pipeline built on newly developed spatial intelligence models, a whole-body HOI prior model based on decoupled diffusion models, and a multi-objective test-time optimization paradigm. Our HOI prior model is template-free and scalable to multiple objects. In experiments, we prove our method achieving state-of-the-art performance in W-HOI reconstruction.
Every SAM Drop Counts: Embracing Semantic Priors for Multi-Modality Image Fusion and Beyond
Mar 03, 2025
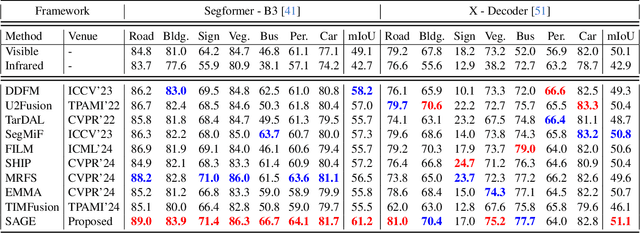

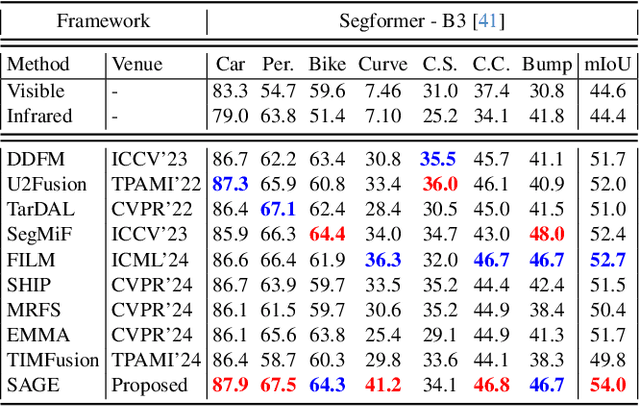
Multi-modality image fusion, particularly infrared and visible image fusion, plays a crucial role in integrating diverse modalities to enhance scene understanding. Early research primarily focused on visual quality, yet challenges remain in preserving fine details, making it difficult to adapt to subsequent tasks. Recent approaches have shifted towards task-specific design, but struggle to achieve the ``The Best of Both Worlds'' due to inconsistent optimization goals. To address these issues, we propose a novel method that leverages the semantic knowledge from the Segment Anything Model (SAM) to Grow the quality of fusion results and Establish downstream task adaptability, namely SAGE. Specifically, we design a Semantic Persistent Attention (SPA) Module that efficiently maintains source information via the persistent repository while extracting high-level semantic priors from SAM. More importantly, to eliminate the impractical dependence on SAM during inference, we introduce a bi-level optimization-driven distillation mechanism with triplet losses, which allow the student network to effectively extract knowledge at the feature, pixel, and contrastive semantic levels, thereby removing reliance on the cumbersome SAM model. Extensive experiments show that our method achieves a balance between high-quality visual results and downstream task adaptability while maintaining practical deployment efficiency.
Hybrid-Supervised Dual-Search: Leveraging Automatic Learning for Loss-free Multi-Exposure Image Fusion
Sep 03, 2023

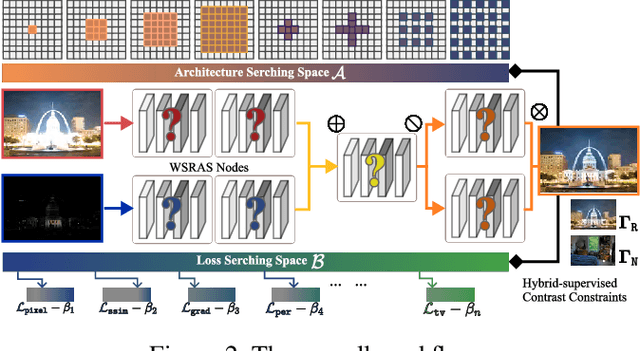
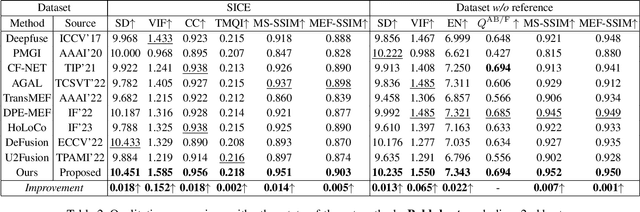
Multi-exposure image fusion (MEF) has emerged as a prominent solution to address the limitations of digital imaging in representing varied exposure levels. Despite its advancements, the field grapples with challenges, notably the reliance on manual designs for network structures and loss functions, and the constraints of utilizing simulated reference images as ground truths. Consequently, current methodologies often suffer from color distortions and exposure artifacts, further complicating the quest for authentic image representation. In addressing these challenges, this paper presents a Hybrid-Supervised Dual-Search approach for MEF, dubbed HSDS-MEF, which introduces a bi-level optimization search scheme for automatic design of both network structures and loss functions. More specifically, we harnesses a unique dual research mechanism rooted in a novel weighted structure refinement architecture search. Besides, a hybrid supervised contrast constraint seamlessly guides and integrates with searching process, facilitating a more adaptive and comprehensive search for optimal loss functions. We realize the state-of-the-art performance in comparison to various competitive schemes, yielding a 10.61% and 4.38% improvement in Visual Information Fidelity (VIF) for general and no-reference scenarios, respectively, while providing results with high contrast, rich details and colors.