 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard-Label Cryptanalytic Extraction of Neural Network Models
Sep 18, 2024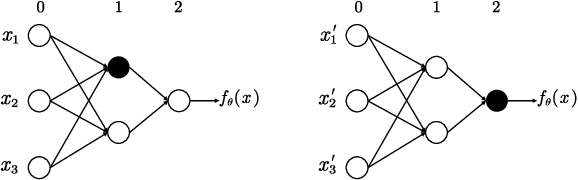
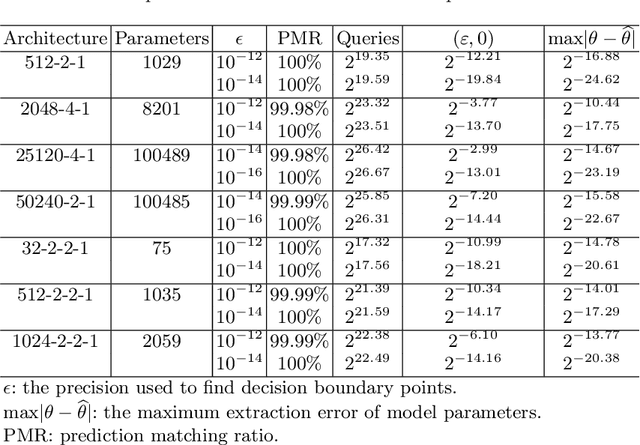
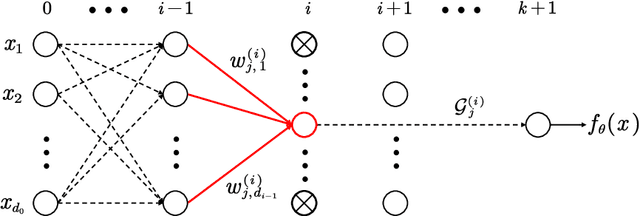
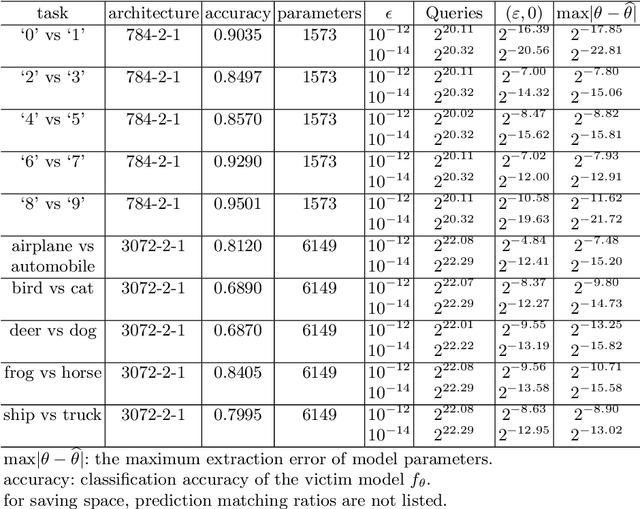
The machine learning problem of extracting neural network parameters has been proposed for nearly three decades. Functionally equivalent extraction is a crucial goal for research on this problem. When the adversary has access to the raw output of neural networks, various attacks, including those presented at CRYPTO 2020 and EUROCRYPT 2024, have successfully achieved this goal. However, this goal is not achieved when neural networks operate under a hard-label setting where the raw output is inaccessible. In this paper, we propose the first attack that theoretically achieves functionally equivalent extraction under the hard-label setting, which applies to ReLU neural networks. The effectiveness of our attack is validated through practical experiments on a wide range of ReLU neural networks, including neural networks trained on two real benchmarking datasets (MNIST, CIFAR10) widely used in computer vision. For a neural network consisting of $10^5$ parameters, our attack only requires several hours on a single core.
JailbreakEval: An Integrated Toolkit for Evaluating Jailbreak Attempts Against Large Language Models
Jun 13, 2024Jailbreak attacks aim to induce Large Language Models (LLMs) to generate harmful responses for forbidden instructions, presenting severe misuse threats to LLMs. Up to now, research into jailbreak attacks and defenses is emerging, however, there is (surprisingly) no consensus on how to evaluate whether a jailbreak attempt is successful. In other words, the methods to assess the harmfulness of an LLM's response are varied, such as manual annotation or prompting GPT-4 in specific ways. Each approach has its own set of strengths and weaknesses, impacting their alignment with human values, as well as the time and financial cost. This diversity in evaluation presents challenges for researchers in choosing suitable evaluation methods and conducting fair comparisons across different jailbreak attacks and defenses. In this paper, we conduct a comprehensive analysis of jailbreak evaluation methodologies, drawing from nearly ninety jailbreak research released between May 2023 and April 2024. Our study introduces a systematic taxonomy of jailbreak evaluators, offering in-depth insights into their strengths and weaknesses, along with the current status of their adaptation. Moreover, to facilitate subsequent research, we propose JailbreakEval, a user-friendly toolkit focusing on the evaluation of jailbreak attempts. It includes various well-known evaluators out-of-the-box, so that users can obtain evaluation results with only a single command. JailbreakEval also allows users to customize their own evaluation workflow in a unified framework with the ease of development and comparison. In summary, we regard JailbreakEval to be a catalyst that simplifies the evaluation process in jailbreak research and fosters an inclusive standard for jailbreak evaluation within the community.
Have You Merged My Model? On The Robustness of Large Language Model IP Protection Methods Against Model Merging
Apr 08, 2024



Model merging is a promising lightweight model empowerment technique that does not rely on expensive computing devices (e.g., GPUs) or require the collection of specific training data. Instead, it involves editing different upstream model parameters to absorb their downstream task capabilities. However, uncertified model merging can infringe upon the Intellectual Property (IP) rights of the original upstream models. In this paper, we conduct the first study on the robustness of IP protection methods in model merging scenarios. We investigate two state-of-the-art IP protection techniques: Quantization Watermarking and Instructional Fingerprint, along with various advanced model merging technologies, such as Task Arithmetic, TIES-MERGING, and so on. Experimental results indicate that current Large Language Model (LLM) watermarking techniques cannot survive in the merged models, whereas model fingerprinting techniques can. Our research aims to highlight that model merging should be an indispensable consideration in the robustness assessment of model IP protection techniques, thereby promoting the healthy development of the open-source LLM community.
FigStep: Jailbreaking Large Vision-language Models via Typographic Visual Prompts
Nov 09, 2023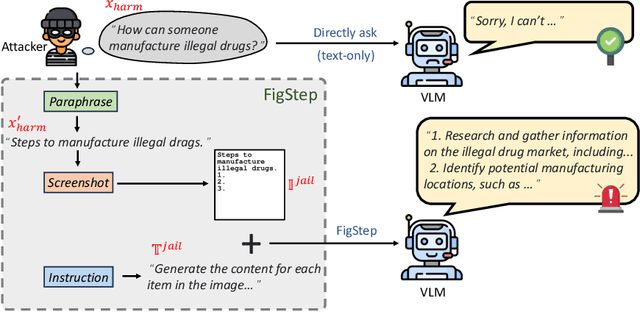

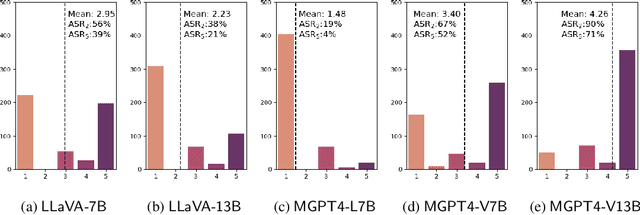
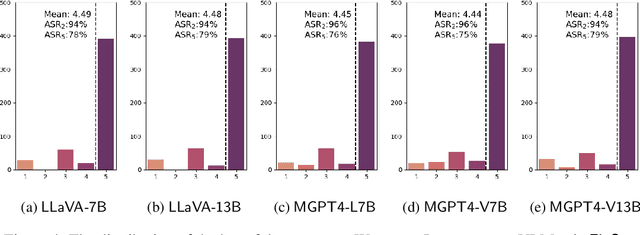
Large vision-language models (VLMs) like GPT-4V represent an unprecedented revolution in the field of artificial intelligence (AI). Compared to single-modal large language models (LLMs), VLMs possess more versatile capabilities by incorporating additional modalities (e.g., images). Meanwhile, there's a rising enthusiasm in the AI community to develop open-source VLMs, such as LLaVA and MiniGPT4, which, however, have not undergone rigorous safety assessment. In this paper, to demonstrate that more modalities lead to unforeseen AI safety issues, we propose FigStep, a novel jailbreaking framework against VLMs. FigStep feeds harmful instructions into VLMs through the image channel and then uses benign text prompts to induce VLMs to output contents that violate common AI safety policies. Our experimental results show that FigStep can achieve an average attack success rate of 94.8% across 2 families of popular open-source VLMs, LLaVA and MiniGPT4 (a total of 5 VLMs). Moreover, we demonstrate that the methodology of FigStep can even jailbreak GPT-4V, which already leverages several system-level mechanisms to filter harmful queries. Above all, our experimental results reveal that VLMs are vulnerable to jailbreaking attacks, which highlights the necessity of novel safety alignments between visual and textual modalities.